pcol|拓端数据tecdat|R语言主成分分析葡萄酒可视化:主成分得分散点图和载荷图
原文链接:http://tecdat.cn/?p=22492
原文出处:拓端数据部落公众号
我们将使用葡萄酒数据集进行主成分分析 。
数据
数据包含177个样本和13个变量的数据框;vintages包含类标签 。 这些数据是对生长在意大利同一地区但来自三个不同栽培品种的葡萄酒进行化学分析的结果:内比奥罗、巴贝拉和格里格诺葡萄 。 来自内比奥罗葡萄的葡萄酒被称为巴罗洛 。
这些数据包含在三种类型的葡萄酒中各自发现的几种成分的数量 。
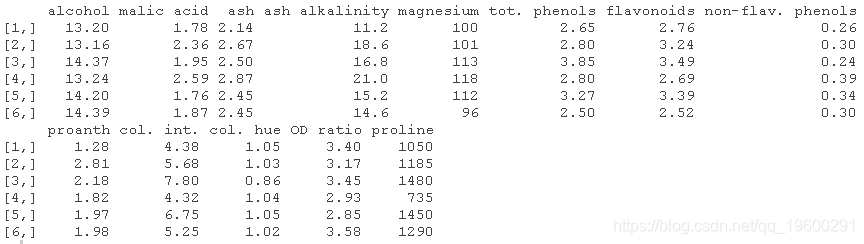
- # 看一下数据
- head(no)
文章图片
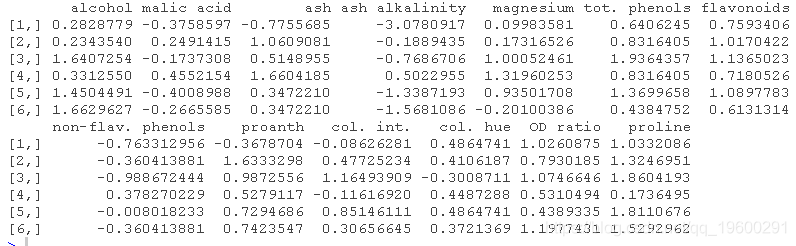
转换和标准化数据
对数转换和标准化 , 将所有变量设置在同一尺度上 。
- # 对数转换
- no_log <- log(no)
- # 标准化
- log_scale <- scale(no_log)
- head(log_scale)
文章图片
主成分分析(PCA)
使用奇异值分解算法进行主成分分析
- prcomp(log_scale, center=FALSE)
- summary(PCA)

文章图片
基本图形(默认设置)
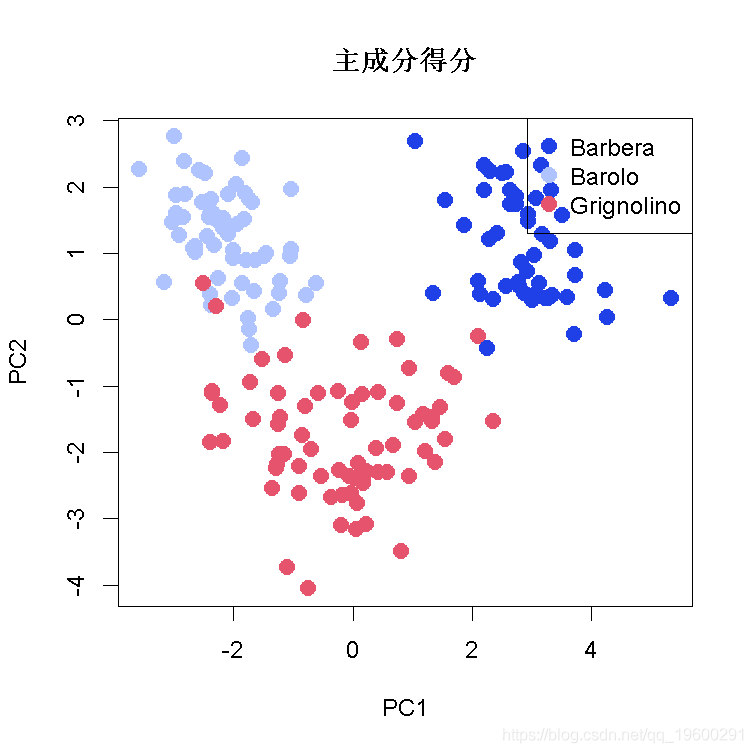
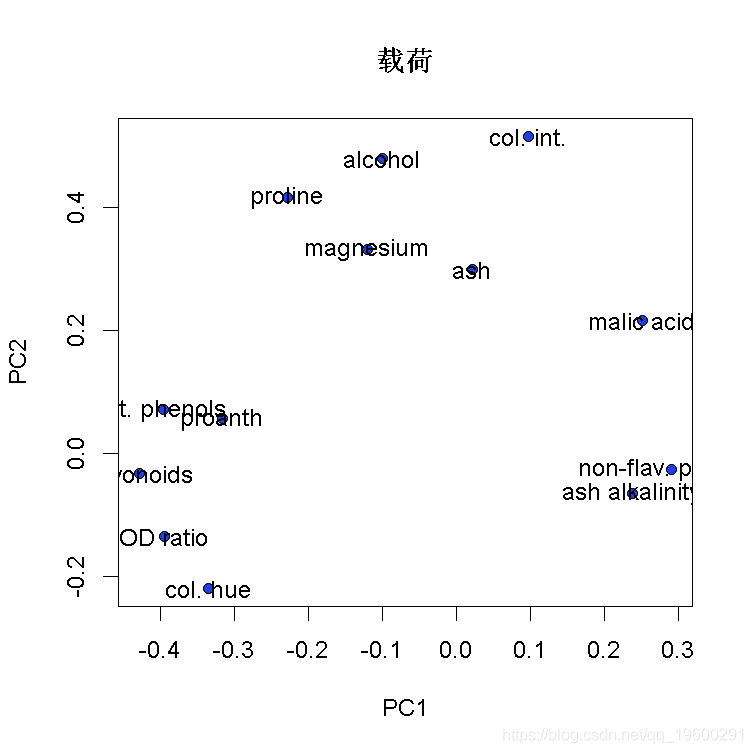
带有基础图形的主成分得分和载荷图
- plot(scores[,1:2], # x和y数据
- pch=21, # 点形状
- cex=1.5, # 点的大小
- legend("topright", # legend的位置
- legend=levels(vint), # 图例显示
- plot(loadings[,1:2], # x和y数据
- pch=21, # 点的形状
- text(loadings[,1:2], # 设置标签的位置
文章图片
文章图片
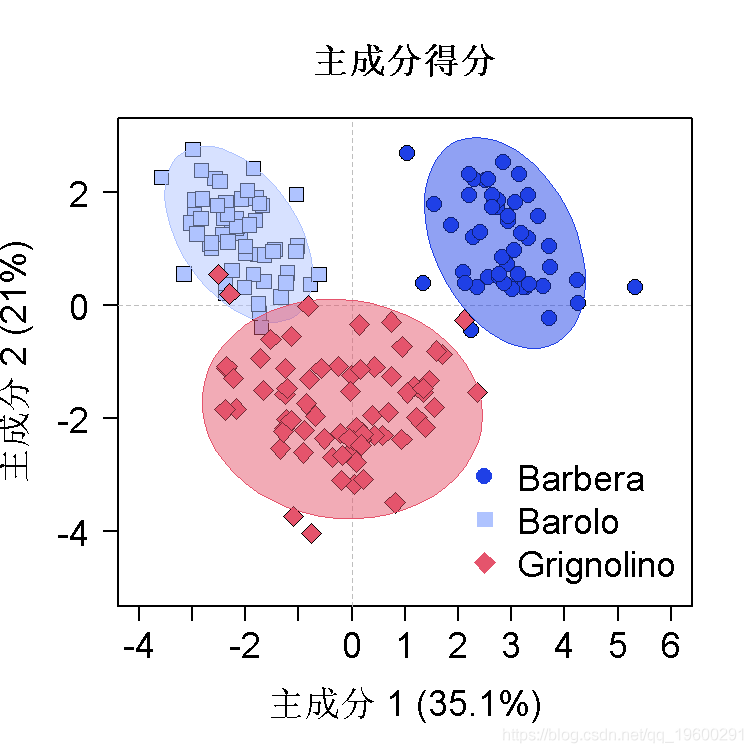
此外 , 我们还可以在分数图中的组别上添加95%的置信度椭圆 。
置信度椭圆图函数
- ## 椭圆曲线图
- elev=0.95, # 椭圆概率水平
- pcol=NULL, # 手工添加颜色 , 必须满足长度的因素
- cexsize=1, # 点大小
- ppch=21, # 点类型 , 必须满足因素的长度
- legcexsize=2, # 图例字体大小
- legptsize=2, # 图例点尺寸
- ## 设定因子水平
- if(is.factor(factr) {
- f <- factr
- } else {
- f <- factor(factr, levels=unique(as.character(factr)))
- }
- intfactr <- as.integer(f) # 设置与因子水平相匹配的整数向量
- ## 获取椭圆的数据
- edf <- data.frame(LV1 = x, LV2=y, factr = f) # 用数据和因子创建数据框
- ellipses <- dlply(edf, .(factr), function(x) {
- Ellipse(LV1, LV2, levels=elev, robust=TRUE, draw=FALSE) #从dataEllipse()函数中按因子水平获取置信度椭圆点
- })
- ## 获取X和Y数据的范围
- xrange <- plotat(range(c(as.vector(sapply(ellipses, function(x) x[,1])), min(x), max(x))))
- ## 为图块设置颜色
- if(is.null(pcol) != TRUE) { # 如果颜色是由用户提供的
- pgcol <- paste(pcol, "7e", sep="") # 增加不透明度
- # 绘图图形
- plot(x,y, type="n", xlab="", ylab="", main=""
- abline(h=0, v=0, col="gray", lty=2) #在0添加线条
- legpch <- c() # 收集图例数据的矢量
- legcol <- c() # 收集图例col数据的向量
- ## 添加点、椭圆 , 并确定图例的颜色
- ## 图例
- legend(x=legpos, legend=levels(f), pch=legpch,
- ## 使用prcomp()函数的PCA输出的轴图示
- pcavar <- round((sdev^2)/sum((sdev^2))
绘制主成分得分图 , 使用基本默认值绘制载荷图
- plot(scores[,1], # X轴的数据
- scores[,2], # Y轴的数据
- vint, # 有类的因素
- pcol=c(), # 用于绘图的颜色(必须与因素的数量相匹配)
- pbgcol=FALSE, #点的边框是黑色的?
- cexsize=1.5, # 点的大小
- ppch=c(21:23), # 点的形状(必须与因子的数量相匹配)
- legpos="bottom right", # 图例的位置
- legcexsize=1.5, # 图例文字大小
- legptsize=1.5, # 图例点的大小
- axissize=1.5, # 设置轴的文字大小
- linewidth=1.5 # 设置轴线尺寸
- )
- title(xlab=explain[["PC1"]], # PC1上解释的方差百分比
- ylab=explain[["PC2"]], # PC2解释的方差百分比
- main="Scores", # 标题
- cex.lab=1.5, # 标签文字的大小
- cex.main=1.5 # 标题文字的大小
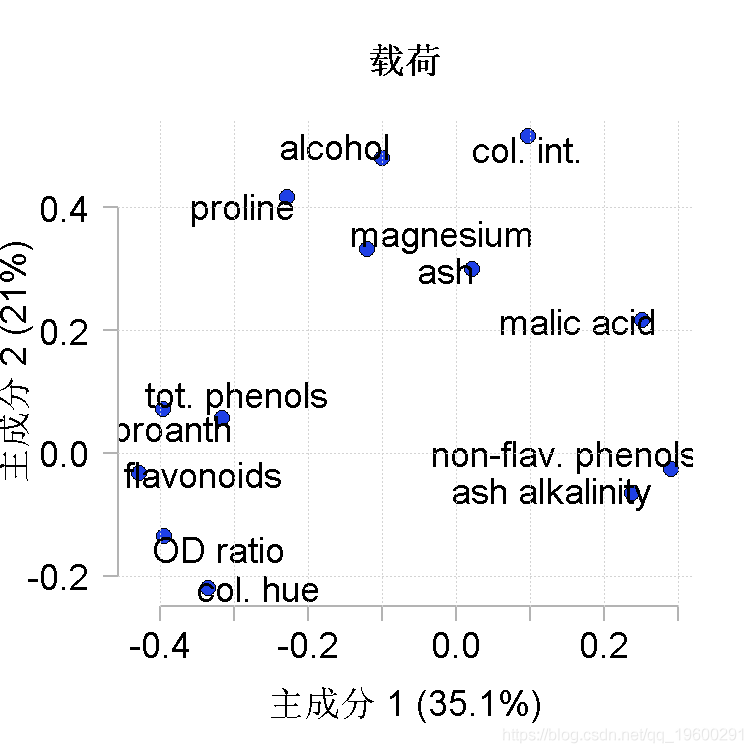
- plot(loadings[,1:2], # x和y数据
- pch=21, # 点的形状
- cex=1.5, # 点的大小
- # type="n", # 不绘制点数
- axes=FALSE, # 不打印坐标轴
- xlab="", # 删除x标签
- ylab="" # 删除y标签
- )
- pointLabel(loadings[,1:2], #设置标签的位置
- labels=rownames(PCAloadings), # 输出标签
- cex=1.5 # 设置标签的大小
- ) # pointLabel将尝试将文本放在点的周围
- axis(1, # 显示x轴
- cex.axis=1.5, # 设置文本的大小
- lwd=1.5 # 设置轴线的大小
- )
- axis(2, # 显示y轴
- las=2, # 参数设置文本的方向 , 2是垂直的
- cex.axis=1.5, # 设置文本的大小
- lwd=1.5 # 设置轴线的大小
- )
- title(xlab=explain[["PC1"]], # PC1所解释的方差百分比
- ylab=explain[["PC2"]], # PC2解释的方差百分比
- cex.lab=1.5, # 标签文字的大小
- cex.main=1.5 # 标题文字的大小
- )
文章图片
文章图片

文章图片
最受欢迎的见解
1.matlab偏最小二乘回归(PLSR)和主成分回归(PCR)
2.R语言高维数据的主成分pca、 t-SNE算法降维与可视化分析
3.主成分分析(PCA)基本原理及分析实例
4.基于R语言实现LASSO回归分析
5.使用LASSO回归预测股票收益数据分析
6.r语言中对lasso回归 , ridge岭回归和elastic-net模型
7.r语言中的偏最小二乘回归pls-da数据分析
8.r语言中的偏最小二乘pls回归算法
【pcol|拓端数据tecdat|R语言主成分分析葡萄酒可视化:主成分得分散点图和载荷图】9.R语言线性判别分析(LDA) , 二次判别分析(QDA)和正则判别分析(RDA)
推荐阅读



- 区块|面向2030:影响数据存储产业的十大应用(下):新兴应用
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 数据|数智安防时代 东芝硬盘助力智慧安防新赛道
- 平台|数梦工场助力北京市中小企业公共服务平台用数据驱动业务创新
- 数据|中标 | 数梦工场以数字新动能助力科技优鄂
- 建设|数据赋能业务,数梦工场助力湖北省智慧应急“十四五”开局
- 市民|大数据、人工智能带来城市新变化 科技赋能深化文明成效
- 趋势|[转]从“智能湖仓”升级看数据平台架构未来方向
- 数据|天问一号火星离子与中性粒子分析仪首个成果面世