机器之心原创
作者:张倩
中文预训练语言模型 , 参数量也上了千亿 , 还是为业界定制的 。如果你是一位 NLP 从业者 , 你可能发现 , 最近的中文 NLP 社区有点热闹:「中文版 T5」、「中文版 GPT-3」以及各种大规模中文版预训练模型陆续问世 , 似乎要带领中文 NLP 社区跑步进入「练大模型」时代 。
在此背景下 , 中文语言理解测评基准「CLUE」也经历了它的前辈「GLUE」所经历过的盛况:一个模型的冠军宝座还没坐热 , 就被一个更新的模型挤了下去 。
这次刷榜的 , 是一个叫「盘古」的 NLP 模型 。
在最近的 CLUE 榜单上 , 「盘古」在总榜、阅读理解排行榜和分类任务排行榜上都位列第一 , 总榜得分比第二名高出一个百分点 。
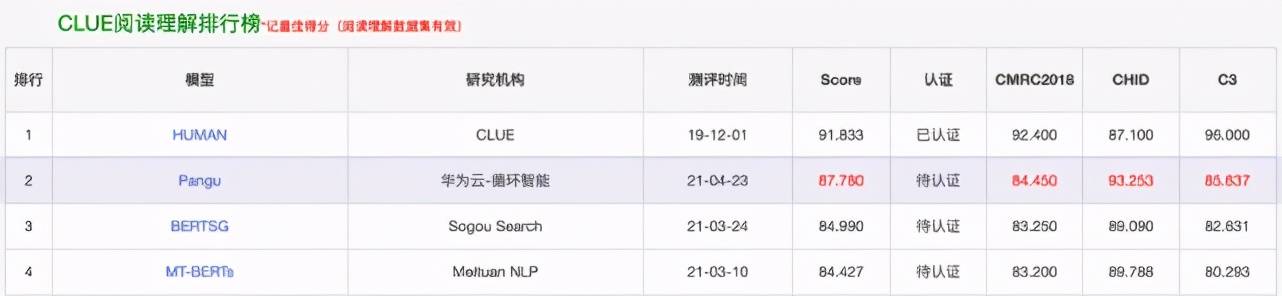
文章图片
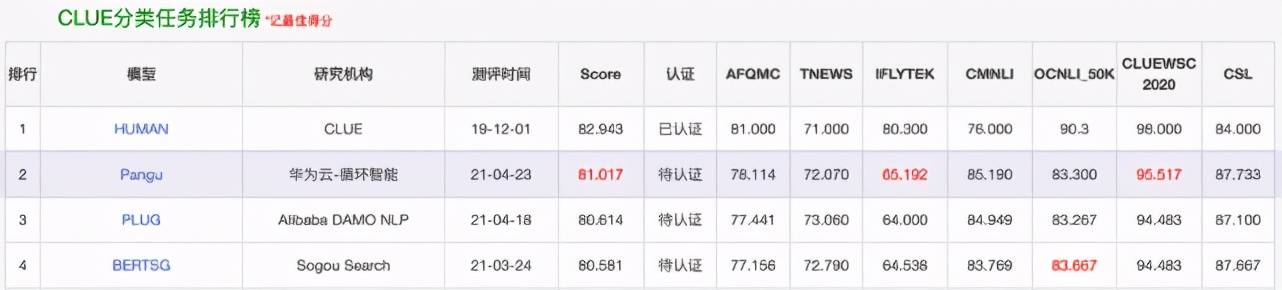
文章图片
除此之外 , 它还拿到了 NLPCC 生成任务的第一名 , 文本摘要的分数相比基线提升了 60% 。
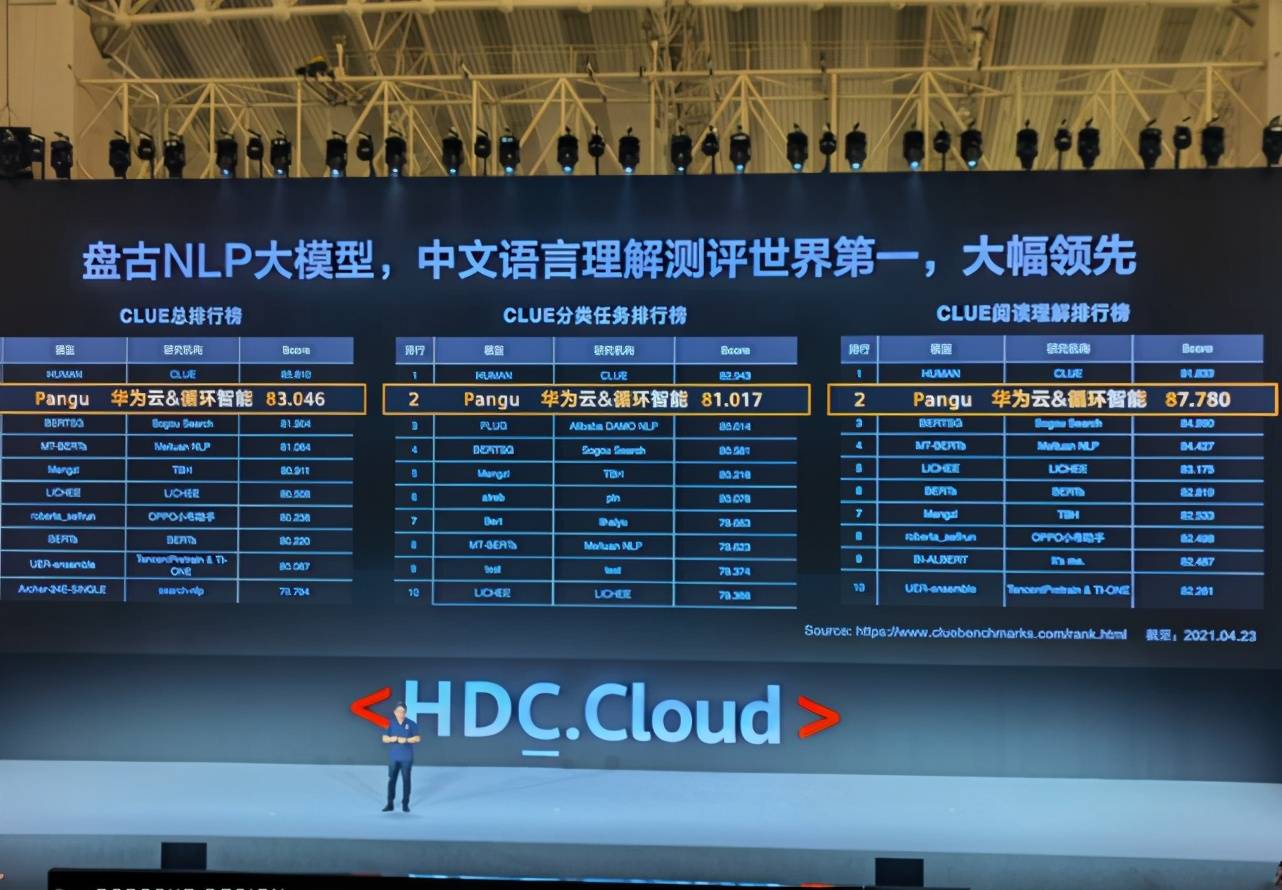
文章图片
在HDC.Cloud大会上 , 余承东发布由华为云和循环智能联合开发的盘古NLP 模型
这是业界首个千亿参数的中文大模型 , 拥有 1100 亿密集参数 , 由循环智能(Recurrent AI)和华为云联合开发 , 鹏城实验室提供算力支持 。
为了训练这个模型 , 田奇(华为云人工智能首席科技家)与杨植麟(循环智能联合创始人)联合带领的研究团队花了近半年的时间 , 给模型喂了 40TB 的行业文本数据和超过 400 万小时的行业语音数据 。
所有这些努力 , 都是为了克服 GPT-3 的落地难题 。
「GPT-3 是一个学术界的产物 , 是一个学术研究的重大突破 , 但在落地过程中仍然面临很多问题 。 」杨植麟告诉机器之心 , 「导致这个问题的原因是 , 学术研究往往以人工收集构造的相对通用化的数据集作为 benchmark , 往往以较理想化的设定来进行实验(比如类别均衡的多分类问题) , 这些都跟实际应用有出入 。 盘古模型实际上针对性地解决了这些问题 。 跟以往的大规模预训练模型不同 , 盘古模型从第一天起就是奔着商业化落地的角度进行设计和研发 。 」
作为一个深耕 NLP 企业服务的团队 , 循环智能看到了 GPT-3 等大规模预训练模型的潜力 , 但也看到了它们在落地过程中的局限 。 「盘古」模型正是为了克服这些局限而生 。 在最近的一次访谈中 , 循环智能 NLP Moonshot 团队向机器之心介绍了这个项目的初衷、挑战和具体的解决方案 。
GPT-3 很强 , 但到了业界不好用
GPT-3 是 OpenAI 在去年 5 月份发布的语言模型 , 不仅可以答题、翻译、写文章 , 还带有一些数学计算的能力 , 因此在人工智能领域掀起了一场巨浪 。
GPT-3 很强 , 这是社区公认的事实 , 所以循环智能最初是想开发一个中文版 GPT-3 。 但在开发过程中 , 他们发现:GPT 类模型在复杂的商业场景中既不好用 , 也不高效 。
具体来说 , 问题出在三个方面 。
第一个问题是:GPT 对于复杂商用场景的少样本学习能力较弱 。 少样本学习是指利用少量标注样本完成模型的学习任务 。 在高质量数据紧缺、经济效益至上的产业界 , 这一能力非常重要 。
此前 , Schick 和 Schutze 已经在 PET 工作中证明:在少样本学习方面 , 千亿参数的 GPT-3 模型的语言理解能力还比不上亿级参数量的 BERT 。 在复杂的企业级落地场景中 , 这一缺陷将使得模型在利用数据方面非常低效 。
比如在下面这两段保险场景对话中 , 模型需要判断服务人员是否正确讲解了「现金价值可以通过退保的形式返回」这个专业保险知识 。 正例需要完整说明以下方面:(1)要用退保的形式;(2)退回的是现金价值 。
对话 1:
服务人员:「它有一个养老的功能 , 以后您不想保了 , 那么到一定年限 , 到现金价值的高峰期间可以退保 , 拿到现金价值 」
对话 2:
服务人员:「您如果说保的时间 , 不会 , 因为交的钱是固定的 。 只是您这个保单对应的现金价值是每年往上涨的」
显然 , 对话 1 同时提及了退保和退回现金价值两个主要因素 , 应被判断为正例;而对话 2 只提及了现金价值 , 并不涉及现金价值赎回的介绍 , 应被判断为负例 。 但针对 30 亿参数的中文 GPT 模型 CPM 的少样本学习测试发现 , 该模型并没有给出正确答案 。
再比如 , 在下面这段教育场景对话中 , 模型需要判断课程顾问是否推荐了全科辅导班 。 如果推荐了 , 则判断为正例 , 否则判断为负例 。
对话 3:
课程顾问:「啊没有那么多 , 你是考虑单科辅导班还是全科辅导班?」
客户:「这个这个我还没考虑好 」
显然 , 在这段对话中 , 课程顾问只是单纯询问 , 并未体现推荐 , 因此应被判断为负例 , 但 CPM 依然没有正确识别 。
除了少样本学习 , 实际应用中还存在一些需要通过大量样本进行学习的场景 , 这就要涉及到模型的微调问题 。 但现实是 , GPT-3 对于微调并不友好 , 在落地场景中难以进一步优化 , 这也是 GPT 模型存在的第二大问题 。
商业场景对于模型的准确率和召回率有着很高的要求 。 虽然 P-Tuning 等工作提出了针对 GPT-3 的新型微调方式 , 但在面对复杂场景时 , 我们仍然难以通过使用更多标注数据对 GPT-3 进行进一步优化 。
「比如说我们现在用到的一个场景里面 , 通过少量样本得到 GPT-3 的准确率是 65% 。 在学术研究的语境下 , 这个准确率听起来也不是很差 , 但是你实际场景就没法用 。 这时我们要加一些数据对模型进行优化 , 要做到 90% 才能用 , 但我们实验发现 GPT-3 结合微调的提升并不明显 , 这就大大限制了它的使用场景 。 」杨植麟表示 。
GPT-3 是一个百科全书式的存在 , 但在很多落地场景中 , 我们更需要的是一个领域「专家」 。 为了打造这个「专家」 , 我们需要将行业的知识库接入 AI 流水线 , 将通用 AI 能力跟行业知识相结合 , 实现基于行业知识的精确理解和预测 。
「例如 , 在实时辅助场景中 , 我们希望模型能够实时地给销售推送知识、讲解要点、推荐产品 , 通过增强智能的方式提升销售能力 。 在这个场景中 , 就需要大量外部知识的接入 , 才能达到较好的推荐效果 。 」循环智能资深算法总监陈虞君解释说 。
但与之相矛盾的是 , GPT-3 只能进行直接的、端到端的生成(把知识库做成很长的一段文字 , 直接放进 prompt 中) , 难以融入领域知识 , 这便是它的第三大问题 。
在这三大问题的限制下 , GPT-3 的强大能力很难直接在商业场景中得到发挥 。
盘古:打通 NLP 技术到产业的最后一公里
好用、高效是业界对一个模型的基本要求 。 要达到这个要求 , 首先要克服以上三大问题 , 这也是「盘古」模型的创新之处 。
如何提高少样本学习能力?
为了克服少样本学习难题 , 循环智能的研究团队进行了两方面的努力 。
一是利用迁移学习 。 与 GPT-3 的少样本学习方式不同 , 盘古模型的技术路线是通过元学习的方式在任务之间进行迁移 , 从而实现少样本学习的目标 。 这种方式可以更好地利用任务之间的相似性 , 得到更好的少样本学习结果 。
二是将 P-tuning、priming 等最新技术融入到盘古的微调框架中 , 进一步提升微调效果 。
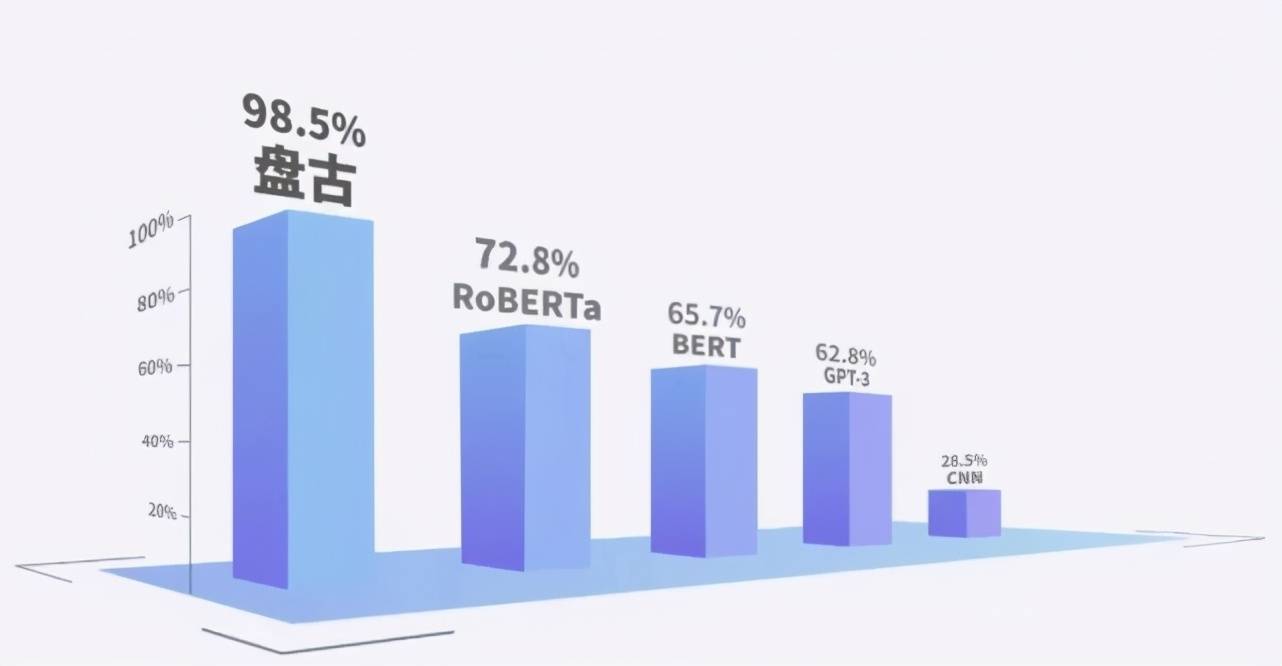
下面两个图展示了 CNN、中文版 GPT-3(CPM)、BERT、RoBERTa 和盘古在少样本场景下的学习能力 。
文章图片
复杂商用场景实测不同模型少样本学习达到的 F1 结果(100%表示跟 full label 结果相同)

文章图片
各模型复杂商用场景实测得到目标 F1 结果所需的平均样本量
从第一幅图可以看出 , 在样本极少的情况下 , 盘古的少样本学习能力远超上述 GPT 系列和 BERT 系列 。
第二幅图则显示 , 要得到相同的 F1 结果 , 盘古所需的数据量仅为中文 GPT-3 的 1/9 , 实现了近 10 倍的生产效率提升 。 「也就是说 , 以前可能两个星期才能完成的一些工作 , 现在你用一两天就可以做完 。 所以 , 这个模型实际上有很大机会去变革生产效率 。 」循环智能资深算法总监杜羽伦解释说 。
如何解决大模型微调难题?
大模型微调难题的解决也分为两个方面 。
首先 , 为了增强预训练与微调的一致性 , 研究者在预训练阶段加入了基于 prompt 的任务 。 Prompt pattern 的选择和数据增强机制保证了微调阶段使用的 prompt 得到充分的预训练 , 大幅度降低了基于 prompt 的微调的难度 。 在下游数据充足时 , 微调难度的降低使得模型可以随着数据变多而持续优化;在下游数据稀缺时 , 微调难度的降低使得模型的少样本学习效果得到显著提升 。
其次 , 研究者观察到 , 随着预训练模型规模的增大 , 微调难度不断上升 , 过拟合十分严重 。 因此 , 他们分析了过拟合的主要来源 , 采用了 gradient dropout 等机制对微调过程进行正则化 , 可以较大程度缓解过拟合的问题 。
下图展示了研究团队针对销售线索评分场景进行实测的结果 。 在销售线索评分场景中 , 数据相对充裕 , 模型通过分析数十万条历史数据的成单情况对每条销售线索的客户意向度进行评分 。 在这种情况下 , 由于更适合微调 , 盘古模型在最终的销售转化率上取得较大提升 。
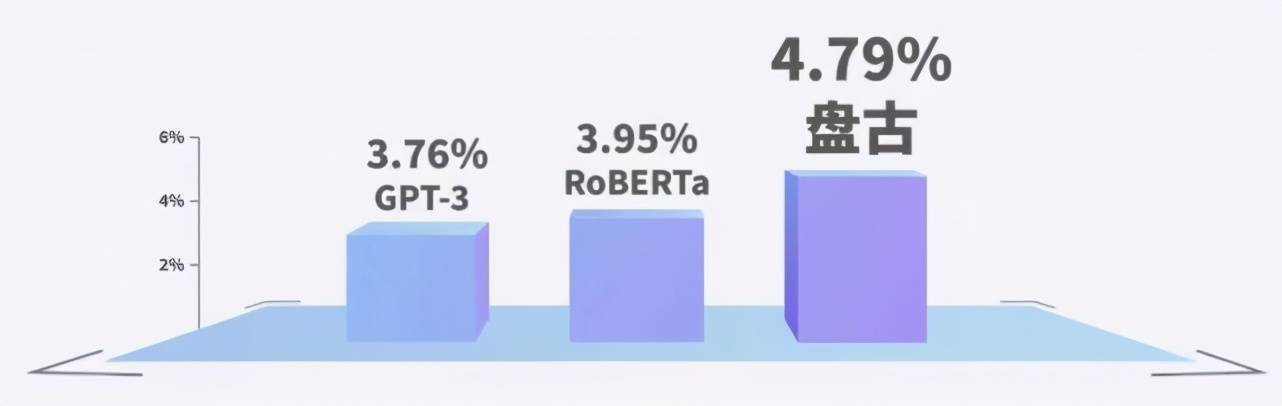
文章图片
基于对话内容的销售线索评分场景中 , 使用不同模型的实测销售线索转化率对比
如何融合行业知识?
行业知识来源于行业数据 。 盘古团队使用了大量行业语音和文本数据 。 这些数据来自销售、客服等企业与客户之间的沟通场景 , 涵盖金融、保险、教育、地产、本地生活、电商、汽车等诸多行业 , 构成了庞大的行业知识库 。 借助这些数据进行微调 , 模型的行业特定意图和知识理解能力大幅提高 。
此外 , 与 GPT-3 直接使用端到端生成的方式不同 , 由于盘古模型同时具备生成能力和少样本理解能力 , 开发者可以根据业务需求灵活搭建 pipeline , 包括与行业知识库进行对接 , 实现行业知识与通用知识的融合 , 最大程度上满足个性化的业务需求 。
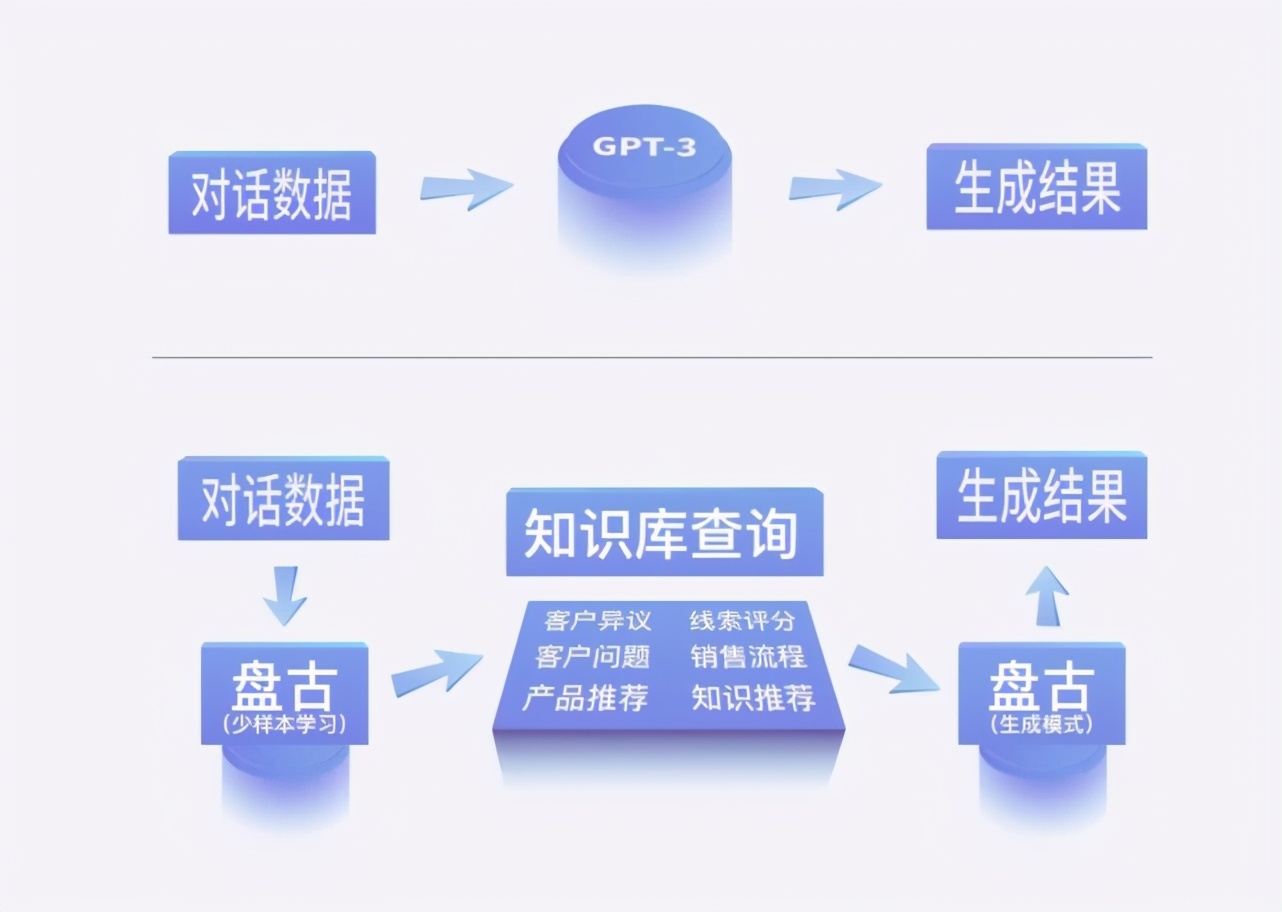
文章图片
可以说 , 与 GPT-3 等模型相比 , 「盘古」是专门为产业落地所打造的 , 其终极目标就是「打通 NLP 技术与产业的最后一公里」 。
如何赋能产业?
模型有了 , 之后要怎么用呢?在这方面 , 循环智能 NLP Moonshot 团队给出了正在做的两个方向 。
第一个方向是深入具体场景 。
在过去的几年中 , 企业通过部署 AI 客服、AI 外呼系统 , 取代了一小部分人员的简单工作 。 但很多情况下 , 客户并没有感觉自己的服务体验得到了改善 , 尤其是在涉及高附加值行业的产品销售与服务时 。
以银行、保险、房产和教育等国计民生领域为例 。 在这些领域 , 企业意识到只有通过人与人的沟通过程 , 才能与客户建立更紧密的联结 。 如果 NLP 技术可以在提升员工专业度和产能方面发挥作用 , 就可以帮助企业为其客户带来更好的体验 , 创造更大的价值 。
这就是循环智能主攻的方向——增强「人」的智能 。
他们的思路可以概括为:借助先进的 NLP 技术 , 从企业与客户沟通时产生的对话数据中挖掘优秀员工的优秀实践 , 把这些优秀实践变为企业资产 , 然后通过更有针对性的培训和「实时辅助」系统 , 将优秀实践传递给每一名普通员工 , 提升他们的表现 。
通俗点说 , 实时辅助系统有点像企业给销售代表、客服等工作人员配备的一个「外挂」 , 这个「外挂」可以实时提示工作人员如何更好地解答客户的疑问 , 如何更专业地向客户介绍产品和服务……
在实际应用中 , 循环智能为企业提供对比测试方案以衡量产品价值 。 他们发现 , 通过让员工变得更专业 , 实时辅助系统往往能够带来员工的产能提升和公司的营收再增长 。 这个千亿级别的市场 , 有望借助「盘古」模型的能力 , 更快地实现规模化应用 。
第二个方向是打造通用 API 。
【难题|瞄准GPT-3落地难题,千亿中文大模型盘古问世,专攻企业级应用】大模型是一种基础设施类型的存在 。 在杨植麟看来 , 「盘古」有望成为一个通用 API , 开启一种新的商业模式 。 在这种模式中 , 开发者可以基于通用 API , 结合业务场景 , 灵活高效地定制行业应用 , 解锁更多此前想象不到的场景 。
华为云人工智能首席科学家、IEEE Fellow 田奇也表示:「盘古 NLP 大模型可以实现一个 AI 大模型在众多场景通用、泛化和规模化复制 , 减少对数据标注的依赖 , 让 AI 开发由作坊式转变为工业化开发的新模式 。 」
「基于模型的 AI 时代」即将到来?
清华大学计算机科学与技术系教授唐杰在前段时间接受机器之心采访时曾表示 , 「超大规模预训练模型的出现 , 很可能改变信息产业格局 。 继基于数据的互联网时代、基于算力的云计算时代之后 , 接下来可能将进入基于模型的 AI 时代 。 」杨植麟也同意这一观点 。 在他看来 , 这个新时代将有两大特征 。
一是 AI 生产效率的变革 。 随着标注数据需求大幅降低 , AI 生产效率将迎来两到三个数量级的提升 , 摆脱原来依靠大量样本的落后生产方式 , 进入规模化量产时代 。
二是 AI 场景的指数级增加 。 技术的突破往往带来新市场 , 而目前 AI 商业化的现状就是需求很多但技术不一定满足 。 AI 预训练技术突破之后 , 马上可以解锁很多新场景 , 从数字化程度比较高的行业走向传统行业 , 从大型企业走向中小企业 。
杨植麟认为 , 预训练的难题有三个层次:(1)如何突破现有范式的瓶颈 , 拓展智能边界 , 实现更强的认知能力;(2)基于现有范式 , 如何进行技术提升 , 打通技术和产业的最后一公里;(3)如何找到合适的商用场景 , 创造预训练模型的商业价值 。
如果「基于模型的 AI 时代」真的到来 , 学界和业界可能将迎来更加清晰的分工:「盘古模型做的是 2 和 3 , 也是产业界重要的工作 。 学界应该做的是 1 和 2 。 学界和业界应该合作 , 通过学术资源、算力资源、商业资源的交融 , 把预训练技术往前推进 。 」
推荐阅读

- 智能汽车|瞄准2022的靶心 智能汽车还要深挖潜力
- 华为|国产厂商下场自研芯片,手机同质化难题有解了?
- 产品|走进园区企业丨用尖端材料学解决医学难题
- 趋势|阿里巴巴达摩院2022十大科技趋势发布:人工智能或将解决风光电并网难题
- 门店|“护脸”难题难在哪?怎么破?
- 上海|无授权收集、无感化采集、无底线牟利……“护脸”难题难在哪?怎么破?
- 上海|无授权收集、无感化采集、无底线牟利……“护脸”难题难在哪?
- 科技展|瞄准“住中服务”,锦江都城酒店联手云迹科技展现数字酒店新范式
- 服务|瞄准智能化服务赛道 晓多科技用AI和大数据解放人工客服
- 鲸鱼|上海儿童艺术剧场公布2022演出季,挖掘破局内容难题