机器之心报道
机器之心编辑部
卷积和自注意力各有优势 , 但二者的有效结合一直是一大难题 。 为了取二者之长 , 上海交大 - 华为海思联合团队提出了一种名为 X-volution 的新型算子 。 该算子在性能上的显著提升、计算的通用性与即插即用的特性为深度学习基础计算单元库以及 NPU 计算架构的演进提供了一种新的基础武器 。众所周知 , 卷积操作(convolution)与自注意力操作(self-attention)是深度学习两大核心的基础网络计算单元(或称为模型算子) 。 卷积操作通过线性乘子 , 提取图像局部特征;自注意力操作通过高阶乘子运算 , 提取图像全域 / 局部的特征关联特性 。 两种算子成为深度学习两大重要网络架构演化——CNN 与 Transformer 的计算基石 。 两种算子在图像特征提取与语义抽象方面的互补性不言而喻:线性 vs. 高阶 ,局部 vs. 全局 。 因此 , 能否设计一种包含这两种操作的融合算子并使其发挥互补优势 , 一直是深度学习架构研究者热衷的研究方向之一 。
然而 , 由于卷积运算与自注意力运算在计算模式上的异构性 , 这项任务存在巨大的挑战 。 目前学界中的一些工作也在努力统一两者 , 他们主要从拓扑结构组合角度来粗粒度地结合两种算子 , 例如 , 发表在 ICCV 2019 上的 AA-Net 采用了一种将卷积中部分通道替换为由 self-attention 来处理 , 然后将卷积和 self-attention 分别处理的特征连接来达到联合两种算子的目的 , 这种做法证明了卷积和 self-attention 结合后确实能在分类、检测、分割等基础任务上达到比较可观的性能收益 。
然而 , 粗粒度的组合(本质上就是两路计算并联)会导致其组合后网络形态可用性下降 。 具体来说 , 卷积和 self-attention 运算模式存在较大差异 , 两者同时存在会导致网络结构不规则 , 进而影响网络推理效率 , 并不为目前一些工业界通用的芯片计算架构所友好支持 。 同时组合后的算子在算力上也存在巨大的挑战 。

文章图片
论文链接:
https://arxiv.org/pdf/2106.02253.pdf
针对这些挑战 , 日前 , 上海交大 - 华为海思联合团队在 arXiv 上发表了「X-volution: On the Unification of Convolution and Self-attention」 , 首次在计算模式上统一了这两大基础算子 , 并在推理阶段归并成一个简单的卷积型算子:X-volution 。
X-volution 兼顾卷积与自注意力操作的互补优势 , 并且在现有通用网络计算框架上不需要额外算子支持 , 也不增加除卷积外的额外算力或影响网络的规范性 / 可用性(即插即用) 。
该工作的突破主要受以下思路的启发:对全局的 self-attention 进行理论分析后 , 研究者发现在一定条件下(例如图像 / 特征图的邻接像素满足马尔可夫性质) , 全局的 self-attention 可以通过局部的 self-attention 配合卷积运算来逼近 。
具体来说 , 本文作者提出了一种新型的 self-attention 机制——PSSA 。 这种机制分为两个步骤:首先将输入的特征沿指定的多个方向进行循环移位(采用索引来实现)得到移位后的特征 , 然后将移位后的特征与原特征通过元素点积获得变换后的特征 , 再对该特征在局部区域进行加权求和(可采用卷积来替代) , 至此获得经过注意力机制处理后的特征 。 通过层次堆叠 , 可以持续地将局部的上下文关系传播到全局从而实现全局的 self-attention 。
值得注意的是 , PSSA 实际上将 self-attention 巧妙地转化为了一个在简单变换后的特征上的标准的卷积操作 , 这从形式上实现了 self-attention 向卷积的统一 。 利用此逼近式的 self-attention 机制 , 作者建立了一个多分枝的模块将卷积和 self-attention 整合在一起 , 这个模块从功能上实现了两者的统一 。
更重要的是 , 这个多分枝的结构可以利用结构重参数化的方法进行有条件的合并 。 多分枝结构可以合并为单个卷积 , 合并后可以获得一个原子级的算子 , 称为 X-volution(X-volution 的权重可以看作一个静态卷积权重 , 以及一个内容相关动态卷积权重的和) 。 此算子同时具备了卷积和 self-attention 的特性 , 且不会影响网络的规范性 / 可用性 。
作者在分类、检测、分割等主流 SOTA 实验上取得了显著的性能提升 。
图 1 , 算子详细结构框图 。 受结构重参数化思想启发 , X-volution 被设计为训练和推理阶段结构解耦的形式 。 它的训练结构时有两个主要分支(如中间所示) , 右分支由级联的卷积和 BN 构成 , 可为 X-volution 集成卷积的能力 。 左边包括 PSSA , 它提供近似的全局自注意力特性 。 完成训练后 , X-volution 可以有条件地重新参数化为一个卷积操作 。 在推理阶段 , X-volution 实际上是一个动态卷积算子 , 它的权重包括需要在线计算的 attention 动态参数部分和已经训练和固化的卷积静态参数部分 。
实验部分
作者将 X-volution 接入到经典的 ResNet 模型中用于 ImageNet 分类、MS COCO 物体检测、实例分割等关键基础任务并都取得了不俗的提升 。 为了排除其他因素干扰 , 实验中作者所使用的 self-attention 和 PSSA 都没有添加位置编码 , 并且没有对数据集进行额外的增广 , 没有使用额外的训练技巧(如:余弦退火、标签平滑等) 。
ImageNet 分类实验
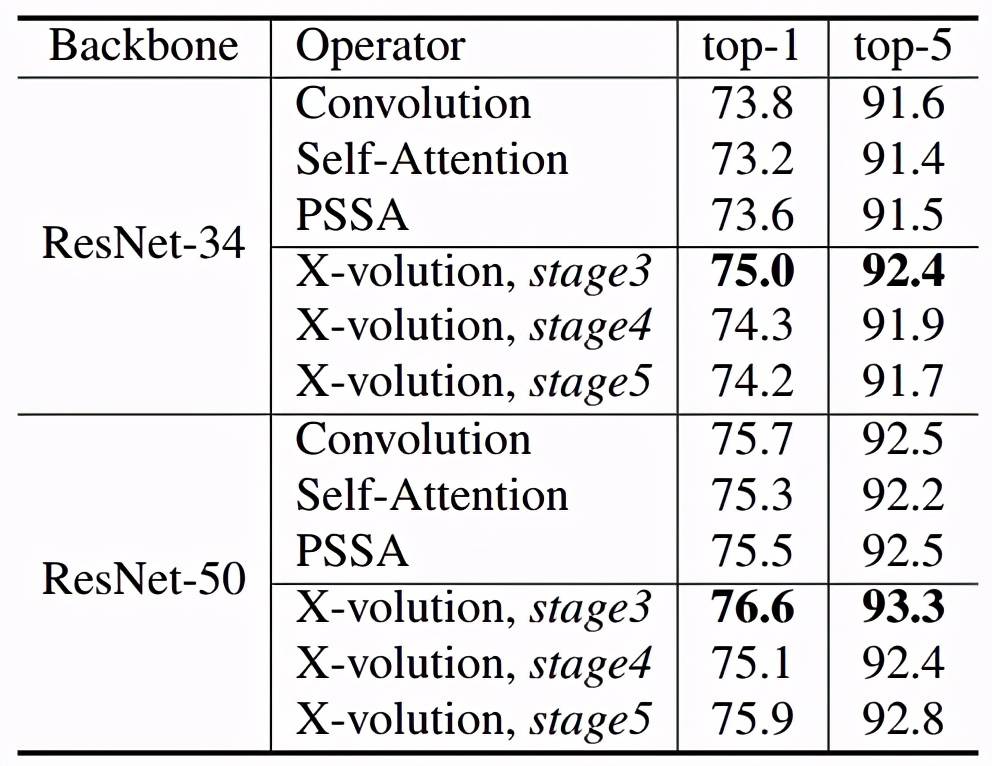
对于 ImageNet 图片分类实验 , 作者分别测试了在 ResNet 中三个不同位置接入 X-volution 的结果 。 将 X-volution 接入到常规的 ResNet 第五阶段瓶颈单元的结果如表 1 所示:在 ResNet-34 与 ResNet-50 中均提升不明显 , 这是因为在此阶段的特征图尺寸已经接近卷积核大小 。 实验发现在第三阶段效果最为突出 , 分别取得了 1.2% 与 0.9% 的显著提升 。 值得注意的是 , 作者对于 ResNet 改动较小 , 但是性能却依然能有大幅度的提升 , 这证实了文中所提出的 X-volution 算子具有良好的性能 。
【特征|上海交大、华为海思提出X-volution,发力网络核心基础架构创新】
文章图片
文章图片
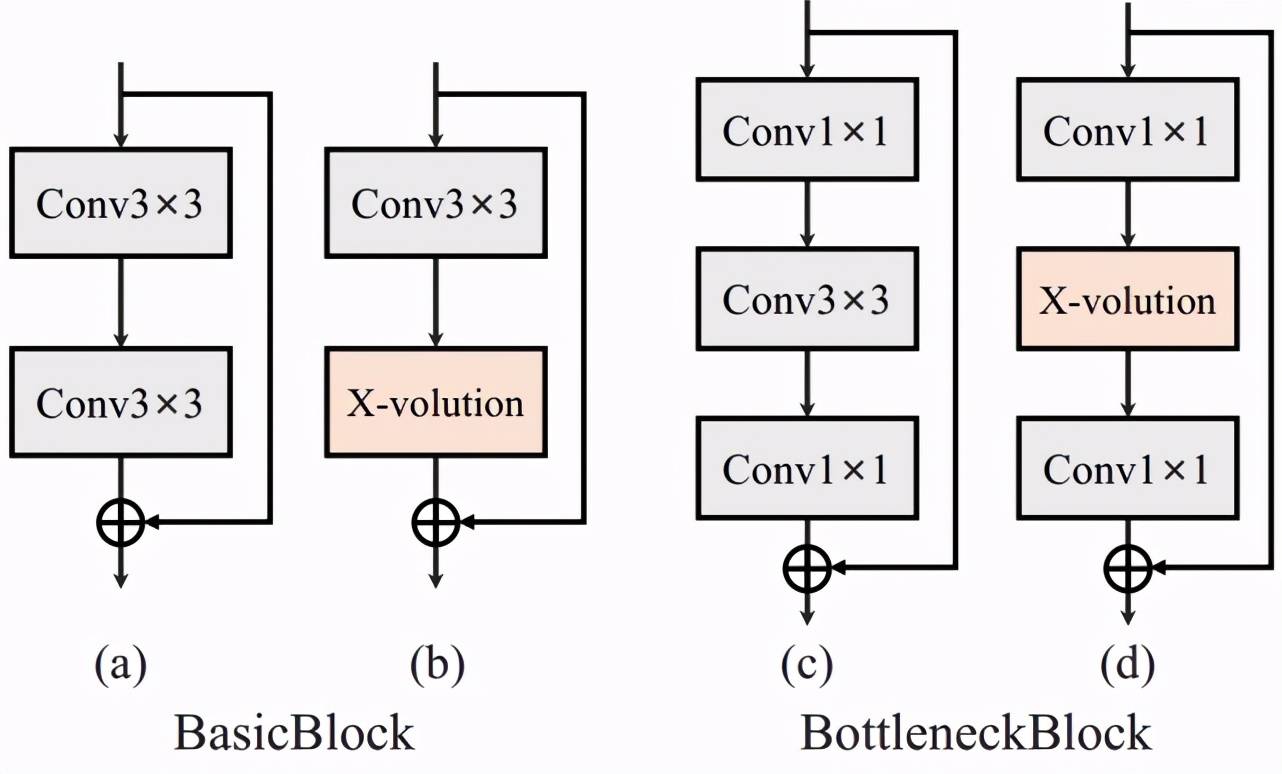
表 1. ImageNet 实验结果及瓶颈单元详细结构
MS COCO 物体检测及实例分割实验
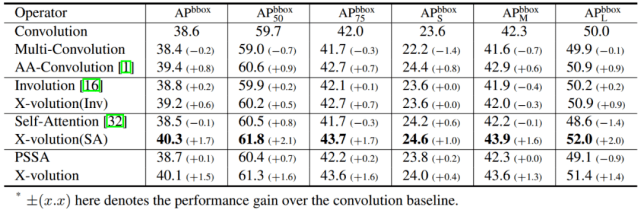
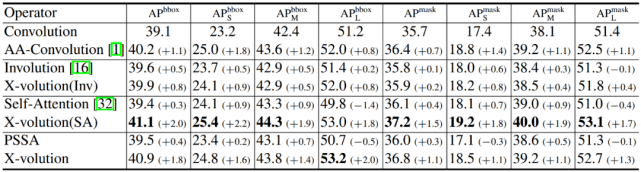
作者进一步在更复杂的目标检测和实例分割上验证所提出的算子的有效性 。 他们的实验模型是用 X-volution 增强的 ResNet-50 , 具体是替换了 ResNet-50 最后一个阶段的三个瓶颈单元 。 为了充分的对比 , 作者展示了两种形态的 X-volution , 如表 2 和表 3 所示:X-volution(SA) 表示的是卷积与 global self-attention 结合 , 这种形态是为了验证 X-volution 采用的卷积和 self-attention 结合模式的可行性;X-volution 则表示卷积和 PSSA 直接结合的形式 , 其为了检验所提出的 PSSA 的可行性 。
文章图片
表 2:MS COCO 物体检测实验结果
文章图片
表 3:MS COCO 实例分割实验结果
从表 2 与表 3 可以看出 , 两种 X-volution 模式都获得了大幅度的性能提升 。 其中 , X-volution(SA) 更为明显 , 这说明卷积和 self-attention 的互补对性能提升具有重大意义 。 而采用 PSSA 的 X-volution 性能也非常不俗 , 基本与 self-attention 性能相当 , 这也验证了采用 PSSA 逼近 self-attention 是有效且合理的 。
消融实验
最后 , 作者详细研究了卷积部分和 self-attention 部分对于算子性能的影响 。 他们改变卷积部分的滤波核的尺寸大小 , 其性能变化结果如图 2(a) 。 可以看到当卷积核设置为 1 时候 , 单纯的卷积算子性能退化非常严重 , 而此时的 X-volution 依然能取得 39.1 的平均准确率 。 当卷积核逐步增大后 , 纯卷积的网络性能先升后降 , 而对应的 X-volution 算子也呈同样趋势 , 但一直保持着对于单纯卷积的性能优势 。 其中 , 当卷积核为 7 时候性能最好 。 从这个结果可以得知 , 卷积在两者间起到了较大的作用 , 这一点也与 AA-Net 结论相同 。 由于学习参数较多 , 卷积的作用也比较突出 。
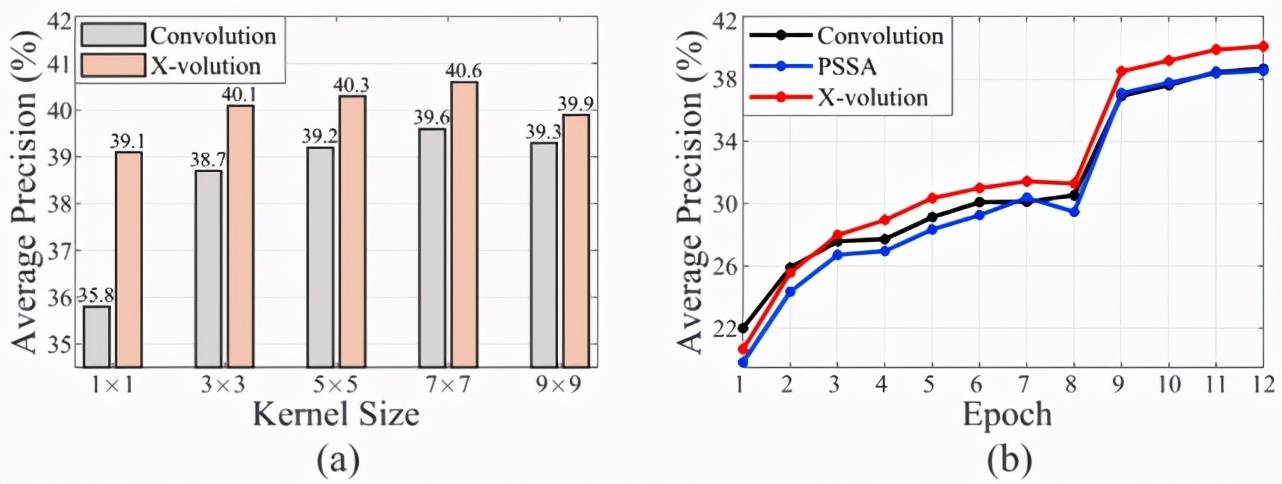
文章图片
图 2 , (a) 研究不同卷积核对于性能的影响;(b) 不同形态算子的优化性能比较 。
在图 2(b) 中 , 研究者展示了卷积、PSSA 和 X-volution 三种算子在 MS COCO 目标检测上的收敛曲线 。 可以看到 , 卷积在最开始时性能优于 X-volution 和 PSSA;而经过 3 个周期训练后 , X-volution 开始超越卷积 , 但是作为self-attention的逼近形式 , PSSA在前9个周期收敛性能稍弱于卷积 。 其后 , X-volution 一直保持显著的领先 。 PSSA 则在 10 个周期后与卷积相当或略好于卷积 。 这组曲线证实了卷积的局部归纳偏置对于其训练是有明显的帮助 , 而低偏置的 self-attention 则收敛显著慢于卷积 , 但经过较长时间训练后可以超越卷积 。 将两者整合的 X-volution 则兼备了卷积和 self-attention 的特性 , 同时展现了优秀的优化特性和良好的性能 。
总结
作者在文中提出了一种新型的算子——X-volution , 整合了卷积和 self-attention 的互补特性 。 同时 , 他们从 self-attention 的公式中导出了一种巧妙的全局自注意力的逼近形式——PSSA 。 作者通过在分类、目标检测、实例分割等任务中的优秀表现证实了所提出的算子的有效性 。 实验也揭露了卷积与 self-attention 的配合确实能较为显著地提升性能 , 并且两者达到了实质上的特性互补 。 该新型算子在性能上的显著提升、计算的通用性与即插即用性方面的巨大优势 , 为深度学习基础计算单元库 , 以及 NPU 计算架构的演进提供了一种新的基础武器 。
注:该论文作者是上海交通大学海思实习生陈炫宏和王航 , 由计算机视觉知名专家倪冰冰教授指导 。
推荐阅读





- 技术|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- 重大进展|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- Tencent|原生版微信上架统信UOS应用商店:适配X86、ARM、LoongArch架构
- 国家|2022上海国际热处理、工业炉展览会
- IT|8号线、14号线将全线贯通 北京地铁?今年开通线路段创纪录
- 软件和应用|iOS/iPadOS端Telegram更新:引入隐藏文本、翻译等新功能
- Intel|Intel谈DDR5内存价格贵、缺货问题:新技术升级在所难免
- IT|宝马电动转型成果初显:i4、iX供不应求 新能源车销量已破百万
- 银行|银行卡、社保卡可直接刷卡坐公交 上海公交开始试点
- 概念股|孙佳山、张泰旗:警惕元宇宙可能带来的金融泡沫