机器之心专栏
作者:阿德莱德大学、同济大学、字节跳动
来自阿德莱德大学、同济大学、字节跳动的研究者设计了一种简单且有效的密集自监督学习方法 , 大幅缩小了自监督预训练与密集预测任务之间的鸿沟 。预训练已被证实能够大大提升下游任务的性能 。 传统方法中经常利用大规模的带图像标注分类数据集(如 ImageNet)进行模型监督预训练 , 近年来自监督学习方法的出现 , 让预训练任务不再需要昂贵的人工标签 。 然而 , 绝大多数方法都是针对图像分类进行设计和优化的 。 但图像级别的预测和区域级别 / 像素级别存在预测差异 , 因此这些预训练模型在下游的密集预测任务上的性能可能不是最佳的 。
基于此 , 来自阿德莱德大学、同济大学、字节跳动的研究者设计了一种简单且有效的密集自监督学习方法 , 不需要昂贵的密集人工标签 , 就能在下游密集预测任务上实现出色的性能 。 目前该论文已被 CVPR 2021 接收 。
论文地址:
【训练|无需密集人工标签,用于下游密集预测任务的自监督学习方法出炉】https://arxiv.org/pdf/2011.09157
代码地址:
https://github.com/WXinlong/DenseCL
方法
该研究提出的新方法 DenseCL(Dense Contrastive Learning)通过考虑局部特征之间的对应关系 , 直接在输入图像的两个视图之间的像素(或区域)特征上优化成对的对比(不相似)损失来实现密集自监督学习 。

文章图片
两种用于表征学习的对比学习范式的概念描述图 。
现有的自监督框架将同一张图像的不同数据增强作为一对正样本 , 利用剩余图像的数据增强作为其负样本 , 构建正负样本对实现全局对比学习 , 这往往会忽略局部特征的联系性与差异性 。 该研究提出的方法在此基础上 , 将同一张图像中最为相似的两个像素(区域)特征作为一对正样本 , 而将余下所有的像素(区域)特征作为其负样本实现密集对比学习 。
具体而言 , 该方法去掉了已有的自监督学习框架中的全局池化层 , 并将其全局映射层替换为密集映射层实现 。 在匹配策略的选择上 , 研究者发现最大相似匹配和随机相似匹配对最后的精度影响非常小 。 与基准方法 MoCo-v2[1] 相比 , DenseCL 引入了可忽略的计算开销(仅慢了不到 1%) , 但在迁移至下游密集任务(如目标检测、语义分割)时 , 表现出了十分优异的性能 。 DenseCL 的总体损失函数如下:
模型性能
该研究进行消融实验评估了匹配策略对下游任务的性能影响 , 结果如下表所示 。
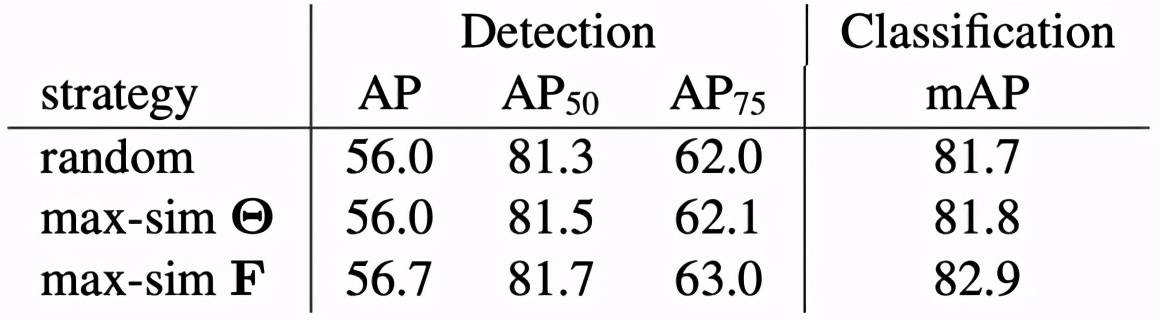
文章图片
另一组消融实验评估了预训练区域数量对下游任务的性能影响 , 结果如下表所示 。
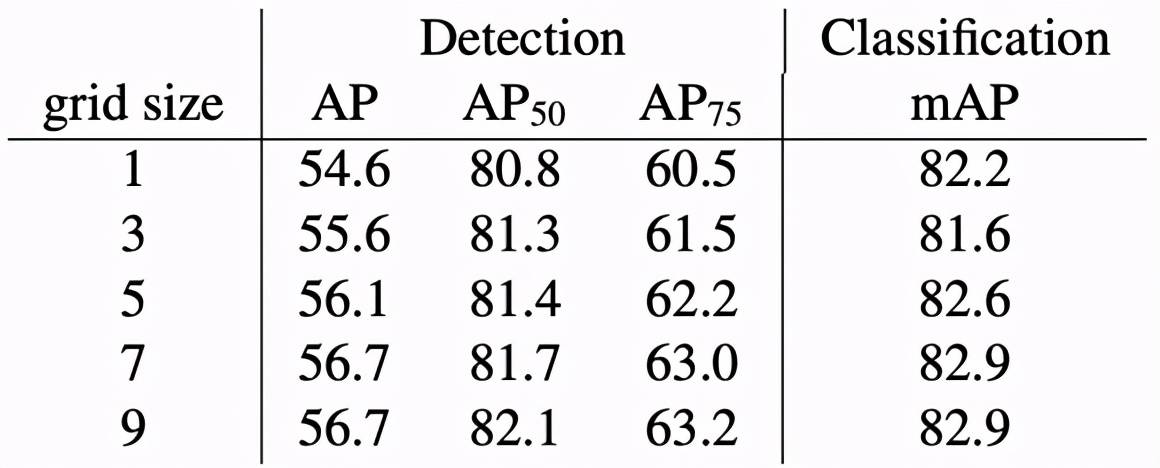
文章图片
下图展示了该方法迁移至下游密集任务的性能增益:
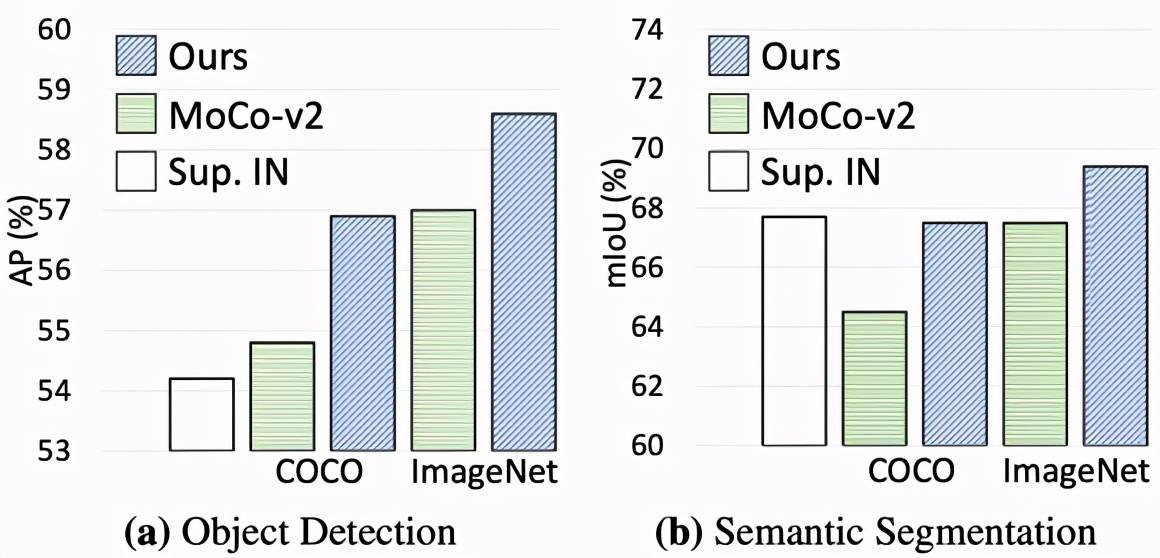
文章图片
随着训练时间的延长 , 该研究进一步提供了与基线的直观比较 , 表明 DenseCL 始终比 MoCo-v2 的性能高出至少 2%:
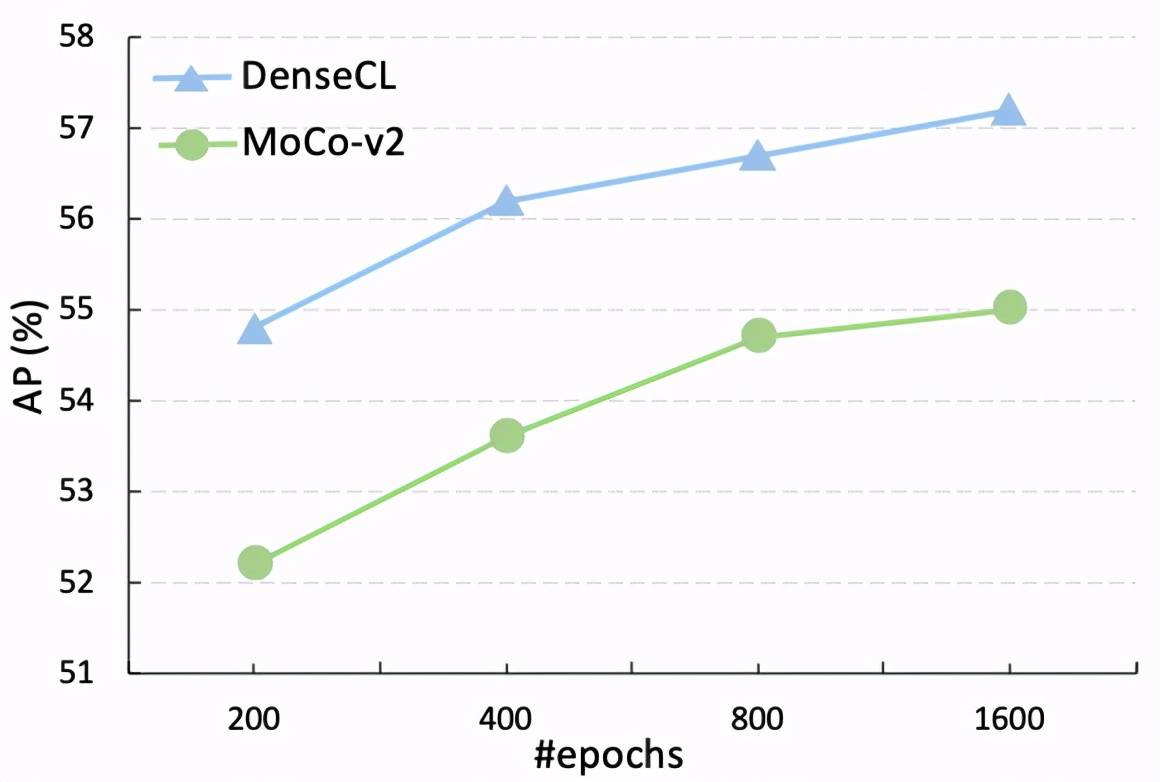
文章图片
DenseCL 与 MoCo-v2 的预训练时间消耗对比如下:
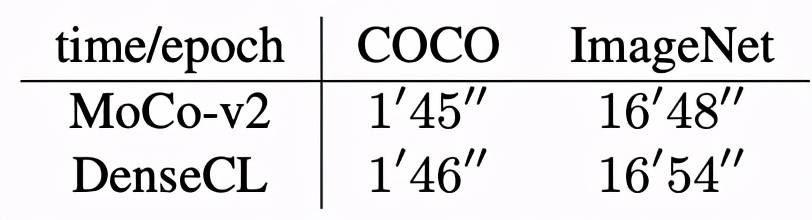
文章图片
下图对高相似度匹配进行了可视化 , 旨在描述局部语义特征间的对应关系:

文章图片
如下图所示 , 带有随机初始化的大多数匹配都是不正确的 , 从图中可以看出随着训练时间的变化 , 对应关系发生了改变 。

文章图片
[1] Improved baselines with momentum contrastive learning. Chen, Xinlei and Fan, Haoqi and Girshick, Ross and He, Kaiming
推荐阅读



- Intel|英特尔正为Linux 5.17准备PFRUT:升级系统固件无需重启
- 画质|AMD RSR 分辨率缩放技术曝光:基于 FSR,无需游戏适配即可使用
- 电子商务|无需扫码、碰一碰即可完成支付 数字人民币硬钱包充电桩项目启动!
- 训练|华为运动健康 Beta 新版本测试:新增健身课程分享、血压挑战计划
- 模型|神经辐射场去掉「神经」,训练速度提升100多倍,3D效果质量不减
- 文件|微信新功能上线,无需登录就可传输文件
- 来源|重大突破!以后吃鱼或无需挑刺!吃货们坐不住了…
- 训练|腾讯云副总裁吴运生:AI落地出现新变化,对细分行业需要深入理解
- 消息|重大突破!以后吃鱼或无需挑刺,吃货们坐不住了
- 中国|航天员选拔挑战重重,未来普通人经过长时间训练也能太空旅行?