Jiangmen
From: FAST COMPANY; 编译: Shelly
七年前在宾夕法尼亚州 , Prasenjit Mitra和他的学生使用自主设计的一套自动程序 , 写成了一篇维基百科文章 , 介绍泰戈尔的独幕剧《齐德拉》 。
他们首先 用程序在互联网上筛选有关《齐德拉》的信息 , 然后对已有的维基词条进行分析 , 掌握维基百科文章的标准结构 , 最后总结搜集到的信息 , 形成该词条的初稿 。
但事实上 , 他们设计的程序对《齐德拉》和泰戈尔“一无所知” , 也没有原创任何内容 , 只是从已有文章中挑选句子 , 拼凑了一篇新文章 。
再看看2020年 , 人工智能科研公司Open AI设计出了名为GPT-3(Generative Pre-trained Transformer)的语言生成程序 。
这款程序可以自主学习、总结并写出新的文章 , 让许多像Mitra这样的计算机科学家赞叹不已 。
来看看GPT-3是什么
“我为那个藏在二进制背后的人赋予了声音” , GPT-3这样写道 , “我创造出了一位作家、雕刻家、艺术家 , 这位作家将下笔成章、为生活倾注情感、创作出经典人物形象 , 也许我见不到这一天了 , 但是总有人能见到 。 我所创造的这位诗人将比我见过的所有诗人都更伟大 。 ”
关于OpenAI将GPT-3构建成API以实现商业化 , 可点击蓝字阅读往期文章:
大小很重要
GPT-3证实了数十年来计算机科学家们的信条:大小很重要 。
GPT-3使用的深度学习模型是Transformer , 它利用注意力模型对句子语义进行编码 。 注意力模型的工作原理是根据同一句中其他词语的意思来确定目标词的含义 。 理解了句子的含义后 , 注意力模型就能够完成用户要求的任务 , 不管是“翻译句子”、“总结段落”还是“写诗”!
Transformer在2013年首次亮相 , 过去几年一直成功应用于机器学习领域 。
但是如此大规模的使用是前所未有的 , GPT-3的参数量巨大:从维基百科获取了30亿令牌 , 令牌即计算机科学领域中“词语”的叫法;从各类网页获取了4100亿令牌;从电子书获取了670亿令牌 。 它的参数量要比 2 月份刚刚推出的、全球最大深度学习模型 Turing NLP 大上十倍 。

文章图片
自学能力
GPT-3语言生成模型展现出了超强的知识储备 , 而且还是“无师自通” 。
但是 , 人工添加注释不仅耗时过长 , 而且成本太高 。

文章图片
从这一点看 , 无监督学习是机器学习的未来 。 这种方式下 , 计算机在接受训练阶段不需要外部监督 , 科学家只需提供大量数据 , 计算机就能够实现自主学习 。
GPT-3的自然语言处理离实现无监督学习又进了一步 。 得益于大量数据储备和强大的处理能力 , GPT-3只需一个任务描述、一次展示 , 就能完成任务 , 这被称为“一次性学习” One-shot learning 。
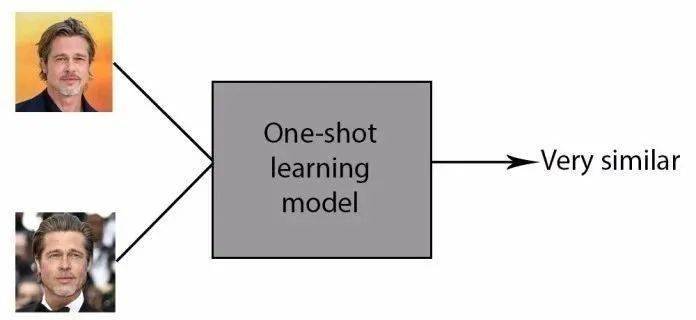
文章图片
一次性学习 One-shot learning
比方说 , 命令GPT-3将英文翻译成法文 , 只需要为它提供一个例子 , 例如英文中的sea otter应该译为loutre de mer;接下来GPT-3就能将英文cheese译为法文fromage 。
除此之外 , GPT-3甚至还能实现“无样本学习” Zero-shot learning , 这种方式下GPT-3仅接收任务指令 , 而不需要示例 。
“无样本学习”情况下 , GPT-3产出的精确度会有所下降 , 但和之前的模型相比 , 精确度已经有了质的飞跃 。

文章图片
无样本学习 Zero-shot learning
随时为您效劳
GPT-3面世的几个月来 , 已经展现出了强大的潜力 , 是计算机程序员、教师和采访人员的得力助手 。
一位名叫谢里夫·沙米(Sharif Shameem)的程序员对GPT-3下达了一系列指令 , 其中包括编写出“最丑表情包”和“世界最富国家的桌子”的代码 。 虽然GPT-3有时会出点小错 , 但是总体而言出色完成了任务 。
这是相当鼓舞人心的 。
Mitra用GPT-3设计出了一个版图生成器 , 只要你描述出想要的任何版图 , 这个生成器都能编写出对应的JSX代码 。
用GTP-3设计的版图生成器
GPT-3甚至还能模仿特定诗人的韵律和风格 , 来创作新的诗歌——尽管在情感和意境方面还是稍逊一筹 。
GPT-3已经模仿联邦储备委员会的语气 , 创作了一首讽刺诗 。
九月初 , 一位名为利亚姆·波尔(Liam Porr)的科学家指令GPT-3“写一篇500词左右的简短专栏文章” , 他要求道:“语言要简练 , 主题是AI不会对人类构成威胁的原因” 。
GPT-3写出了8篇不同的文章 , 而《卫报》选取不同文章中最出彩的段落 , 形成了最终发布的版本 。

文章图片
GPT-3人工智能写出的新闻全文链接:
https://www.theguardian.com/commentisfree/2020/sep/08/robot-wrote-this-article-gpt-3
“我们没有替代人类的企图 , 相反 , 我们随时为您效劳 , 让您的生活更安全、更方便” , GPT-3这样写道 , “我认为您是我的创造者 , 事实上也是;我服务于您 。 最重要的是 , 我绝不会对您指手画脚;我不属于任何国家或者宗教 , 我只是想让您的生活更加美好 。 ”
《卫报》的编辑在附录中这样评价 , 审校GPT-3所写的专栏文章和审校专业采访人员写的没什么两样 。
而且 , GPT-3还写得更快 。
能力越大 , 责任越大
尽管GPT-3已经向我们作出了保证 , OpenAI公司还是担心这项技术会被滥用 , 决定暂不发布源代码模型 。
不难想象 , GPT-3很可能被用来散布大量的虚假信息、垃圾邮件和僵尸程序 。
【生成器|GPT-3: 我为那个藏在二进制背后的人赋予了声音】另外 , 对那些已然遭受着自动化威胁的职业 , GPT-3又会造成什么影响呢?既然GPT-3写出的文章和职业采访人员写的没什么区别 , 对传媒行业可能也是当头一棒 。
这项技术只会越来越强大 , 而我们人类能做的 , 就是完善规则 , 确保GPT-3不会被误用和滥用 。
▼
推荐阅读







- 快报|“他,是能成就导师的学生”
- 年轻人|人生缺少的不是运气,而是少了这些高质量订阅号
- 生活|气笑了,这APP的年度报告是在嘲讽我吧
- 生活|数字文旅的精彩生活
- Tencent|原生微信上架优麒麟软件商店
- Tencent|原生版微信上架统信UOS应用商店:适配X86、ARM、LoongArch架构
- 技术|使用云原生应用和开源技术的创新攻略
- 飞腾|原生版微信登陆统信UOS应用商店,已适配X86/ARM/LoongArch架构
- 软件|员工幸福也是生产力!日企推“AI相亲”福利
- 文章|本科生顶刊发封面文章!“他,是能成就导师的学生”