机器之心专栏
机器之心编辑部
在机器学习领域 , 人们始终对模型的可解释性存在担忧 。 我们有没有办法写出可解释的模型 , 建立起人对于机器的信任?
受益于深度学习技术的突破 , 图像分类、物体检测等传统计算机视觉任务的精度也得到了大幅度的提升 。 但是由于深度学习模型的复杂性 , 目前关于深度学习的理论并不完善 , 这就导致了两大问题:
第一 , 模型的工作机制对使用者来说并不透明 , 人们无法解释模型识别正确或错误的原因 , 因此也就无法从理论上证明模型在实际应用中是否能够达到好的效果 , 从而在一定程度上阻碍了模型在一些性命攸关的领域中应用(如医疗影像分析、自动驾驶等);
第二 , 几乎完全基于数据驱动的方式学习模型参数 , 难以将人们长期以来总结形成的经验和知识融入模型 , 从而难以对模型学习过程施加有效的约束 , 使模型在小训练样本、零训练样本等真实条件下的精度远低于人类 。
人工智能领域顶级学术期刊 IEEE Transactions on Pattern Analysis and Machine Intelligence(即 IEEE TPAMI , 影响因子 17.861)最近接收的论文《What is a Tabby? Interpretable Model Decisions by Learning Attribute-based Classification Criteria》中 , 华为云联合中科院计算所 , 针对上述两个问题提出了一种探索性的解决方案 , 通过利用物体类别之间存在的层级关系约束 , 自动学习从数据中抽取识别不同类别的规则 , 一方面对模型的预测过程进行解释 , 另一方面也提供了一条引入人工先验知识的可行途径 。
论文链接:https://ieeexplore.ieee.org/document/8907459
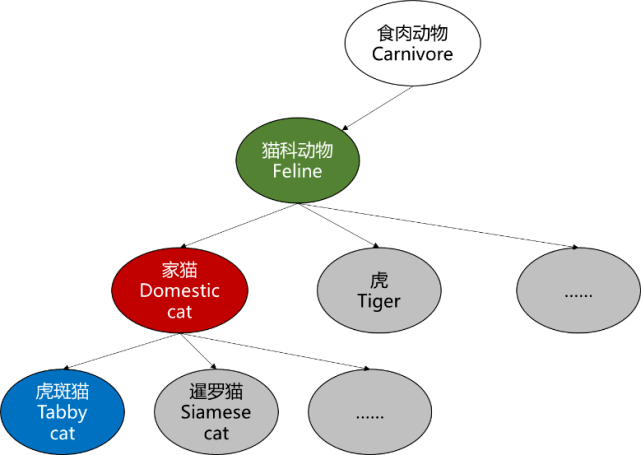
首先 , 我们通过一组简单的例子来看一下分类学家是如何对动物进行分类的(来自维基百科):
(1)「虎斑猫」是一种体表有条纹、斑点、线条、螺旋图案的「家猫」 。
(2)「家猫」是一种小型的、通常体表有皮毛的、肉食性的、被驯化的「猫科动物」;
(3)「猫科动物」是一种具有伸缩自如的爪子、苗条但肌肉强健的躯体、灵活的前肢的「食肉动物」 。
文章图片
图 1. 类别层级结构示意
从上边的例子可以看出来 , 分类学家在对动物进行分类的时候 , 采用了一种层级化的方式 , 在层级中 , 每个类别都被表示成「父类 + 一些特定属性」的形式 , 比如有条纹、有斑点、有线条、有螺旋 , 就是「虎斑猫」相比它的父类「家猫」出来的属性 。
实际上 , 如果对层级做一些压缩操作 , 每个类别都可以完全用一组特定属性来表示 。 以「虎斑猫」这个类别为例 , 经过一级压缩:「虎斑猫」是一种小型的、肉食性的、被驯化的、体表有带条纹、斑点、线条、螺旋图案皮毛的「猫科动物」 。 可以看到 , 经过一级压缩后 , 「虎斑猫」就可以通过「父类的父类 + 更多的属性」来表示了 。 更进一步 , 如果经过两级压缩:「虎斑猫」是一种小型的、肉食性的、被驯化的、具有伸缩自如的爪子、苗条但肌肉强健的躯体、灵活的前肢的、体表有带条纹、斑点、线条、螺旋图案皮毛的「食肉动物」 。 可以看到 , 经过两级压缩后 , 「虎斑猫」就可以通过「父类的父类的父类 + 更多更多的属性」来表示了 。
以此类推 , 如果一直将这个压缩的过程进行下去 , 「虎斑猫」就可以通过「动物 + 虎斑猫具有的全部属性」这种方式来表示了 。 对于其他动物来说 , 也是类似的 , 每种动物都可以表示为「动物 + 这种动物具有的全部属性」 。 由于每种动物的表示中都含有「动物」这个公共的组成部分 , 可以将每种动物的表示形式都简化为「这种动物具有的全部属性」 。 类似的 , 对于「植物」、「人造物」等等所有物体 , 都可以完全用一组属性来表示 。 因此 , 只要属性定义足够好 , 完全通过属性就可以准确地区分出来所有可能见到的类别 , 并且这种分类方式的可解释性非常好 , 也可以轻松地将新的人工先验知识引入进来 。
但是实际中 , 由于类别数量巨大、海量属性难以定义 , 不可能通过人工的方式对每个类别的属性进行定义 。 那么有什么方法可以在不对数据进行额外标注的情况下实现类似的分类方式呢?
方法介绍
事实上 , 上面的推理过程给我们提供了两点重要的洞察:第一 , 当属性足够多、足够好的时候 , 属性可以用来准确地区分不同的类别;第二 , 每个类别具有的属性数量一定比它的父类多 。 针对第一点洞察中对于属性数量和质量的要求 , 近期的研究 [1, 2, 3] 表明 , 以图像分类任务训练的深度学习模型可以自发地学习到一些具有语义的属性 , 因此通过这种方式 , 可以不再需要人工定义属性 , 仅通过算法自动学习的方式来得到足够多、足够好的属性;针对第二点洞察中对于类别间的约束关系的要求 , 可以将这样的类别间关系进行形式化 , 指导算法学习属性的过程 , 使学习到的属性满足约束条件 。 这样一来 , 就既解决了属性难定义、难标注的问题 , 又保留了基于属性进行分类的方案在高可解释性和便于引入人工先验知识方面的优势 。
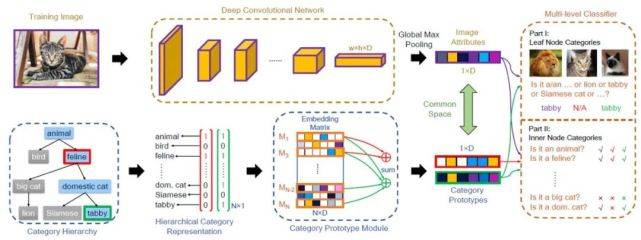
文章图片
图 2. 方法框架示意图
具体来说 , 作者在提出的方法中设计了一个包含两条分支的模型 , 如图 2 所示 。 上边的分支以图像作为输入 , 主要作用是学习属性;下边的分支以层级结构作为输入 , 主要作用是对学习属性的过程施加约束:
其中上边的分支使用常见的卷积神经网络 backbone , 上边分支的输出是一个 1×D 维的「属性向量」 , 向量中的每一维表示一个属性 , 每一维的值则表示图像样本是否具有这个属性(0 表示样本不具有这个属性 , 大于 0 的值表示样本具有这个属性) , 同时当激活值大于 0 时 , 激活值的大小表示图像样本在这个属性上的强度;
下边的分支按照类别间属性数量的约束关系 , 学习类别层级结构中每个类别的属性表示形式 。 在这里 , 令
表示层级结构中所有 N 个类别的 D 维属性表示(维度与图像特征相同 , 是下边的分支需要学习的参数) , 表示第 i 个类别的第 k 个属性的值 , 含义与图像表示中的含义相同 。 将层级结构用有向无环图表示 , 如果在层级结构中 , 第 j 个类别是第 i 个类别的祖先节点的话 , 那么由于每个类别的属性数量多于他的祖先节点这一约束 , 和需要满足下列约束:
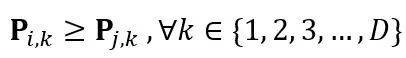
文章图片
训练时 , 损失函数的目标是要求两个分支的输出都能够正确的预测 D 维特征对应的最细粒度类别和对应的粗粒度类别 。 通过这种方式 , 上边的分支就可以学习到 D 个对于分类任务来说有用的属性 , 而下边的分支则可以保证这 D 个属性满足类别间属性数量关系的约束 , 从而可以对模型分类原理给出人类可以理解的解释 。
取得的效果
论文中 , 作者在 CIFAR-100 和 ILSVRC 两个大规模的层级数据库上进行了实验 , 通过大量的实验验证了方案的有效性:
1. 分类精度
从实验结果来看 , 尽管论文提出的方法针对提高模型的可解释性和提高引入人工先验知识的便捷程度做了大量的设计 , 但是在分类精度上仍然达到了 SOTA 的水平 , 表明该方案在实际业务中具有实用价值 。
2. 属性学习效果
定性展示结果方面 , 作者通过可视化的方式展示了模型学习到的属性 , 实验结果中针对每个属性 , 通过展示每个属性在数据集上响应值最大的 9 个图像块来表示属性 , 如图 3 所示 。 从图中看 , 模型学习到了大量不重复的、有意义的属性 , 并且既有比较简单的纹理、形状(dotted、round 等)属性 , 也有语义性更强的车轮、山等属性 。

文章图片
图 3. 算法学习到的属性展示 。 (a)CIFAR-100 数据库上学习到的属性;(b)ILSVRC 数据库上学习到的属性 。
从定量评测的结果来看 , 在包含 1000 个类别的 ILSVRC 数据上 , 模型学习到了 2600 多个属性 , 远超基线模型(标准 ResNet-50 分类模型)的 2000 个属性;在去除重复属性(可能包含了同种属性的不同情况)后 , 论文方法学到的属性数量接近 140 个 , 多于基线模型的 120 余个不重复的属性 。
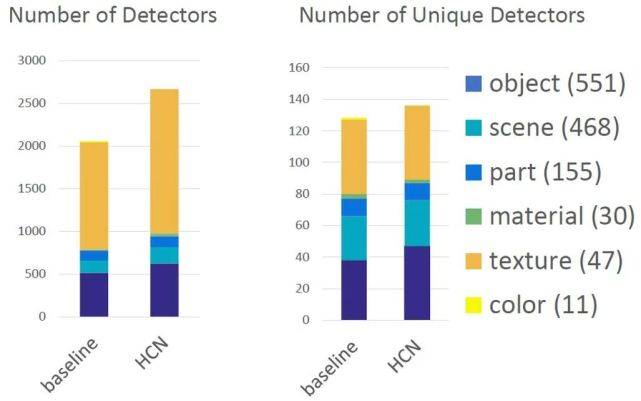
文章图片
图 4. 模型学习到的属性数量的定量评估结果
针对属性响应区域的可视化结果(图 5)也显示 , 模型学到的属性基本上是可靠的 。 图中响应最强的区域(红色部分)也正是和属性对应的区域 。

文章图片
图 5. 属性响应区域可视化
3. 规则学习结果和人工先验引入
实验中 , 作者展示了模型下边的分支学习到的分类规则 , 将每个类别表示成「父类 + 特定属性组合」的形式 , 如图 6 所示 。 模型学习到的结果中包括:
(1)「钟表」是一种圆形的、放射状的「家用电子设备」;
(2)「猎豹」是一种有条纹、斑点的「猫科动物」;
(3)「足球」是一种在白色背景上有黑色斑点的「球」 。
模型给出的解释规则基本符合人的认知 , 表明模型可以学到类似于分类学家定义的「父类 + 特定属性组合」形式的分类规则 , 可以对模型的分类原理给出人类可理解的解释 。

文章图片
图 6. 模型学习到的解释规则展示 。 (a)CIFAR-100 数据库上学习到的解释规则;(b)ILSVRC 数据库上学习到的解释规则
相比之下 , 现有方法 [4] 如果想要给出同样形式的解释结果 , 需要人工标注每个类别的属性表示 , 而这在大规模场景下显然是不现实的 , 作者在实验中也展示了相应的对比结果(表 1) , 从对比结果来看 , 论文中提出方法的适用范围显然更广泛 。

文章图片
表 1. 与现有方法 [4] 对比
有了上边这种人类可以理解的解释规则 , 就可以对模型进行定制化的调优 , 去除模型不应该利用的规则 , 补充模型没有学习到的规则:
在 ILSVRC 数据的「救护车」和「猎豹」两个类别上尝试了去除模型学到的错误规则的方案 , 该方案在基本不影响其他类别识别效果的前提下 , 可以提升模型在「救护车」和「猎豹」两个类别上的识别精度;
在同一个数据库的全部类别上 , 作者尝试了补充额外属性的方案 , 并得到了约 2 个百分点精度提升 。
上边两个实验表明 , 作者提出的方法虽然只是在深度模型引入人工先验方面做了一些初步的探索 , 但是已经验证了深度模型和人工先验知识结合的有效性 , 并且给出了一条基本可行的技术路线 。
结论
可解释的深度学习模型 , 以及深度学习模型与人工先验的结合是当前学术界重点研究的前沿方向 , 对于提升深度学习模型的可靠性和泛化能力具有重要的意义 。 这次介绍的论文同时在这两个方向上迈出了坚实的一步:在可解释深度学习模型方面 , 相比于现有方法 , 不仅能够给出图像中的关键区域 , 还能给出规则化的解释 , 对使用者更友好 , 更符合人对于解释结果的期望;在引入人工先验知识方面 , 走通了一条基本可行的技术路线 , 希望能够对未来的研究者有所启发 。
参考文献
[1] C. Huang, C. C. Loy, and X. Tang, “Unsupervised learning of discriminative attributes and visual representations,” in Computer Vision and Pattern Recognition (CVPR), 2016, pp. 5175–5184.
[2] V. Escorcia, J. C. Niebles, and B. Ghanem, “On the relationship between visual attributes and convolutional networks,” in Computer Vision and Pattern Recognition (CVPR), 2015, pp. 1256–1264.
[3] S. Vittayakorn, T. Umeda, K. Murasaki, K. Sudo, T. Okatani, and K. Yamaguchi, “Automatic attribute discovery with neural activations,” in European Conference on Computer Vision (ECCV), 2016, pp. 252–268.
【类别|华为云IEEE TPAMI论文解读:规则化可解释模型助力知识+AI融合】[4] S. J. Hwang and L. Sigal, “A unified semantic embedding: Relating taxonomies and attributes,” in Advances in Neural Information Processing Systems (NIPS), 2014, pp. 271–279.
推荐阅读




- 微信|积极落实互联互通,微信收款码支持云闪付及银行APP支付物料落地
- 样儿|从太空看地球新年灯光秀啥样儿?快看!绝美风云卫星图来了
- 技术|使用云原生应用和开源技术的创新攻略
- MateBook|深度解析:华为MateBook X Pro 2022的七大独家创新技术
- 微信|微信支付“九宫格”全面支持开通中国银联云闪付
- 科技创新平台|云南:打造世界一流食用菌科技创新平台
- 果君|华为Mate X2 典藏版竟逼疯整个摄制组?拯救手滑的神器终于来了(视频)
- 测评|【横评】5年前的老机型测评 苹果华为三星小米魅族一加现在卡吗
- 警告!|华为联想卷入滴滴高管千万受贿案 判决书曝光浪潮曾向其输送720多万
- 娱乐|华为智慧屏迎来“影音娱乐”场景三大升级