机器之心原创
作者:于雷
「唯快不破」的自动驾驶 , 更要有数据智能的深思考与慢功夫 。「唯快不破」四个字 , 在当下的自动驾驶行业较量中 , 是一种战术 , 也需要极强的资源支撑 。 截至目前 , 毫末智行驾驶辅助产品已积累 100 万公里的真实数据 , 装车量也达到了 100 万辆 。 这家被比作「中国 Cruise」的公司 , 正在沿着预定路线快速前进 , 但仍在量产应用中遇到了新的挑战 。
9 月 28 日 , 与传统观念中发布会的「花哨感」不同 , 毫末智行第三期品牌日在一种「理工男」的氛围下进行 。 这场活动更像是一场技术干货分享会 , 市场情况和量产产品较少被提及 , 花了更多时间分享有关数据智能的新思考 。

文章图片
「我们发现了大量量产前想不到的情况 , 现实世界远远比我们想的复杂 。 」毫末智行 CEO 顾维灝表示 , 有许多问题在规模化量产后才会遇到 , 比如车端感知可能遗漏很多潜在的高价值场景 , 能否挖掘出更有价值的数据 , 将海量数据训练的比别人更快 , 将决定谁能占领自动驾驶制高点 。
虽然遇到许多诸如此类的意外 , 但毫末智行搭建的数据智能闭环 , 仍可解决这些问题 。
云 + 端架构选型 , 高效筛查有价值数据

文章图片
顾维灝曾表示:「想要真正训练出高普适性的自动驾驶系统 , 首先必须用更快速度收集到大量真实数据 , 其次必须有能力快速将数据用于算法训练 。 」
背靠长城汽车的量产优势 , 毫末智行能够从用户端获取足够多的原始数据 。 但而后的步骤更加重要 , 作为商业化技术 , 不但要有能力发现高价值数据、快速用于训练模型 , 同时还要保证这个过程足够经济 。
目前 , 毫末智行每天可产生几千万桢数据 , 如何找到对当前能力最有价值的数据 , 成为了能否高效训练模型的前提 。 毫末智行把找到有价值场景数据的行为叫做诊断 , 通过云 + 端上模型对照的方式 , 快速找到有价值数据 , 以此为核心优化现有模型 。
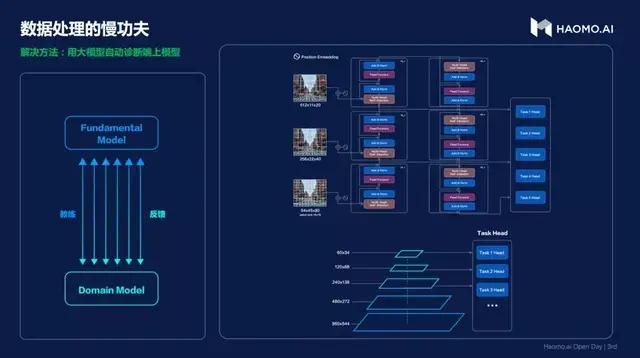
文章图片
毫末智行在云端和车端部署两个模型 , 云端模型叫做 Fundamental Model , 是一个基于 Transformer 的全任务感知大模型 。 车端的小模型是 Domain Model , 通过灰度测试的模式感知环境信息 , 但这种这种方式不够完备 , 可能导致很多潜在的高价值场景被遗漏 。
这些遗漏很多都是受到车端模型性能限制导致的误判 , 因此它们通常也意味着是车端模型的缺点 , 也是更高效训练模型的方向 。
推荐阅读







- 原神|《原神》「飞彩镌流年」2.4 版本预下载已开启
- 微信|积极落实互联互通,微信收款码支持云闪付及银行APP支付物料落地
- 年轻人|呼叫全城玩家,魔都首发「表情包地铁」启程,2022蓝不倒!
- 样儿|从太空看地球新年灯光秀啥样儿?快看!绝美风云卫星图来了
- 技术|使用云原生应用和开源技术的创新攻略
- 微信|微信支付“九宫格”全面支持开通中国银联云闪付
- 科技创新平台|云南:打造世界一流食用菌科技创新平台
- 雷军|和雷军一起开箱,领取小米12「专属指南」
- 广西云|1月1日生效的RCEP,将带来这些重大变化
- 平台|[原]蚂蚁集团SOFAStack:新一代分布式云PaaS平台,打造企业上云新体验