From: arxiv;编译: T.R
近日 ,谷歌AI联手 DeepMind提出 Performer , 这是一种线性扩展的人工智能模型架构 。 它在蛋白质序列建模等任务中表现良好 , 有望影响生物序列分析 , 降低计算成本、减少能源消耗和碳排放 。
研究人员提供了论文、Performer的代码和蛋白质语言模型代码的链接 , 如果想要了解更多信息 , 可以参看下面的资料来源 。

文章图片
https://arxiv.org/abs/2009.14794
Performer代码链接:
http://github.com/google-research/google-research/tree/master/performer
蛋白质语言模型代码链接:
http://github.com/google-research/google-research/tree/master/protein_lm
近年来 , Transformer模型在自然语言、对话、图像和音频处理方面得到了迅速的发展 , 它的核心是注意力模块 , 计算了对输入序列所有匹配位置的相似性得分 。
但是 , 这种方法对于输入序列长度的增长无法有效地规模化 , 因为它需要计算时间呈平方增长来产生所有相似性得分 , 以及存储空间的平方增长来构造一个矩阵来存储这些得分 。
为了适应实际应用中长程注意力的需求 , 许多兼具效率和速度的技术 (如内存、缓存) 被提出 , 但更为通用的方法是基于 稀疏注意力机制来实现 。
稀疏注意力机制选择性地计算输入序列中的相似性分数 , 而非计算全部可能的配对 , 因此减少了计算时间和内存消耗 , 从而产生一个稀疏矩阵作为结果 。 这些稀疏条目可以通过优化的方法找到并被学习 , 甚至随机化 , 如Sparse Transformers、Longformers、Routing Transformer、Reformers和BigBird 。
由于稀疏矩阵也可以通过图形和边来表示 , 稀疏方法同样也收到图卷积网络的启发 , 在图注意力网络中概述了与注意力机制的特定关系 。 这些基于稀疏性的架构通常需要额外的层来隐式地产生完整的注意力机制 。
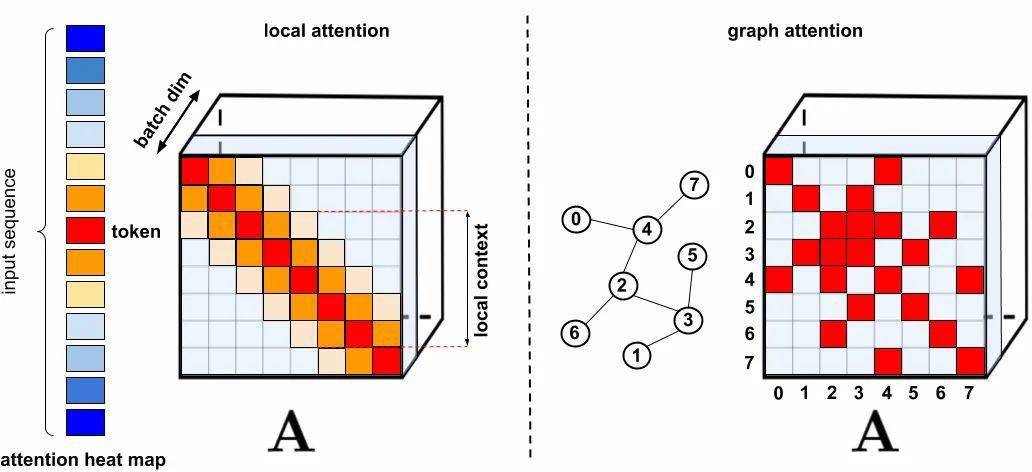
文章图片
标准化稀疏技术 。 左图:稀疏样本 , tokens仅仅关注邻近区域;右图:在图注意力网络中 , tokens仅仅关注图上的高相关性的相邻区域节点 。
但稀疏注意力的方法却依旧存在一些局限 , 如:
- 稀疏方法需要高效的乘法操作 , 但大多加速器都无法实现;
- 他们通常不能为表示能力提供严格的理论保证;
- 他们通常不是主要针对Transformer模型进行优化和预训练的;
- 需要堆叠更多的注意力层来补偿稀疏表示 , 使得他们难以使用其他预训练模型 。
为了解决这一问题 , Google AI的研究人员引入了一种基于Transformer改进的具有线性规模特性的 Preformer , 使模型可以在处理更长序列的同时实现更快的训练 , 这是特定的图像数据集 (如ImageNet64) 和文本数据集 (如PG-19) 所必需的 。
Performer使用了一个高效的 (线性的) 通用注意力框架 , 使基于不同相似性度量(kernels) 的更广泛的注意力机制得以实现 。
这一框架基于正向正交随机特征算法实现的最新Fast Attention构建 , 为注意力机制提供了规模化、低方差和无偏的估计 , 可以利用随机特征图分解来表达 (regular softmax-attention) 。 这种方法可以强有力地保证精度 , 同时保持空间和时间复杂度 , 也可被用于独立的softmax操作 。
通用注意力机制
在原有的注意力机制里 , query和key分别对应矩阵的行和列 , 相乘后在softmax操作下构成注意力矩阵 , 保存了相似性分数 。
但在这种方式的作用下 , 我们无法将通过softmax作用后的query-key乘积分解为原始的query与key 。 然而 , 可以将注意力矩阵分解为原始query-key序列与随机非线性函数的乘积 , 也称为随机特征 (random features) , 可以更为高效地编码相似性信息 。
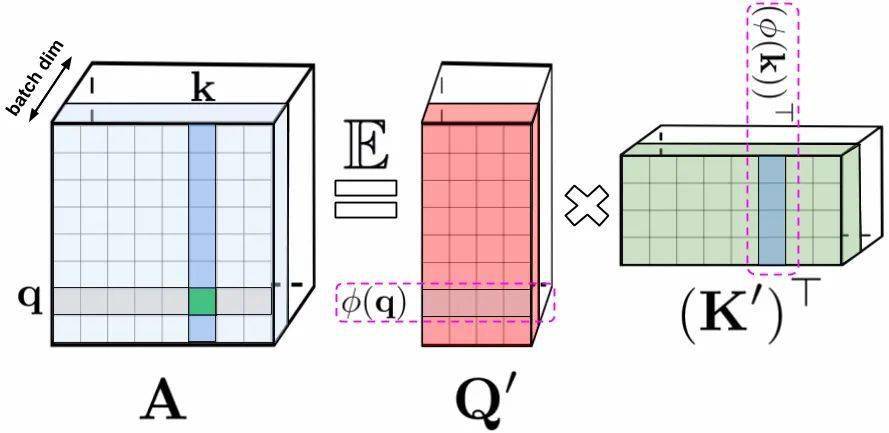
文章图片
LHS:标准的注意力矩阵 , 包含了所有输入的相似性得分;RHS:标准的相似性矩阵 , 可通过随机非线性函数编码的随机化矩阵Q’和K’来近似 。 对于常规softmax注意力机制来说 , 这种变化非常紧凑 , 并引入了指数函数和随机高斯投影 。
常规的softmax注意力可被视为通过指数函数和高斯映射定义的非线性函数特例 。 值得注意的是 , 还可以通过更为通用的非线性函数来实现逆向推理 , 在query-key的乘积上隐式地定义其他类型的相似性度量 (核) 。 基于早期的核方法 , 研究人员将其概括为通用注意力机制 。 尽管针对大多数核 , 不存在封闭形式的公式 , 但由于这一机制不依赖于封闭公式仍然可以在实际中有效应用 。
这是研究领域首次证明:可利用随机特征将任意注意力矩阵近似应用于下游Transformer中去 。 正随机特征 (如原始query和key的正非线性函数) 的应用使得这种新颖机制得以实现这些功能 , 这对于避免训练过程中的不稳定性至关重要 , 同时也为常规softmax注意力机制提供了更精确的近似 。
FAVOR+:基于矩阵结合律的快速注意力机制
上文描述的矩阵分解 , 使得可以使用线性 (而不是平方) 复杂度隐式地存储注意力矩阵 , 利用矩阵分解可以得到线性时间复杂度的注意力机制 。
原有的注意力机制是将输入的value与注意力矩阵相乘来得到最终结果 , 但在注意力矩阵分解后 , 可以重新排列矩阵乘法来逼近常规注意力机制的结果 , 而无需显式地构建二次的注意力矩阵 。 基于这样的分析 , 研究人员构建出了新的注意力机制:FAVOR+ 。
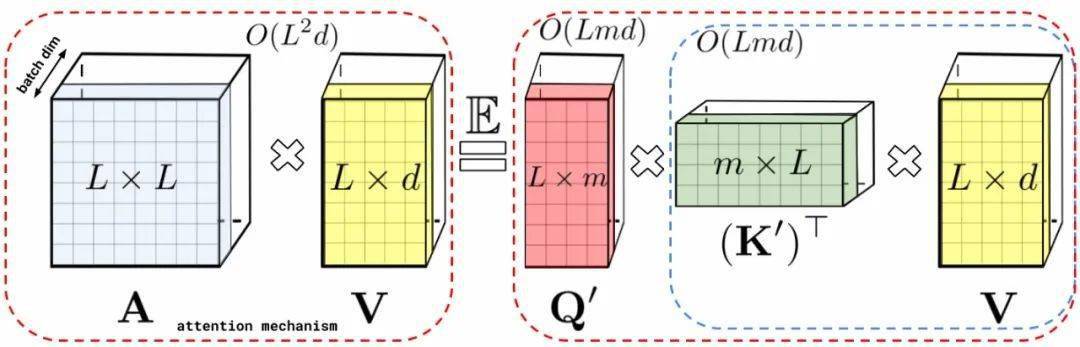
文章图片
左图是标准的注意力计算 , 最终结果由值矩阵V和注意力矩阵A相乘得到;右图则是基于低秩分解注意力矩阵A后得到的Q’和K’与值矩阵V相乘 , 得到的最终具有线性复杂度的注意力机制 。
上述分析与所谓的双向注意力有关。 双向注意力 , 即没有过去和未来概念的一种非因果注意力机制 。 针对单向 (因果) 注意力而言 , token不与序列后其他token发生注意力 。 利用prefix-sum计算将这种方式稍加改进 , 仅仅存储矩阵运算的运行总和 , 而不显式地保存下三角正则注意矩阵 。
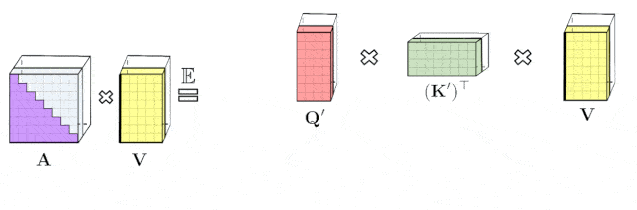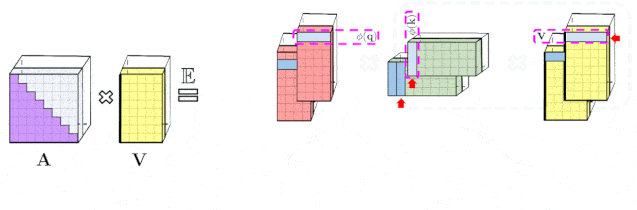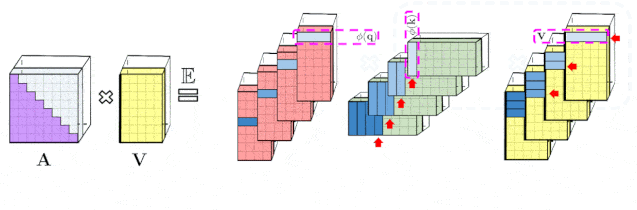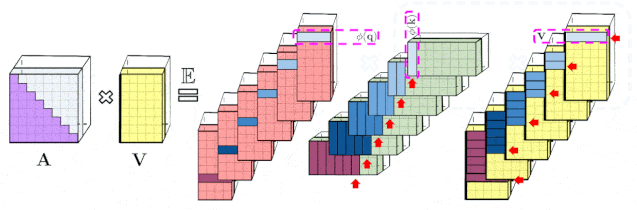
文章图片
左图显示的是 , 标准的单向注意力需要注意力矩阵掩膜以获得其下三角部分 。 右图显示的是 , 可以通过prefix-smu机制获得LHS的无偏逼近 , 其中键和值向量随机特征图的外积prefix-smu是动态生成的 , 并与query随机特征向量左乘来获取最终结果矩阵中的新行 。 实验特性
研究人员首先测评了Preformer的时间、空间复杂度 。 实验表明 , 注意力加速和内存减少几乎是最优的 。 也就是说 , 结果非常接近于在模型中根本不使用注意力机制的简单模型 。
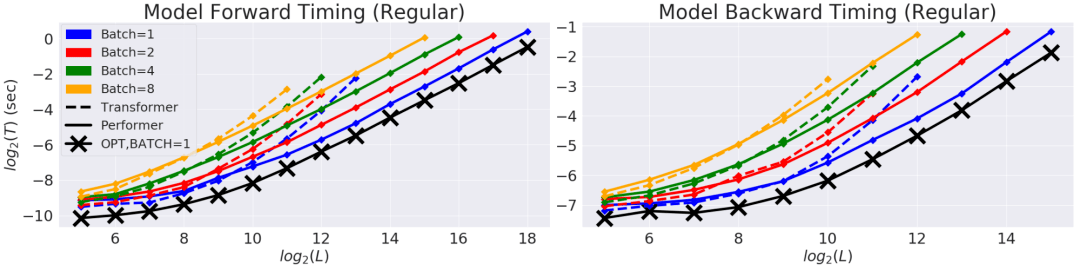
文章图片
上图所示为常规Transformer模型的前向和反向传播时间与序列长度的对数曲线 。 曲线结束位置受限于GPU内存限制 , 黑色叉线表示使用虚拟注意力模块时最大可能的内存压缩和加速结果 。 但它实际上绕过了注意力计算来描述了模型可能的最大效率 。 Performer (黑线) 模型几乎可以达到注意力模块最优的结果 。
研究进一步显示 , 利用无偏softmax近似时 , Performer经过一部分调优后能在反向传播上与预训练的Transformer模型匹配 , 具有通过提升推理速度来降低能耗的潜力 , 而无需完全重新训练已有模型 。
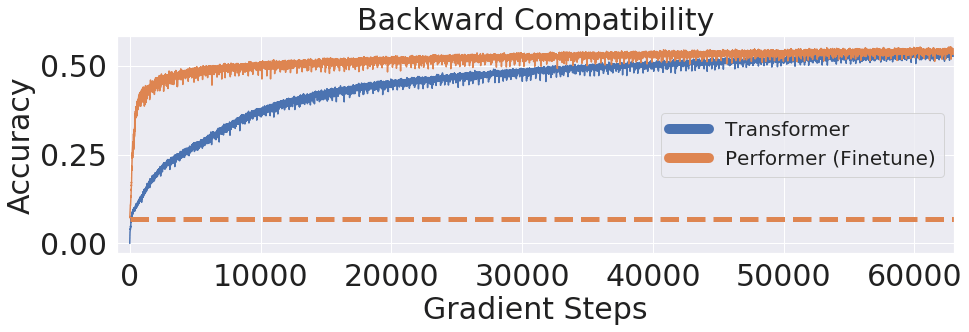
文章图片
上图显示 , 基于LM1B数据集 , 将预先训练的Transformer权重迁移到Performer上 , 其初始精度为0.07 (虚线) ,但微调后Performer的精度迅速提升 。
应用实例:蛋白质序列建模
蛋白质是具有复杂3D结构的生物大分子 。 蛋白质可以像单词一样被视为线性序列 , 其中每个字符都是20个氨基酸之一 。
将Transformers应用于大型未标记的蛋白质序列语料库 (例如UniRef) 进行训练 , 就能产生可准确预测折叠的功能性大分子的模型 。 Performer-ReLU (基于ReLU的注意力 , 与softmax不同的通用注意力机制) 在对蛋白质序列数据进行建模时表现非常出色 , 而Performer-Softmax与Transformer的性能相匹配 , 这一结果与理论预测相一致 。
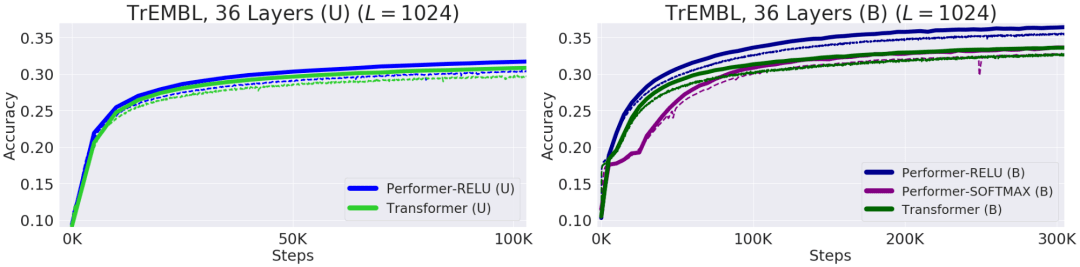
文章图片
上图所示为不同模型对蛋白质序列建模的性能表现 。 实线是验证曲线 , 虚线是训练曲线 。 单向模型用U表示 , 双向模型用B表示 。 实验中使用了ProGen (2019) 中的36层模型参数 , 每次试验均使用16x16的TPU-v2 。 在给定相应的计算约束下最大化每次运行的batch大小 。
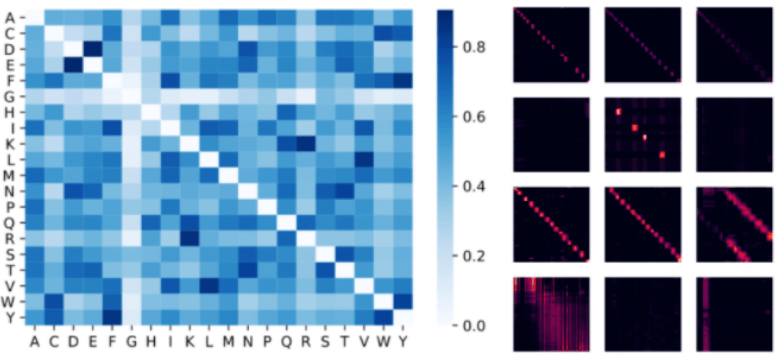
文章图片
上图可视化了一个蛋白质Performer模型 , 使用基于relu的近似注意力机制进行训练 , 使用Performer来估计氨基酸之间的相似性 , 从序列比对中分析进化替换模式得到的替换矩阵中恢复类似的结构 。
此外 , 研究人员还发现局部与全局注意力机制与蛋白质数据训练的Transformer模型一致 。 Performer密集的注意力近似具有捕捉多个蛋白质序列全局相互作用的能力 。
作为原型验证 , Performer在长链的蛋白质序列上进行训练 , 这一长度会使Transformer内存过载 , 但Performer模型的内存不会过载 , 因为它的空间利用很高效 。
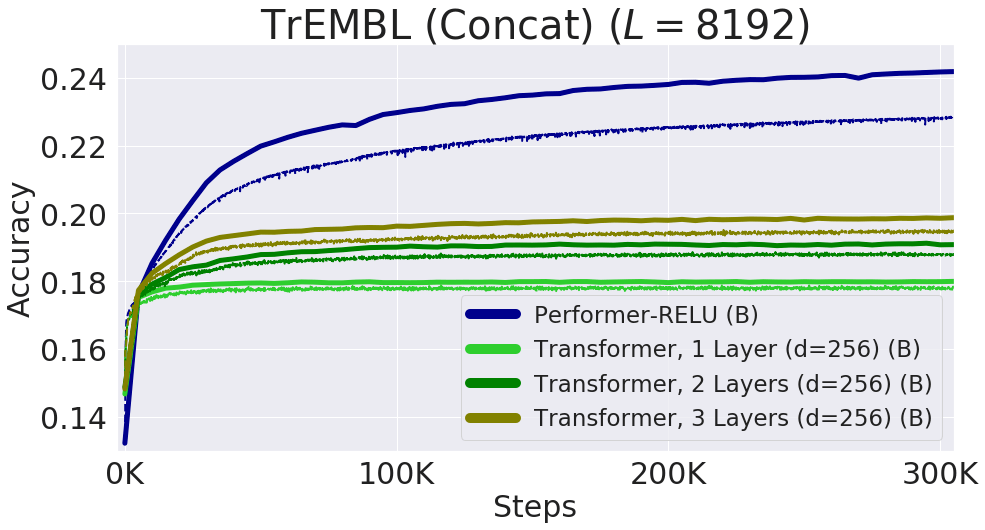
文章图片
上图所示为通过连接单个蛋白质序列获得的最大处理长度为8192的性能表现 。 为了适应TPU内存减小了Transformer的大小 (层数和嵌入维度) 。
结论
Google AI的这项工作提出的方法可与其他技术 (如可逆层) 进行相互操作 , 甚至可将FAVOR与Reformer的代码集成在一起 。 希望这一研究可以启发新的思维角度和新方法的出现 。
滑动查看参考资料!
【序列|谷歌AI联手DeepMind提出Performer: 对注意力机制的重新思考】https://arxiv.org/pdf/2009.14794.pdf
https://github.com/google-research/google-research/tree/master/protein_lm
https://github.comgoogle-research/google-research/tree/master/performer
https://github.com/google-research/google-research/tree/master/performer/fast_self_attention
推荐阅读







- Google|谷歌暂缓2021年12月更新推送 调查Pixel 6遇到的掉线断连问题
- Tesla|马斯克也要效仿谷歌Facebook 为特斯拉设立控股母公司?
- 最初的|微软指责谷歌“耽误”了Surface Duo安卓11的最后升级期限
- 数坤|两大企业联手 推动“智能健康管理”应用场景全面落地
- 数据|聚焦解决 “卡脖子”问题 三六零旗下国家工程研究中心纳入新序列
- 最新消息|AMD谷歌微星相继退出展会,CES还在坚持办线下活动
- Google|Chrome被起诉侵犯隐私 加州允许原告当庭质问谷歌CEO
- Google|谷歌母公司Alphabet成2021年股价涨幅最大科技巨头 全年上涨68%
- 最新消息|盖茨、谷歌参与投资 美国CFS公司开建核聚变电站2025年商业发电
- 用户|苹果 iPhone 现在也可以使用谷歌 Fit 测量心率和呼吸频率