机器之心专栏
机器之心编辑部
在本篇论文中 , 来自德州农工大学和快手的研究者提出了一种简单有效的探索算法 , 旨在为随机环境的探索问题提供有效的解决方案 。

文章图片
论文:https://openreview.net/forum?id=MtEE0CktZht
代码:https://github.com/daochenzha/rapid
探索是强化学习的经典问题 , 一个好的探索策略可以极大地提高强化学习的效率 , 节省计算资源 。
例如 , 在下图所示的迷宫中 , 智能体(红色三角形)需要从第一个房间出发 , 逐个打开通往下个房间的门 , 最终到达终点(绿色方块) 。 智能体所能得到的奖励是稀疏的 , 只有在到达终点的时候才能得到奖励 。 如果不能进行有效的探索 , 智能体就不知道什么动作是合适的 , 从而很容易困在前几个房间 , 陷入局部最优 。

文章图片
研究现状和分析
行业中处理探索问题最常用的方法是内部奖励(Intrinsic Reward)[2][3] 。 这种方法的基本逻辑是为首次发现的状态设计更大的奖励 , 从而鼓励智能体去探索未知区域 。 比如对于上面的迷宫问题 , 我们可以为没有进过的房间设计更大的奖励 , 从而让智能体自发地去探索更多的房间 。 然而 , 已有的内部奖励方法在随机环境中效果会大打折扣 。
例如 , 我们考虑在每个新的回合产生一个完全不一样的房间情形 。 下图展示了四个不同的回合 , 每个回合房间的结构都不一样 , 智能体遇到的每个房间几乎都是没见过的 , 内部奖励机制很难区分探索的好坏 。 因此 , 我们需要新的的算法去应对环境随机性问题 。 随机的环境能更好地建模很多现实中的问题 , 比如股票交易、推荐系统、机器人控制等 。
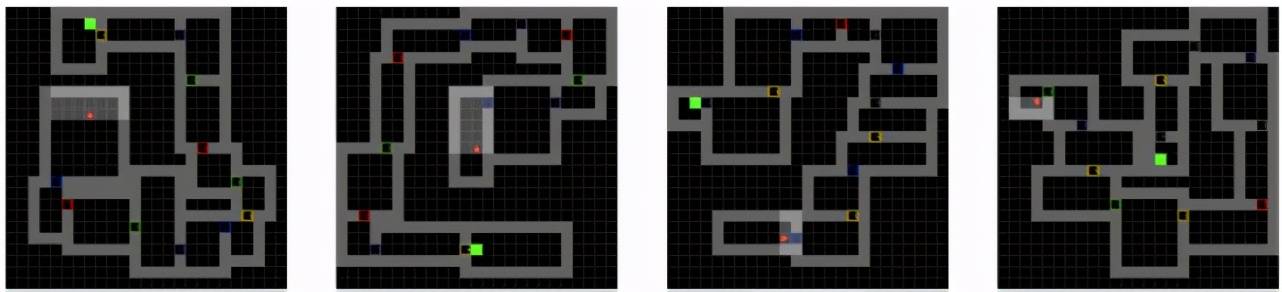
文章图片
为了解决这个问题 , 该论文提出了回合排序算法(Rank the Episodes , 简称 RAPID) 。
回合排序算法
如下图所示 , 研究者提出了一种为每个回合的探索动作打分和排序的机制 , 以选出好的探索行为 。
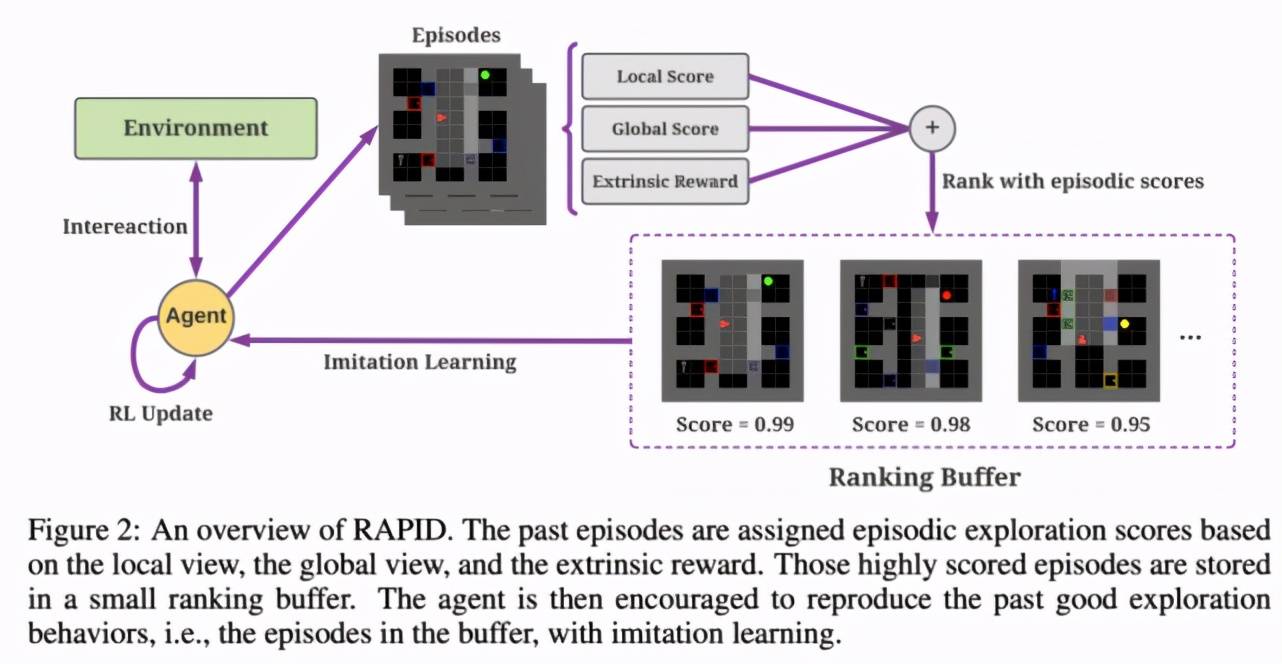
文章图片
对每个回合产生的数据 , 该算法从三个不同的维度为探索动作打分 。 从局部角度 , 算法通过计算覆盖率来打分 。 比如在上述迷宫中 , 该研究给访问更多房间的回合打更高的分 , 因为研究者希望算法能探索更多的房间 。 从全局角度 , 研究者希望每个回合尽量访问与之前不一样的状态 。 最后 , 算法考虑了外部的奖励大小 。 在这种迷宫环境中 , 能取得较好的外部奖励往往意味着探索较好 。
为了更好地利用这些好的探索行为 , 该研究设计了一个简单的缓冲器来暂存分数最高的一批数据 。 然后 , 算法利用模仿学习去复现这些比较好的探索行为 。 例如 , 如果一个回合访问了很多的房间 , 算法会通过模仿学习去再现这种好的探索行为 , 从而间接鼓励智能体探索更多的房间 。
回合排序算法可以有效地应对环境的随机性 。 首先 , 回合排序算法为整个回合打分 , 而不聚焦于某个具体的状态 。 这种整体的行为对随机性更加鲁棒 。 其次 , 缓冲器机制可以把一些好的探索行为存起来重复利用 , 因此一个好的回合可以被学习多次 , 这从另一方面提高了算法的效率 。
回合排序算法在随机环境中的效果
为了验证回合排序算法的有效性 , 该研究进行了大量的实验 。 在第一组实验中 , 该研究考虑了多个来自于 MiniGrid [4] 的不同难度的迷宫:
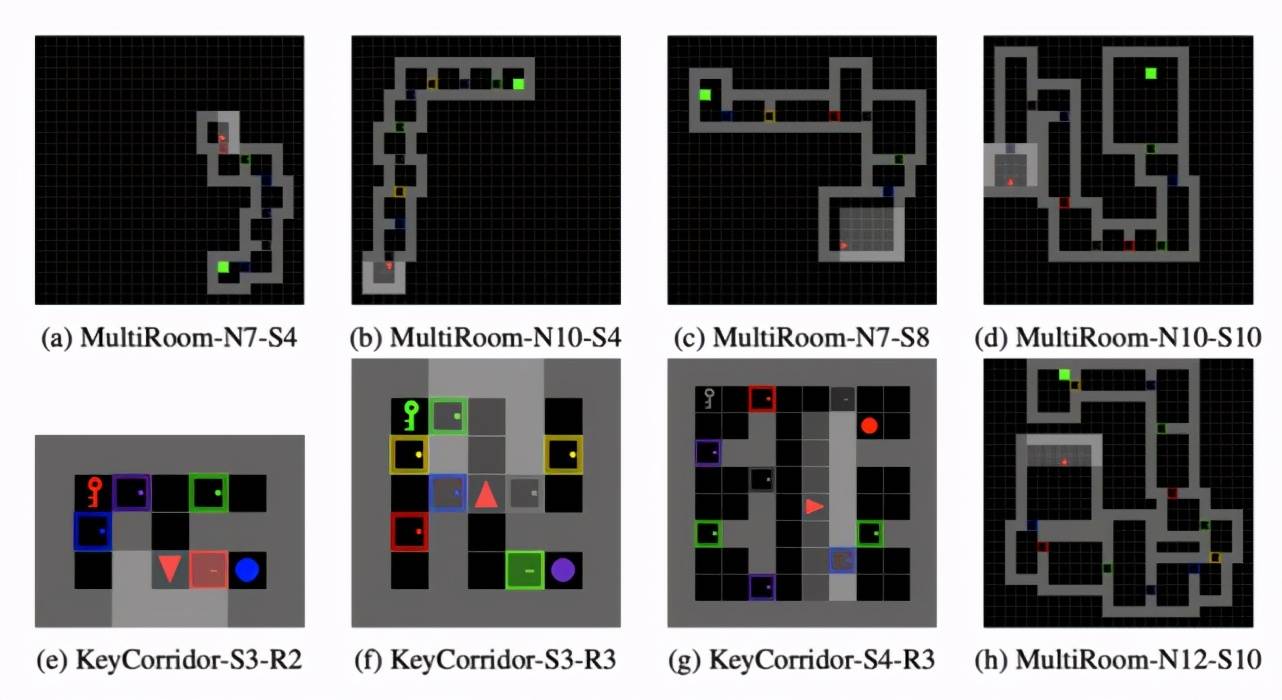
文章图片
研究者将回合排序算法和 SOTA 探索算法进行了比较 。 结果如下(其中 RAPID 为该研究提出的回合排序算法):
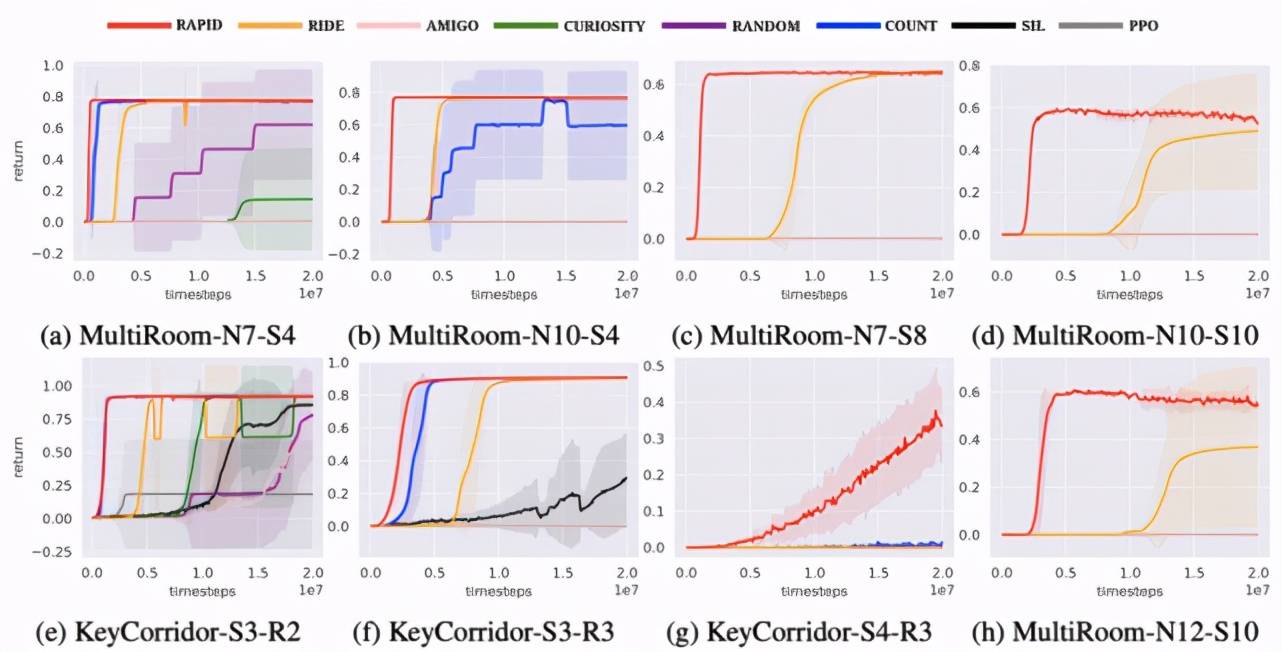
文章图片
这些环境中的数字(SX-RY)代表迷宫中房间的大小和数量 。 它们越大意味着环境越难探索 。 实验结果表明 , 回合排序方法在困难环境中的性能显著优于已有方法 。 比如在 MultiRoom-N7-S8 上 , 回合排序算法的学习速度比已有方法快十倍以上 。 在 KeyCorridor-S4-R3 上 , 回合排序算法是唯一有效的方法 。
在第二组实验中 , 该研究考虑了一个 3D 迷宫的情况 , 如下图所示 。 智能体看到的是一个第一人称视角的图片 。 类似的 , 迷宫的结构在每个回合会随机生成 。 智能体在这样的环境中需要学会怎么在原始的图片信息中探索 。

文章图片
实验表明回合排序算法显著优于已有方法 , 说明算法在原始图片上依然适用:
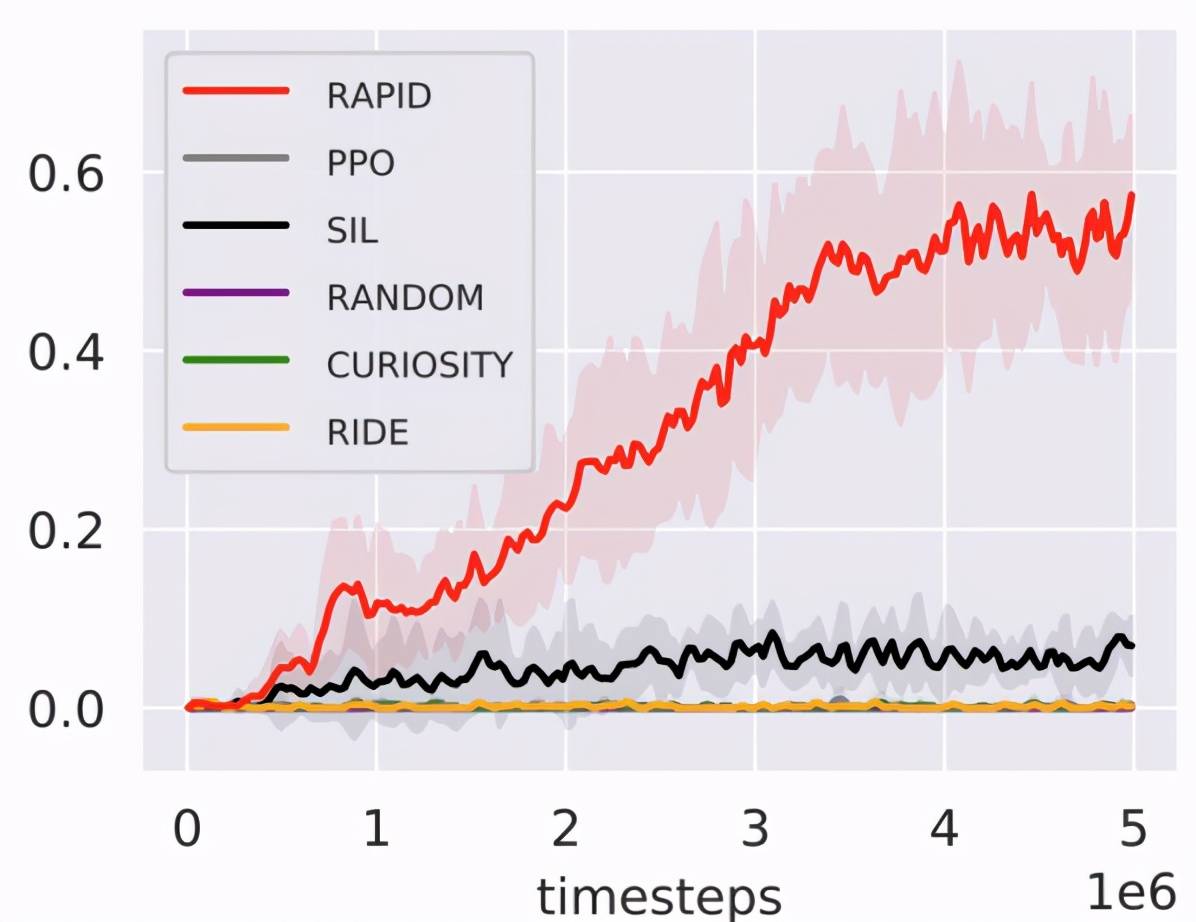
文章图片
回合排序算法在非随机环境中的效果
在第三组实验中 , 研究者探究了算法是否可以用于机器人控制 。 如下图所示 , 智能体需要操作机器人完成特定的任务 , 比如前进 , 跳跃 , 保持平衡等 。
【房间|设计简单有效的强化学习探索算法,快手有新思路】
文章图片
实验结果表明回合排序算法在这些非随机环境中依然有较好的效果:
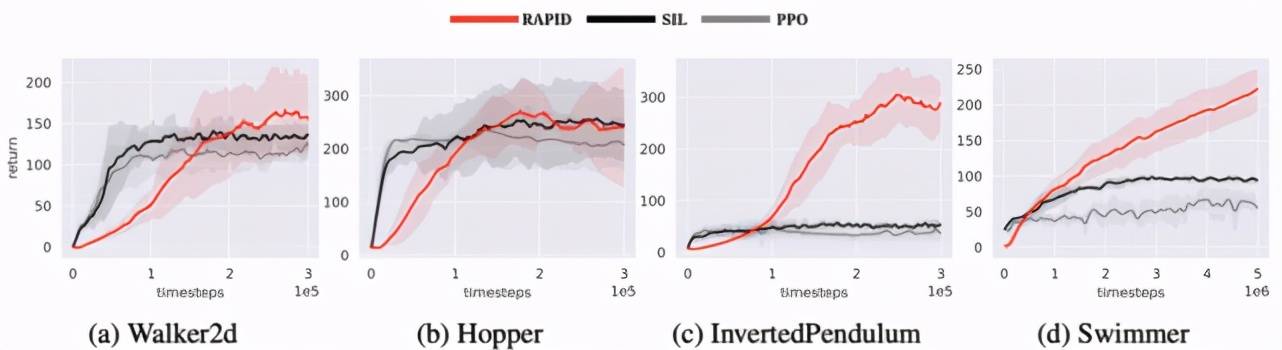
文章图片
总结
该研究为强化学习探索问题提供了一个新的解决思路 , 不同于以往基于内部奖励的方法 , 回合排序算法将好的探索行为记录下来 , 然后通过模仿学习鼓励智能体探索 。 初步结果表明 , 该方法具有非常好的效果 , 特别是在具有随机性的环境中 。
[1] Berner, Christopher, et al. "Dota 2 with large scale deep reinforcement learning." arXiv preprint arXiv:1912.06680 (2019).
[2] Pathak, Deepak, et al. "Curiosity-driven exploration by self-supervised prediction." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2017.
[3] Burda, Yuri, et al. "Exploration by random network distillation." International Conference on Learning Representations. 2018.
[4] Chevalier-Boisvert, Maxime, Lucas Willems, and Suman Pal. "Minimalistic gridworld environment for openai gym." GitHub repository (2018).
推荐阅读









- 代码|GGV纪源资本连投三轮,这家无代码公司想让运营流程变简单
- 平板|消息称 vivo 平板明年上半年推出:骁龙 870,四边等宽全面屏设计
- 设计|宇瞻发布 NOX 系列 DDR5 电竞内存,速度最高 7200MHz
- 圆角|诺基亚3310圆角设计,造型依旧经典
- 设计|腾讯宣布企业级设计体系 TDesign 对外开源
- Foxconn|富士康印度女工宿舍条件曝光:房间最多睡30人 月薪900
- 硬件|纽约设计师展示“风力涡轮机墙”将发电变成一种美学特征
- 架构|ROG 预热新款魔霸游戏本,依旧采用大下巴设计
- 方面|OPPO Find X5渲染图首次曝光:一脉相承的环形山后置设计
- IT|“宇宙中心”曹县终于开通第一条高铁 设计时速350公里