机器之心报道
作者:陈萍
Papers with Code 现在已经集成了 3044 个机器学习数据集 , 点点鼠标就能检索需要的数据集 。在机器学习中 , 数据集占据了重要的一部分 。 研究人员除了需要开发先进的算法外 , 其实数据集的建立才是最基础也是最重要的部分 。 在过往的研究中 , 机器学习从业者也建立了许多可用的数据集 。
在哪里可以找到比较好的数据集呢?
近日 , 查找论文对应开源代码的神器 Papers with Code 官网发布 , Datasets 已经实现了 3044 个机器学习数据集的汇总 , 并且按照不同的类型进行归类 , 还具有过滤功能 , 值得一看 。
文章图片
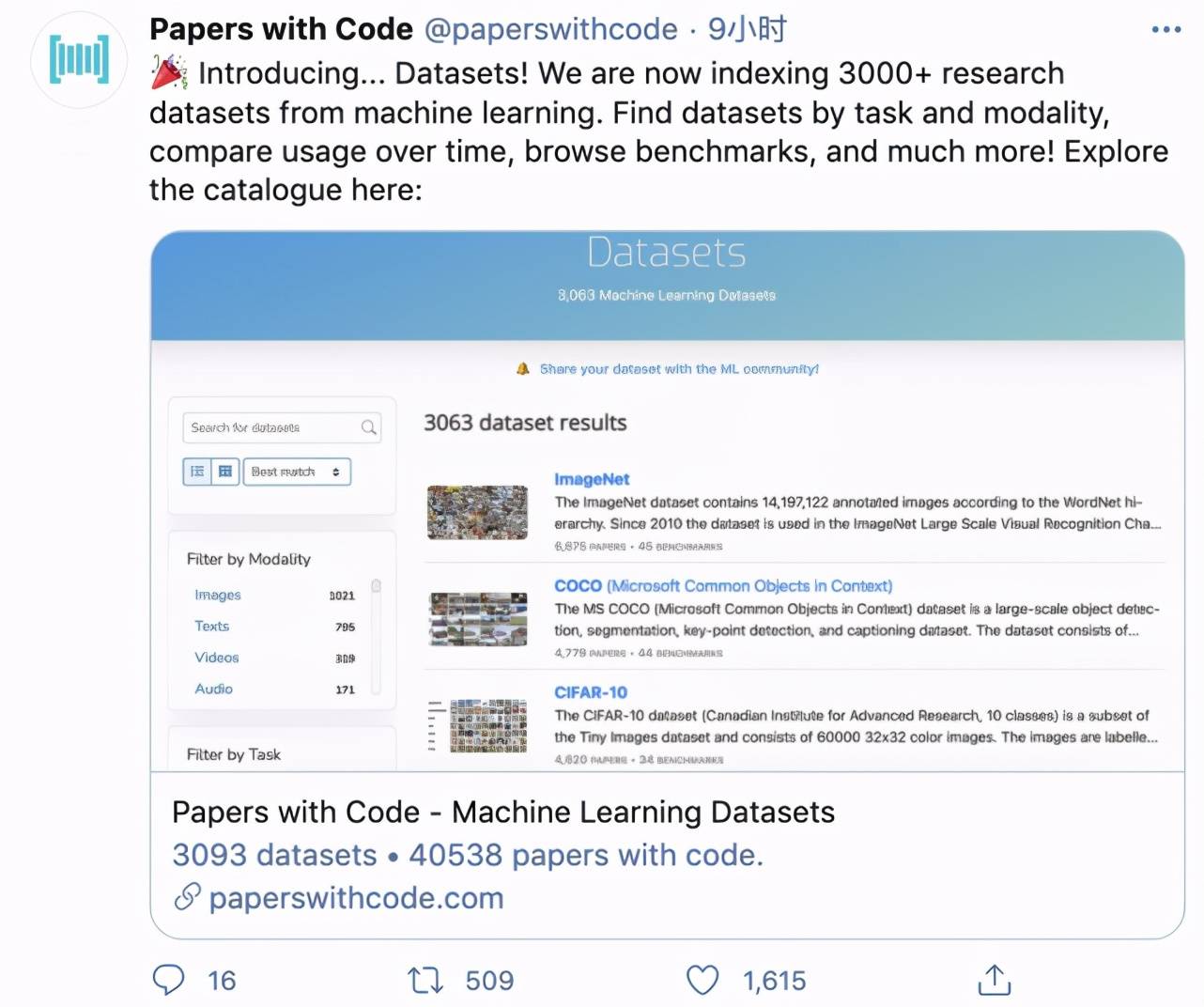
我们现在正在索引 3000 + 来自机器学习的数据集 。 使用者可以按照任务分类和模式进行数据集查找 , 还可以按照时间比较数据集的使用情况、浏览基准等要素进行查找 。
网站地址:https://www.paperswithcode.com/datasets
覆盖范围众多的数据集
在这 3044 个机器学习数据集里 , 不乏我们常用的经典数据集 , 例如 , ImageNet、COCO、CIFAR-10、MNIST 等 。

文章图片
快速检索
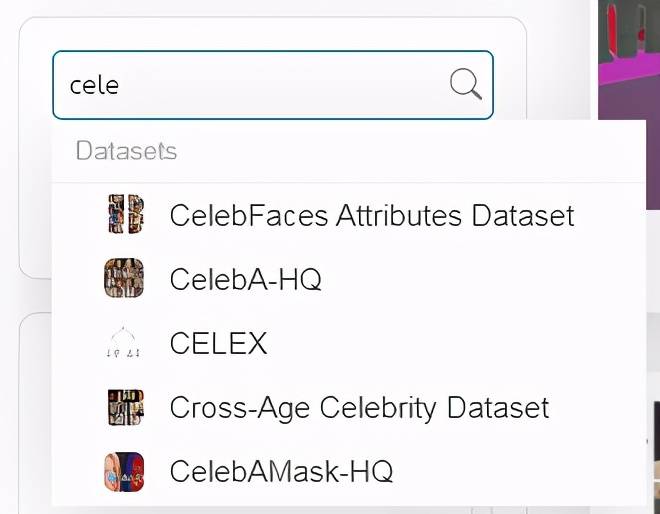
如果你想搜索指定的数据集 , 该网站也具备检索功能 , 例如从事计算机视觉的研究者 , 比较关心的是人脸数据集 , 这时就可以在搜索框敲入要搜索的内容 , 如果数据集的全拼你没有记住 , 也不用担心 , 只需键入几个字母 , 搜索栏就会出现相应的数据集 。
文章图片
键入 cele , 检索区域会出现相关的数据集
对数据集进行归纳整理
该 Datasets 对数据集进行了归纳整理 , 包含图像类、文本类、视频类等多个类别 。 以文本数据集为例 , 点击「Texts」选项 , 右侧页面会显示和文本相关的数据集 , 从检索结果可以看出 , 符合要求的有 828 个数据集 。

文章图片
按任务进行数据集过滤
机器学习研究分为不同的任务 , 我们都了解做自然语言推理任务的数据集不能用来进行机器翻译 。 怎样才能找到适合的数据集呢?Papers with Code 的 Datasets 具有该功能 , 该研究对 3044 个数据集根据任务进行了分类 。 包括问答、语言模型、视觉问答等 。
以左侧栏红框中标出的「Named Entity Recognition」为例 , 点击「Named Entity Recognition」 , 右侧页面检索出来有 28 个相关数据集 , 但它的检索条件是「Named Entity Recognition」以及「Texts」 , 如绿色框所示 。 如果你不想要这个检索条件 , 可以在设置「Texts」条件功能区内 , 将该条件取消 , 取消方式是点击「clear」 。

文章图片
根据语言进行过滤
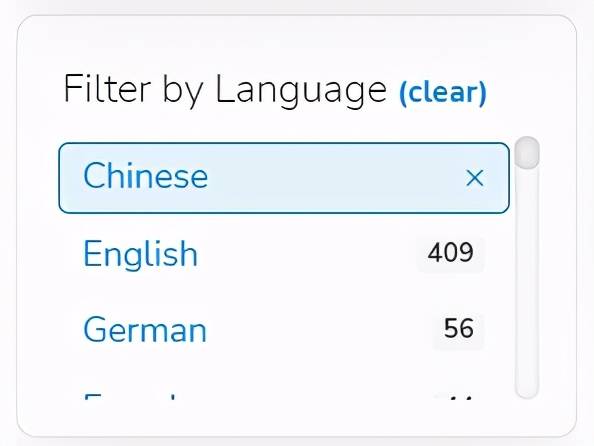
此外 , 使用者还可以根据语言类型进行数据集的过滤 , 包括中文、英文等 , 根据自己的需求选择合适的数据集 。 以中文为例 , 检索出 88 个数据集 , 在检索结果里 , 除了显示符合条件的数据集外 , 还显示了检索条件 , 如图中的红框所示「Chinese」 , 如果检索条件有多个 , 该条目会显示多个检索条件 。
【数据|Papers With Code新增数据集检索:3000+数据集,多种过滤功能】
文章图片
推荐阅读







- 区块|面向2030:影响数据存储产业的十大应用(下):新兴应用
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 数据|数智安防时代 东芝硬盘助力智慧安防新赛道
- 平台|数梦工场助力北京市中小企业公共服务平台用数据驱动业务创新
- 数据|中标 | 数梦工场以数字新动能助力科技优鄂
- 建设|数据赋能业务,数梦工场助力湖北省智慧应急“十四五”开局
- 市民|大数据、人工智能带来城市新变化 科技赋能深化文明成效
- 趋势|[转]从“智能湖仓”升级看数据平台架构未来方向
- 数据|天问一号火星离子与中性粒子分析仪首个成果面世