原文链接:http://tecdat.cn/?p=20424介绍
时间序列为预测未来数据提供了方法 。 根据先前的值 , 时间序列可用于预测经济 , 天气的趋势 。 时间序列数据的特定属性意味着通常需要专门的统计方法 。
在本教程中 , 我们将首先介绍和讨论自相关 , 平稳性和季节性的概念 , 然后继续应用最常用的时间序列预测方法之一 , 称为ARIMA 。
Python中可用的一种用于建模和预测时间序列的未来点的方法称为 SARIMAX , 它表示带有季节性回归的 季节性自回归综合移动平均线 。 在这里 , 我们将主要关注ARIMA , 用于拟合时间序列数据以更好地理解和预测时间序列中的未来点 。
为了充分利用本教程 , 熟悉时间序列和统计信息可能会有所帮助 。
在本教程中 , 我们将使用 Jupyter Notebook 处理数据 。
第1步-安装软件包 要设置我们的时间序列预测环境:
- cd environments
- . my_env/bin/activate
- mkdir ARIMA
- cd ARIMA
pip install pandas numpy statsmodels matplotlib
第2步-导入包并加载数据 要开始使用我们的数据 , 我们将启动Jupyter Notebook:
要创建新的笔记本文件 , 请 从右上方的下拉菜单中选择“ 新建” >“ Python 3 ”:
文章图片
首先导入所需的库:
- import warnings
- import itertools
- import pandas as pd
- import numpy as np
- import statsmodels.api as sm
- import matplotlib.pyplot as plt
- plt.style.use('fivethirtyeight')
y = data.data
让我们对数据进行一些预处理 。 每周数据处理起来比较麻烦 , 因为时间比较短 , 所以让我们使用每月平均值 。 我们还可以使用 fillna() 函数 来确保时间序列中没有缺失值 。
- # “ MS”字符串按月初将数据分组到存储中
- y = y['co2'].resample('MS').mean()
- # 填充缺失值
- y = y.fillna(y.bfill())
- Output
- co2
- 1958-03-01 316.100000
- 1958-04-01 317.200000
- 1958-05-01 317.433333
- ...
- 2001-11-01 369.375000
- 2001-12-01 371.020000
plt.show()
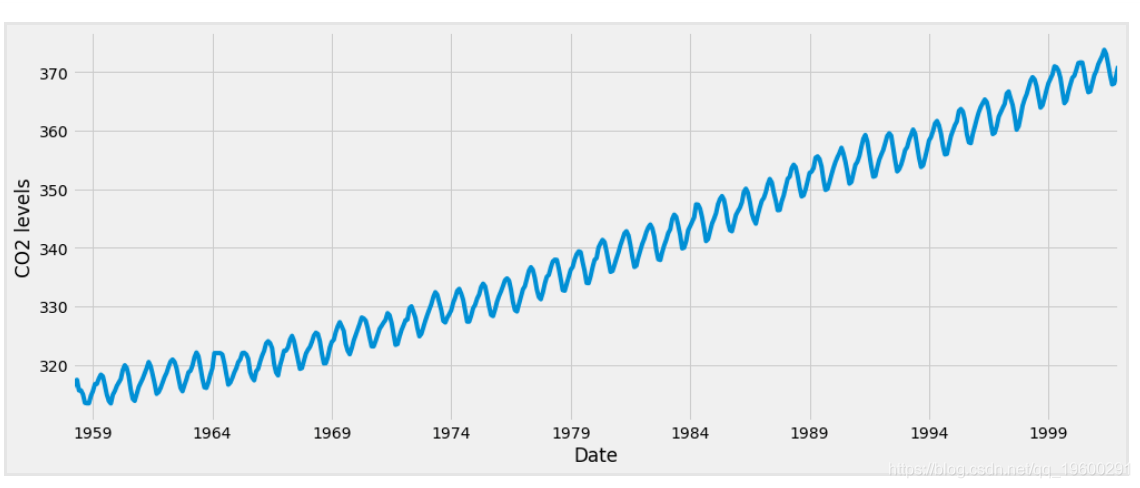
文章图片
当我们绘制数据时 , 可以发现时间序列具有明显的季节性模式 , 并且总体趋势呈上升趋势 。
现在 , 我们继续使用ARIMA进行时间序列预测 。
第3步-ARIMA时间序列模型 在时间序列预测中使用的最常见的方法是被称为ARIMA模型 。 ARIMA是可以拟合时间序列数据的模型 , 以便更好地理解或预测序列中的未来点 。
有三种不同的整数(p ,d ,q)是用来参数化ARIMA模型 。 因此 , ARIMA模型用符号表示 ARIMA(p, d, q) 。 这三个参数共同说明了数据集中的季节性 , 趋势和噪声:
- p 是模型的 自回归 部分 。 它使我们能够将过去值的影响纳入模型 。 从直觉上讲 , 这类似于声明如果过去三天天气一直温暖 , 明天可能会温暖 。
- d 是 模型的差分部分 。 包含了要应用于时间序列的差分量(即 , 要从当前值中减去的过去时间点的数量) 。 从直觉上讲 , 这类似于如果最近三天的温差很小 , 则明天的温度可能相同 。
- q 是 模型的 移动平均部分 。 这使我们可以将模型的误差设置为过去在先前时间点观察到的误差值的线性组合 。
在下一节中 , 我们将描述如何为季节性ARIMA时间序列模型自动识别最佳参数的过程 。
第4步-ARIMA时间序列模型的参数选择 当希望使用季节性ARIMA模型拟合时间序列数据时 , 我们的首要目标是找到ARIMA(p,d,q)(P,D,Q)s 可优化目标指标的值。 有许多准则和最佳实践可以实现此目标 , 但是ARIMA模型的正确参数化可能是艰苦的手动过程 , 需要领域专业知识和时间 。 其他统计编程语言(例如) R 提供 解决此问题的自动化方法 , 但这些方法尚未移植到Python 。 在本节中 , 我们将通过编写Python代码以编程方式选择ARIMA(p,d,q)(P,D,Q)s 时间序列模型的最佳参数值来解决此问题。
我们将使用“网格搜索”来迭代探索参数的不同组合 。 对于每种参数组合 , 我们使用 模块中的SARIMAX() 拟合新的季节性ARIMA模型 。 探索了整个参数范围 , 我们的最佳参数集便会成为产生最佳性能的一组参数 。 让我们首先生成我们要评估的各种参数组合:
- #定义p , d和q参数 , 使其取0到2之间的任何值
- p = d = q = range(0, 2)
- # 生成p、q和q三元组的所有不同组合
- pdq = list(itertools.product(p, d, q))
- # 生成所有不同的季节性p , q和q组合
- seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
- Output
- Examples of parameter combinations for Seasonal ARIMA...
- SARIMAX: (0, 0, 1) x (0, 0, 1, 12)
- SARIMAX: (0, 0, 1) x (0, 1, 0, 12)
- SARIMAX: (0, 1, 0) x (0, 1, 1, 12)
- SARIMAX: (0, 1, 0) x (1, 0, 0, 12)
在评估和比较不同参数的统计模型时 , 可以根据其拟合数据的程度或其准确预测未来数据点的能力来对每个模型进行排名 。 我们将使用 AIC (Akaike Information Criterion)值 , 该值可通过使用拟合的ARIMA模型方便地返回 statsmodels 。 AIC 在考虑模型整体复杂性的同时 ,测量模型拟合数据的程度 。 与使用较少特征以达到相同拟合优度的模型相比 , 在使用大量特征的模型将获得更大的AIC得分 。 因此 , 我们寻找产生最低AIC 的模型。
下面的代码块通过参数组合进行迭代 , 并使用中的 SARIMAX 函数 statsmodels 来拟合相应的Season ARIMA模型 。 拟合每个 SARIMAX()模型后 , 代码将输出出它们各自的 AIC 分数 。
- warnings.filterwarnings("ignore") # 指定忽略警告消息
- try:
- mod = sm.tsa.statespace.SARIMAX(y,
- order=param,
- seasonal_order=param_seasonal,
- enforce_stationarity=False,
- enforce_invertibility=False)
- Output
- SARIMAX(0, 0, 0)x(0, 0, 1, 12) - AIC:6787.3436240402125
- SARIMAX(0, 0, 0)x(0, 1, 1, 12) - AIC:1596.711172764114
- SARIMAX(0, 0, 0)x(1, 0, 0, 12) - AIC:1058.9388921320026
- SARIMAX(0, 0, 0)x(1, 0, 1, 12) - AIC:1056.2878315690562
- SARIMAX(0, 0, 0)x(1, 1, 0, 12) - AIC:1361.6578978064144
- SARIMAX(0, 0, 0)x(1, 1, 1, 12) - AIC:1044.7647912940095
- ...
- ...
- ...
- SARIMAX(1, 1, 1)x(1, 0, 0, 12) - AIC:576.8647112294245
- SARIMAX(1, 1, 1)x(1, 0, 1, 12) - AIC:327.9049123596742
- SARIMAX(1, 1, 1)x(1, 1, 0, 12) - AIC:444.12436865161305
- SARIMAX(1, 1, 1)x(1, 1, 1, 12) - AIC:277.7801413828764
步骤5 —拟合ARIMA时间序列模型 使用网格搜索 , 我们确定了一组参数 , 这些参数对我们的时间序列数据产生了最佳拟合模型 。 我们可以继续更深入地分析此模型 。
我们将从将最佳参数值插入新 SARIMAX 模型开始:
- results = mod.fit()
- Output
- ==============================================================================
- coef std err z P>|z| [0.025 0.975]
- ------------------------------------------------------------------------------
- ar.L1 0.3182 0.092 3.443 0.001 0.137 0.499
- ma.L1 -0.6255 0.077 -8.165 0.000 -0.776 -0.475
- ar.S.L12 0.0010 0.001 1.732 0.083 -0.000 0.002
- ma.S.L12 -0.8769 0.026 -33.811 0.000 -0.928 -0.826
- sigma2 0.0972 0.004 22.634 0.000 0.089 0.106
- ==============================================================================
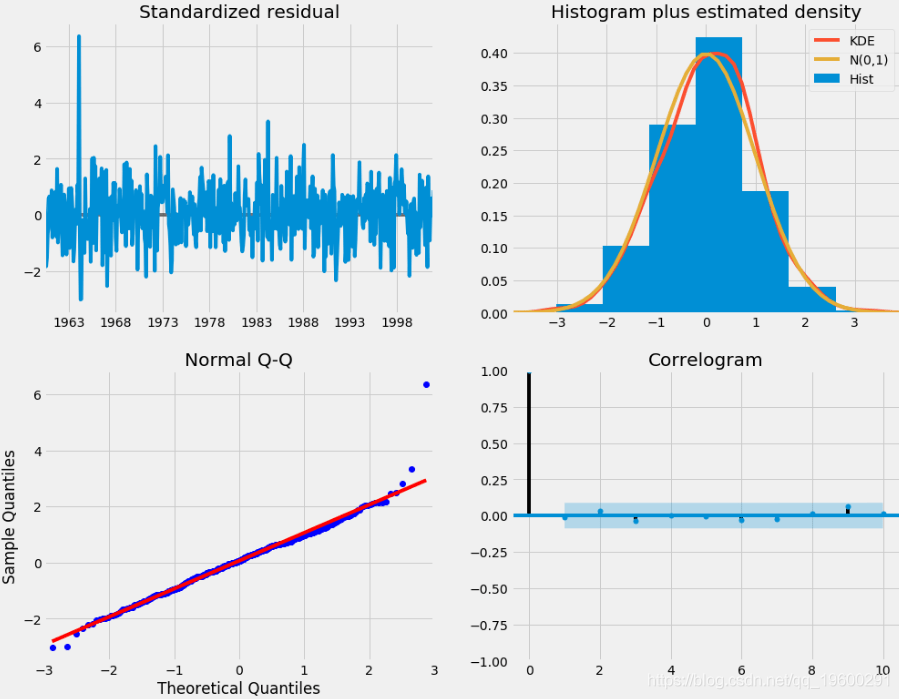
在拟合季节性ARIMA模型时 , 重要的是运行模型诊断程序 , 以确保没有违反模型所做的假设 。
plt.show()
文章图片
我们主要关心的是确保模型的残差不相关并且零均值正态分布 。 如果季节性ARIMA模型不满足这些属性 , 则表明它可以进一步改善 。
在这种情况下 , 我们的模型诊断建议根据以下内容正态分布模型残差:
- 在右上角的图中 , 我们看到红线 KDE 靠近 N(0,1) 红线 , (其中 N(0,1))是均值0 和标准偏差 为的正态分布 。 这很好地表明了残差呈正态分布 。
- 左下方的 qq图显示 , 残差(蓝色点)分布遵循从标准正态分布 。 同样 , 表明残差是正态分布的 。
- 随时间推移的残差(左上图)没有显示任何明显的季节性变化 , 而是白噪声 。 右下方的自相关(即相关图)图证实了这一点 , 该图表明时间序列残差有较低的相关性 。
尽管我们具有令人满意的拟合度 , 但可以更改季节性ARIMA模型的某些参数以改善模型拟合度 。 因此 , 如果扩大网格搜索范围 , 我们可能会找到更好的模型 。
第6步-验证预测 我们已经为时间序列获得了模型 , 现在可以将其用于产生预测 。 我们首先将预测值与时间序列的实际值进行比较 , 这将有助于我们了解预测的准确性 。
pred_ci = pred.conf_int()
上面的代码表示预测从1998年1月开始 。
我们可以绘制CO2时间序列的实际值和预测值 , 评估我们的效果 。
- ax.fill_between(pred_ci.index,
- pred_ci.iloc[:, 0],
- pred_ci.iloc[:, 1], color='k', alpha=.2)
- plt.show()
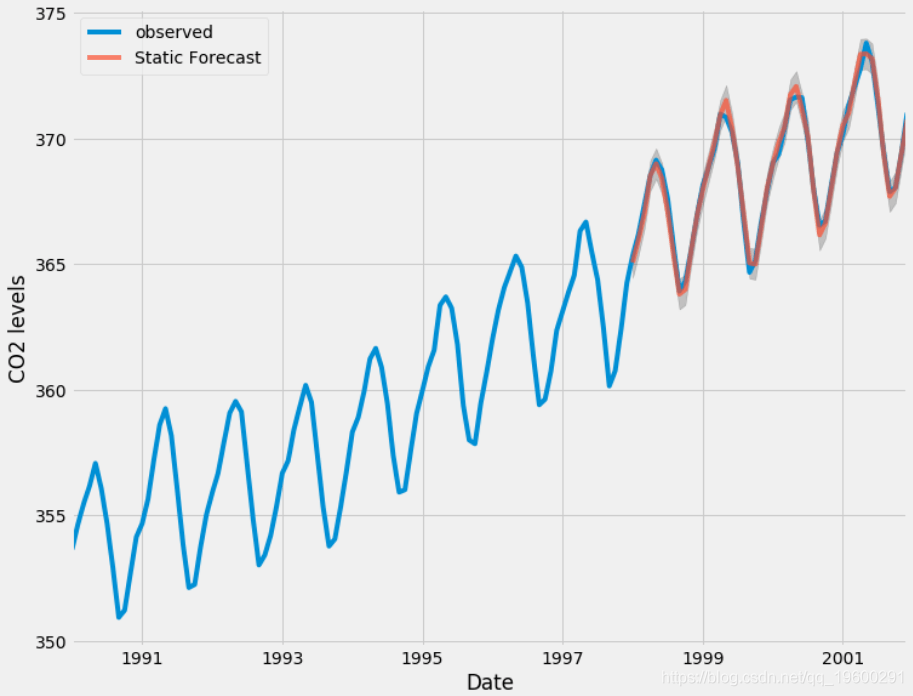
文章图片
总体而言 , 我们的预测与真实值非常吻合 , 显示出总体增长趋势 。
量化我们的预测准确性也很有用 。 我们将使用MSE(均方误差)来总结我们预测的平均误差 。 对于每个预测值 , 我们计算其与真实值的差异并将结果平方 。 对结果进行平方 , 在计算总体均值时正/负差不会互相抵消 。
- y_truth = y['1998-01-01':]
- # 计算均方误差
- mse = ((y_forecasted - y_truth) ** 2).mean()
- Output
- 我们的预测均方误差为 0.07
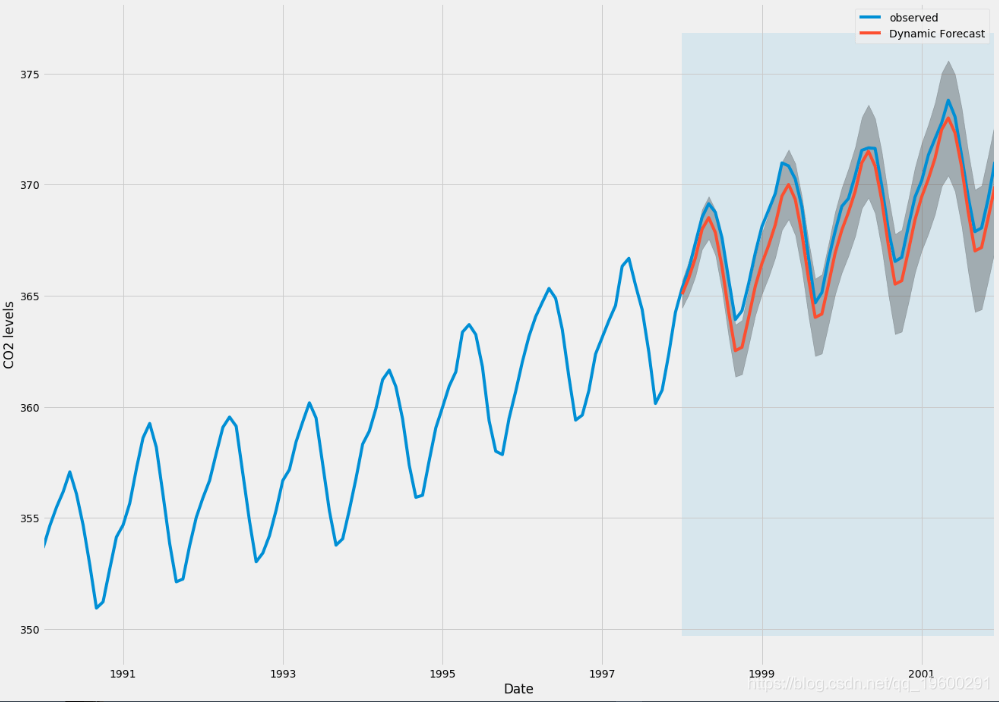
但是 , 使用动态预测可以更好地表示我们的真实预测能力 。 在这种情况下 , 我们仅使用时间序列中直到某个特定点的信息 , 之后 , 将使用以前的预测时间点中的值生成预测 。
在下面的代码块中 , 我们指定从1998年1月起开始计算动态预测和置信区间 。
通过绘制时间序列的观察值和预测值 , 我们可以看到 , 即使使用动态预测 , 总体预测也是准确的 。 所有预测值(红线)与真实情况(蓝线)非常接近 , 并且都在我们预测的置信区间内 。
我们再次通过计算MSE来量化预测的效果:
- # 提取时间序列的预测值和真实值
- y_forecasted = pred_dynamic.predicted_mean
- y_truth = y['1998-01-01':]
- # 计算均方误差
- mse = ((y_forecasted - y_truth) ** 2).mean()
- print('The Mean Squared Error of our forecasts is {}'.format(round(mse, 2)))
- Output
- 我们的预测均方误差为 1.01
提前一步和动态预测都确认此时间序列模型有效 。 但是 , 时间序列预测的兴趣在于能够提前预测未来值 。
第7步-生成和可视化预测 最后 , 我们描述了如何利用季节性ARIMA时间序列模型来预测未来数据 。
- # 获取未来500步的预测
- pred_uc = results.get_forecast(steps=500)
- # 获取预测的置信区间
- pred_ci = pred_uc.conf_int()
文章图片
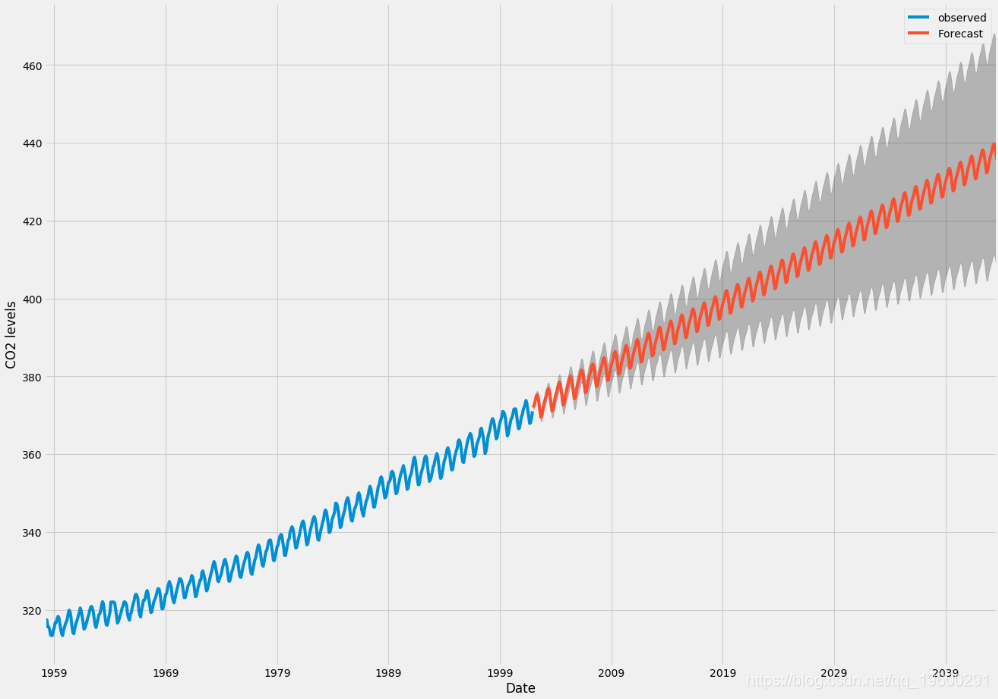
我们可以使用此代码的输出来绘制时间序列并预测其未来值 。
文章图片
现在 , 我们所生成的预测和相关的置信区间都可以用于进一步了解时间序列并预测预期结果 。 我们的预测表明 , 时间序列预计将继续稳定增长 。
随着我们对未来的进一步预测 , 置信区间会越来越大 。
结论 在本教程中 , 我们描述了如何在Python中实现季节性ARIMA模型 。 展示了如何进行模型诊断以及如何生成二氧化碳时间序列的预测 。
您可以尝试以下一些其他操作:
- 更改动态预测的开始日期 , 以了解这如何影响预测的整体质量 。
- 尝试更多的参数组合 , 以查看是否可以提高模型的拟合优度 。
- 选择其他指标选择最佳模型 。 例如 , 我们使用该 AIC 找到最佳模型 。

文章图片
最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析
3.使用r语言进行时间序列(arima , 指数平滑)分析
4.r语言多元copula-garch-模型时间序列预测
5.r语言copulas和金融时间序列案例
6.使用r语言随机波动模型sv处理时间序列中的随机波动
7.r语言时间序列tar阈值自回归模型
8.r语言k-shape时间序列聚类方法对股票价格时间序列聚类
【序列|拓端tecdat|ARIMA模型预测CO2浓度时间序列】9.python3用arima模型进行时间序列预测
推荐阅读







- 数据|聚焦解决 “卡脖子”问题 三六零旗下国家工程研究中心纳入新序列
- 安全|CPU上为什么没有标记序列号?这是为了保护你
- 序列|来了!气象大数据云平台正式业务运行
- 化学合成方法|将四字校训变成DNA序列进行存储读取
- 序列|史上最大血浆蛋白质组研究发布
- Merlion|Merlion:端到端的时间序列预测利器
- 疫情|新疆霍尔果斯:2例无症状感染者新冠病毒均属于德尔塔变异株 未发现高度同源的基因组序列
- 品种|分析三千多种水稻品种基因序列,中国科学家揭秘植物免疫机制
- 技术|力合科技旗下科研平台入选首批新序列国家工程研究中心
- 位点|西北大学孙士生教授团队建立位点特异性糖链序列测定新方法