作者:UT Austin三年级博士生 王浩韬
NeurIPS 2020 文章专题
第·8·期
对抗学习算法被广泛用于提升深度网络的鲁棒性 , 然而却以牺牲模型准确度为代价 。 部署在终端的同一个神经网络在不同情境下可能有不同的鲁棒性与准确率需求 。
本文提出的One-for-all Adversarial Training (OAT) 算法得到的模型可以在运行时根据用户需求自由调节鲁棒性与准确率 。 相比于针对不同鲁棒性要求而单独训练的一系列模型 , 用OAT得到的一个单独可调节模型的鲁棒性与准确率均相当甚至更好 。
「NeurIPS 2020群星闪耀云际会·机构专场」 火热报名中 , 点击【这里】 马上报名~

文章图片
https://arxiv.org/abs/2010.11828
https://github.com/VITA-Group/Once-for-All-Adversarial-Training
一、 背景和动机
在众多提升模型鲁棒性的算法中 , 对抗训练 (adversarial training) 的效果是最顶尖的 。 虽然传统对抗防御方法(包括对抗训练)可以提升鲁棒性 , 但是他们也有明显的缺点:大多数对抗防御方法(包括对抗训练)以牺牲模型准确率为代价获得鲁棒性 。 这些算法在不同的预设超参数下训练来实现在准确率和鲁棒性之间不同程度的折衷(trade-off) 。
然而在实际应用中 , 用户对于模型准确率和鲁棒性的要求不是一成不变的 , 而是会随着情境不同而变化 。 因此 , 实际应用中的模型需要能够在运行时灵活调整模型准确率与鲁棒性之间折衷度 。 不幸的是 , 大多数对抗防御算法的训练耗时很长 , 因此通过在不同预设参数下训练多组不同折衷度的模型是难以实现的 。
基于上述原因 , 本文首次提出并解决一个新的问题:如何快速原位调整一个已经训练好的模型 , 无需在不同预设参数下多次训练 , 即可使其实现在运行时灵活调节准确率与鲁棒性之间的折衷度?
二、方法
1. 核心思路:训练样本与模型条件参数的联合采样
传统对抗学习算法的损失函数为如下形式 , 其中是标准训练样本上的损失函数 , 是对抗训练样本上的损失函数 , 预设的固定超参数λ控制准确度与鲁棒性之间的折衷:
在我们提出的Once-for-all Adversarial Training (OAT) 框架中 , 超参数λ同时作为网络的条件控制参数(如图1所示) 。 在训练时 , 训练样本和模型条件参数λ联合采样 。 OAT损失函数如下 , 其中是为λ预设的采样分布:
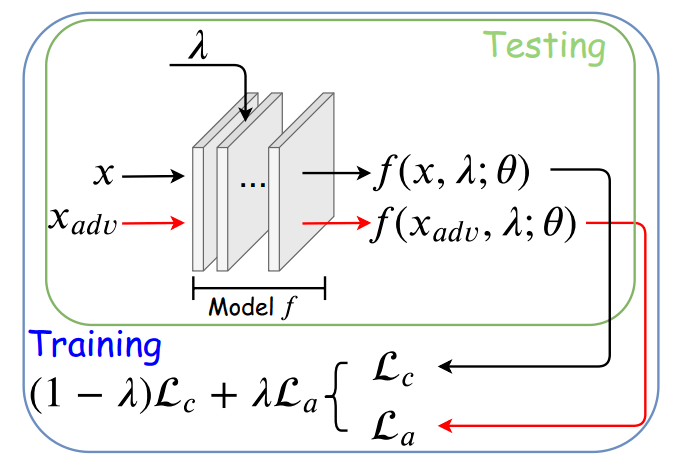
文章图片
图1. OAT的整体框架 。 λ既是损失函数中控制折衷度的超参数 , 也是模型的条件输入参数 。 训练时λ随机采样 , 测试时可根据用户不同的鲁棒性和准确率需求设置不同的λ数值 。
2. 独特的技术瓶颈与解决方案:标准样本和对抗样本统计特征上的差异
通过初步OAT框架得到的结果虽然可以实现通过调整λ来调整折衷度 , 但是可实现的折衷度远远达不到使用固定λ训练得到的模型效果好 。 通过观察 , 我们发现这是由于标准样本和对抗样本在统计特征上存在明显差异(参见图2)而导致的 。
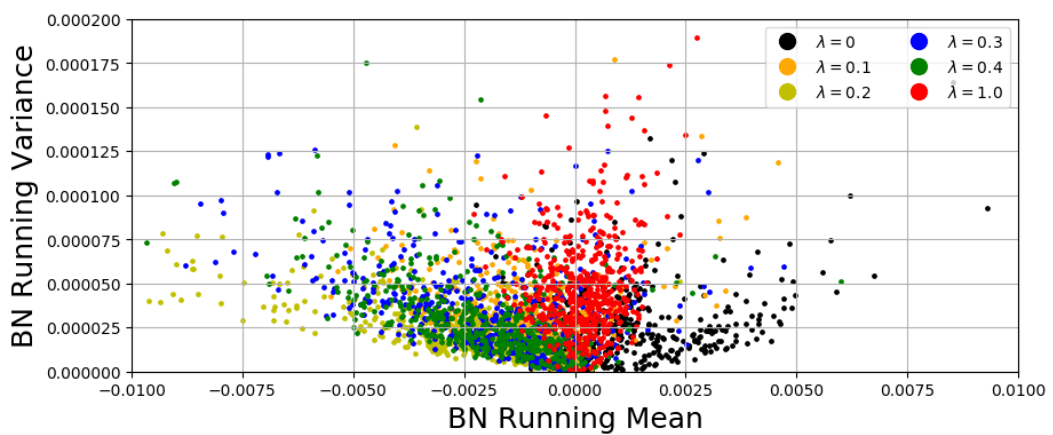
文章图片
图2. CIFAR10数据集上正常样本 (λ=0) 和对抗样本 (λ≠0) 的Batch Normalization层的均值 (x轴) 和方差 (y轴) 。 可见正常样本与对抗样本统计分布差异很大 。
基于上述观察 , 我们利用双Batch Normalization (BN) 模型结构[1] (参见图3) 来解耦正常样本和对抗样本的BN统计参数:负责统计标准样本的统计矩 , 负责统计对抗样本的统计矩 。 我们将网络中所有BN层替换为双BN结构 。 在训练和测试时 , 每个样本根据λ值的不同选取不同的传播路径:λ=0则传入 , λ≠0则传入 。 双BN结构分离了两类不同样本的统计矩 , 解决了两类样本统计特征相互冲突的问题 , 进而极大提升OAT框架效果 。
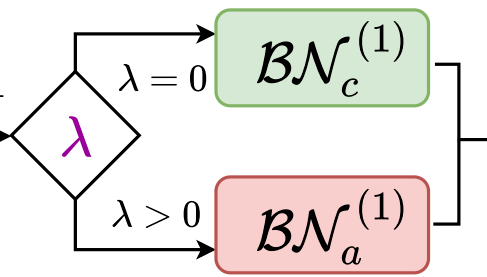
文章图片
图3. 双BN结构:每个样本根据λ值的不同选取不同的传播路径 。
3. 从OAT到OATS:加入模型运行效率作为第三个折衷维度
很多资源紧缺型设备(比如移动端设备 , 智能摄像头 , 户外机器人等)上部署的深度网络对与模型准确度 (accuracy) , 鲁棒性 (robustness) 以及运行效率 (efficiency) 都有严格要求 。 并且近期工作[2][3]指出在同一个模型上同时实现三者的重要性 。
鉴于此 , 我们将OAT框架拓展到Once-for-all Adversarial Training and Slimming (OATS) 框架 , 来实现自由调整模型在准确度、鲁棒性、运行效率三者之间的运行时折衷的目的 。 我们借鉴Slimmable Network [4]中的switchable BN来实现模型宽度的调整 。 OATS框架如图4所示 。
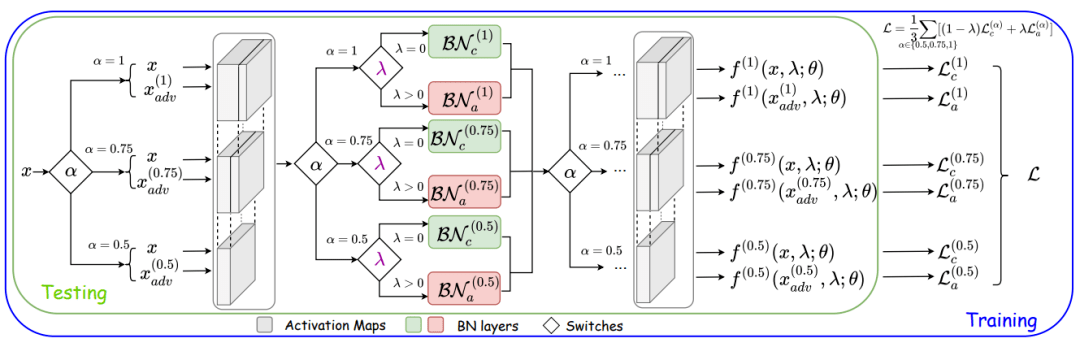
文章图片
图4. OATS框架 。 超参数λ与α(神经网络宽度参数)均为模型输入参数 。 λ控制模型使用或是 。 α控制使用何种宽度的子模型 。
OATS算法概要如下:

文章图片
三、实验结果
在双BN (dual BN) 的帮助下 , OAT算法只需一次训练即可得到与固定不同λ训练多个模型 (PGD-AT) 相近甚至更好的准确率-鲁棒性帕累托最优 (Pareto Frontier) 曲线 , 如图5所示 。
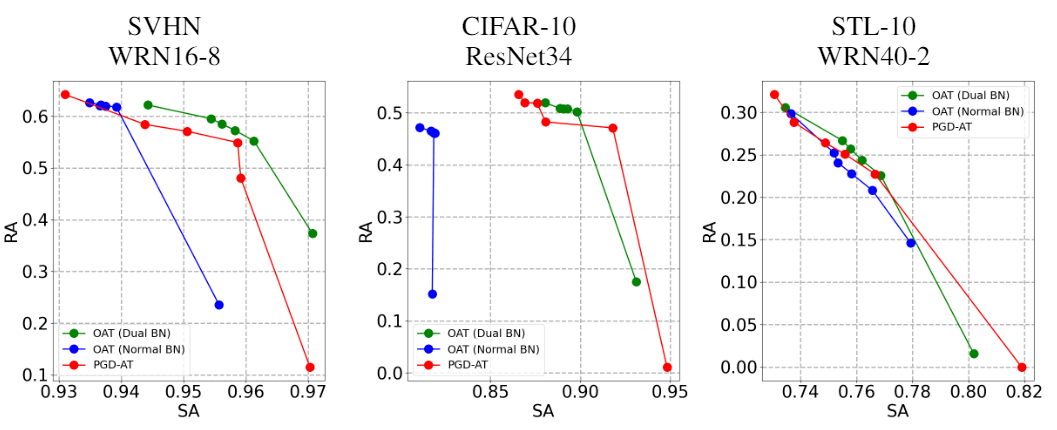
文章图片
图5. 准确率 (SA) -鲁棒性 (RA) 帕累托最优 (Pareto Frontier) 曲线 。 OAT比传统固定λ的对抗训练算法 (PGD-AT) 效果相当甚至更好 。
OATS框架下也有相同的结论 , 如图6所示:
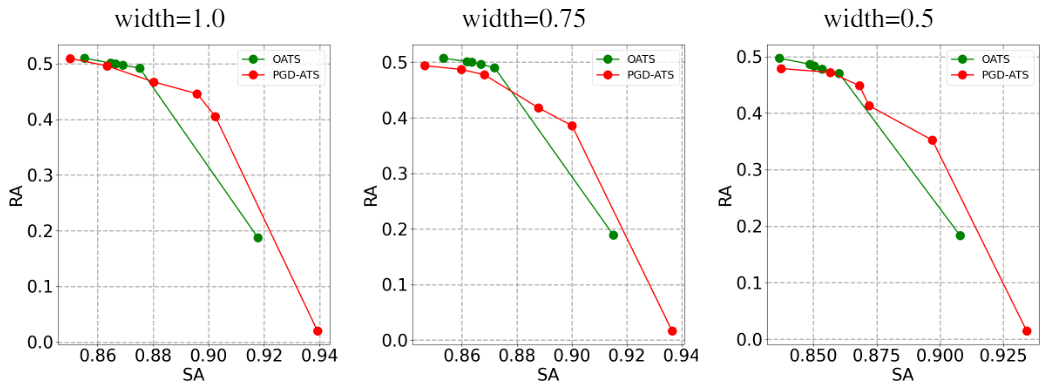
文章图片
图6. 准确率 (SA) -鲁棒性 (RA) 帕累托最优 (Pareto Frontier) 曲线 。 OATS对比传统固定λ的对抗训练算法 (PGD-ATS) 效果相当甚至更好 。
更多实验结果与可视化结果请参看原文 。
四、总结
本文尝试解决一个新的问题:如何在运行时自由原位调整模型准确率和鲁棒性之间的折衷度 。 我们提出的OAT算法基于创新性的模型条件化对抗训练算法 , 并且使用双BN模型来解决标准样本和对抗样本之间统计特征冲突的问题 。 我们进一步将OAT拓展到OATS框架 , 实现了在运行时自由原位调整准确率、鲁棒性、运行效率三者之间折衷 。 大量实验验证了我们方法的有效性 。
滑动查看参考文献!
[1] Cihang Xie, Mingxing Tan, Boqing Gong, Jiang Wang, Alan Yuille, and Quoc V Le. Adversarial examples improve image recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 819-828, 2020.
[2] Shupeng Gui, Haotao Wang, Haichuan Yang, Chen Yu, Zhangyang Wang, and Ji Liu. Model compression with adversarial robustness: A unified optimization framework. In Advances in Neural Information Processing Systems (NeurIPS), pages 1283–1294, 2019.
[3] Ting-Kuei Hu, Tianlong Chen, Haotao Wang, and Zhangyang Wang. Triple wins: Boosting accuracy, robustness and efficiency together by enabling input-adaptive inference. In International Conference on Learning Representations (ICLR), 2020.
[4] Jiahui Yu, Linjie Yang, Ning Xu, Jianchao Yang, and Thomas Huang. Slimmable neural networks. In International Conference on Learning Representations (ICLR), 2019.
//
作者介绍:
【准确率|?UT Austin&快手提出Once-for-All对抗学习算法实现运行时可调节模型鲁棒性】王浩韬 , UT Austin三年级博士生 。 研究兴趣:对抗学习 , 深度学习鲁棒性 , 模型压缩等 。
推荐阅读







- 娱乐|SensorTower:视频&直播 App 成 2021年娱乐类主流,TikTok占最多
- 人工智能|正片来了!五期「AI大咖说」第一期,探秘清华大学AI&机器人实验室
- Microsoft|微软收购AT&T广告部门:迎接“后Cookie”时代
- 演讲|T11数据智能峰会完整议程&精彩主题 抢先看!
- 场景|5G&智能,想象有限,未来无限
- 媒体播放器|神级老软件竟要重返江湖 Winamp还能成功吗?
- 货运|日本航空公司获得CHAMP的5年期扩展合作
- 摄影|征稿启事 | 「协力&适应」 理光、海大、富图宝邀请大家投稿2021年度作品
- 通信运营商|AT&T推出“贪吃蛇”AR滤镜以努力推广其5G网络的功能
- Web|亚马逊云科技发布Amazon Amplify Studio