
文章图片
大数据文摘出品
作者:Caleb
陈胜者 , 阳城人也, 字涉 。 吴广者 , 阳夏人也 , 字叔 。
相信不少人还记得中学的时候全文背诵《陈涉世家》的痛苦 , 当然还有考试的时候让你翻译某一句名言 , 像是“燕雀安知鸿鹄之志哉” , 或者“天下苦秦久矣 。 吾闻二世少子也 , 不当立 , 当立者乃公子扶苏” 。
如今 , 随着AI技术的成熟 , 机器也逐渐在学习如何以人类的方式行动和思考 。
既然如此 , 我们为何不考考它 , 看看在AI眼中 , 《陈涉世家》到底是个什么故事 。
最近 , B站上一位叫做“鹰目大人”的阿婆主就用谷歌翻译对AI进行了一次随堂测验 , 只不过它的表现嘛 , 就见仁见智了 。

文章图片
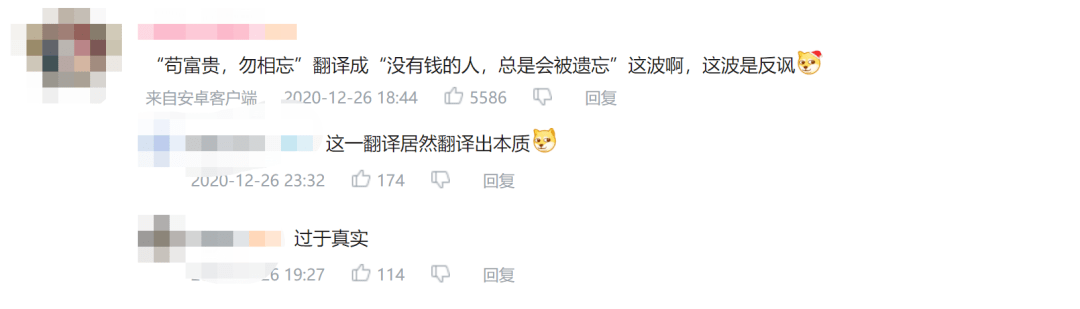
比如 , AI就把这句著名的“苟富贵 , 勿相忘”就翻译成了“没有钱的人 , 总是会被遗忘” 。

文章图片
“燕雀焉知鸿鹄之志”在AI看来竟然是 , “蝎子给了我一个热烈的拥抱”???

文章图片
整个过程 , 文摘菌一边黑人问号脸一边笑到拍桌子 。
有网友就指出 , 这波反讽竟然“翻译出了本质” 。
文章图片
还有网友“太喜欢了所以拼了一首诗” , 大家可以猜猜每句话对应到的原文是什么?

文章图片
然后 , 再来对对答案 , 看看整本《陈涉世家》都被AI翻译成了什么样子?

文章图片
哔哩哔哩
谷歌翻译20次司马迁《陈涉世家》! 清朝 , 瑞士 , 东罗马 , 曹魏竟在同时代
小程序
机器翻译为何如此困难?
其实不管是语种互译 , 还是古文翻译 , 都是机器翻译的类别之一 。
但是 , 如果机器翻译翻车的情况持续发生 , 我们还能相信它吗?
先别急 , 我们从NMT(neural machine translation , 神经网络机器翻译)的诞生开始讲起 , 看看机器翻译到底是个什么东西 。
2013年 , Nal Kalchbrenner和Phil Blunsom提出了一种用于机器翻译的新型端到端编码器-解码器结构 。 该模型可以使用卷积神经网络(CNN)将给定的一段源文本编码成一个连续的向量 , 然后再使用循环神经网络(RNN)作为解码器将该状态向量转换成目标语言 。
这一研究成果的发布可以说是标志着NMT的诞生 , 虽然在那之后也有不少研究者进行改进 , 但是仍然缺乏对模型的理解 。 比如 , 经常出现的问题包括但不限于训练和解码过程缓慢;对同一个词的翻译风格不一致;翻译结果存在超出词汇表(out-of-vocabulary)的问题;黑箱的神经网络机制的可解释性很差;训练所用的参数大多数是根据经验选择的 。
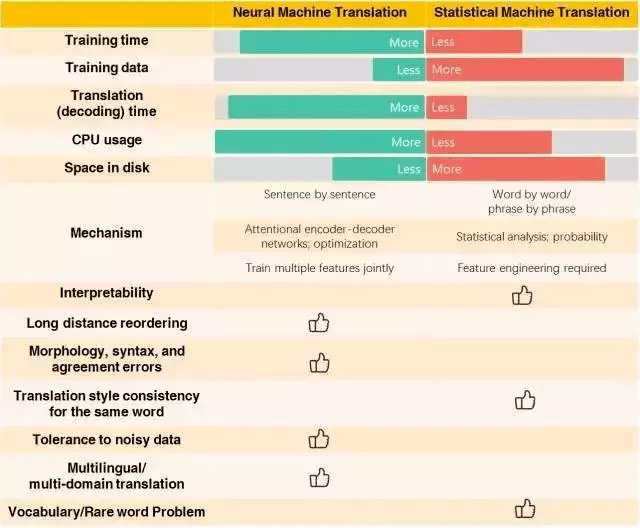
文章图片
NMT和SMT对比
总的来说:不确定性是翻译中的一个核心挑战 。
知己知彼百战百胜 , 想要根除这种不确定性 , 我们还需要知道它的来源 。
在一篇论文中作者指出 , 在构建翻译的模型的时候 , 基本上有两种不确定性 , 一种是任务本身固有的不确定性 , 另一种是数据收集过程中存在的不确定性 。
所谓内在的不确定性 , 是指不确定性的一个来源是一句话会有几种等价的翻译 。 因为在翻译的过程中或多或少是可以直译的 , 即使字面上有很多表达相同意思的方法 。 句子的表达可以是主动的 , 也可以是被动的 , 对于某些语言来说 , 类似于“the”“of”或“their”是可选择的 。
除了一句话可以多种翻译这种情况外 , 规范性不足同样是翻译不确定的来源 。 另外 , 如果没有背景输入 , 模型通常无法预测翻译语言的时态或数字 , 因此 , 简化或增加相关背景也是翻译不确定性的来源 。
而外在的不确定性 , 则是因为系统 , 特别是模型 , 需要大量的训练数据才能表现良好 。 为了节省时间和精力 , 使用低质量的网络数据进行高质量的人工翻译是常见的 。 这一过程容易出错 , 并导致数据分配中出现其他的不确定性 。 目标句可能只是源句的部分翻译 , 或者目标句里面有源句中没有的信息 。
在一些加了copy机制的翻译模型中 , 对目标语言进行翻译的时候可能会完全或部分复制源句子 。 论文作者经过研究发现 , 即使copy机制很小 , 也能对模型预测产生较大的影响 。
论文下载地址:
https://arxiv.org/pdf/1803.00047.pdf
机器翻译频繁翻车 , 微信谷歌无一幸免
去年3月 , 微信翻译的频繁翻车事件得到了人们的关注 , 机器翻译的不确定性同时也被更多人所了解 。
目前 , 机器翻译领域主要使用的NMT架构都差不多 , 一方面问题出在解码器语言模型 , 使用的语料让它学习到了这些最大概率出现的词 。 微信团队在处理的过程中似乎没有对“特殊情况”进行处理 , 于是我们就能看到这样的翻译发生:
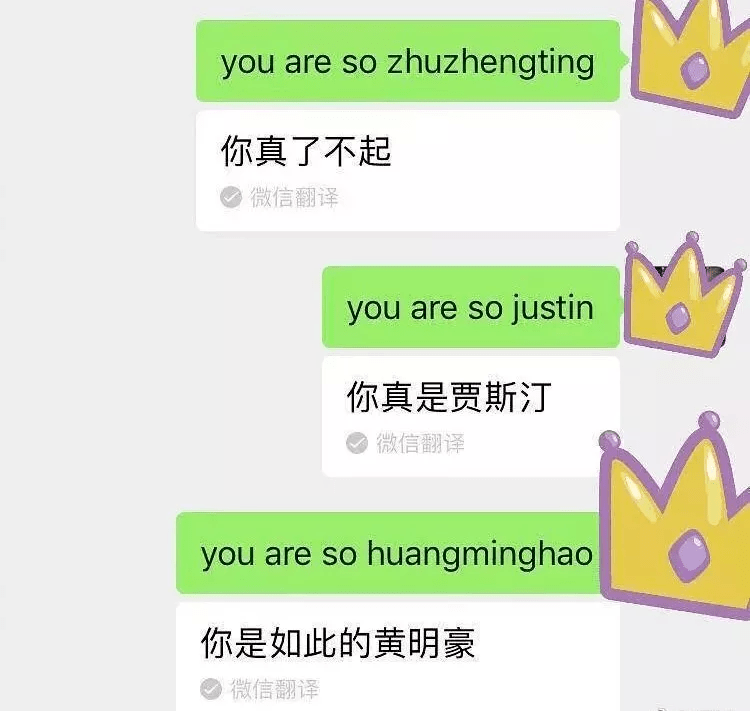
文章图片
如果添加了特殊词的copy机制 , 完全可以把无法翻译的单词不进行翻译 , 直接copy过去 。 也就是说 , 一个聪明的模型应该知道哪些应该翻译 , 哪些不应该翻译 。
随后 , 微信也针对这一问题进行了修复 , 对于敏感词“caixukun”或者句式“you are so……”进行原句返回 。
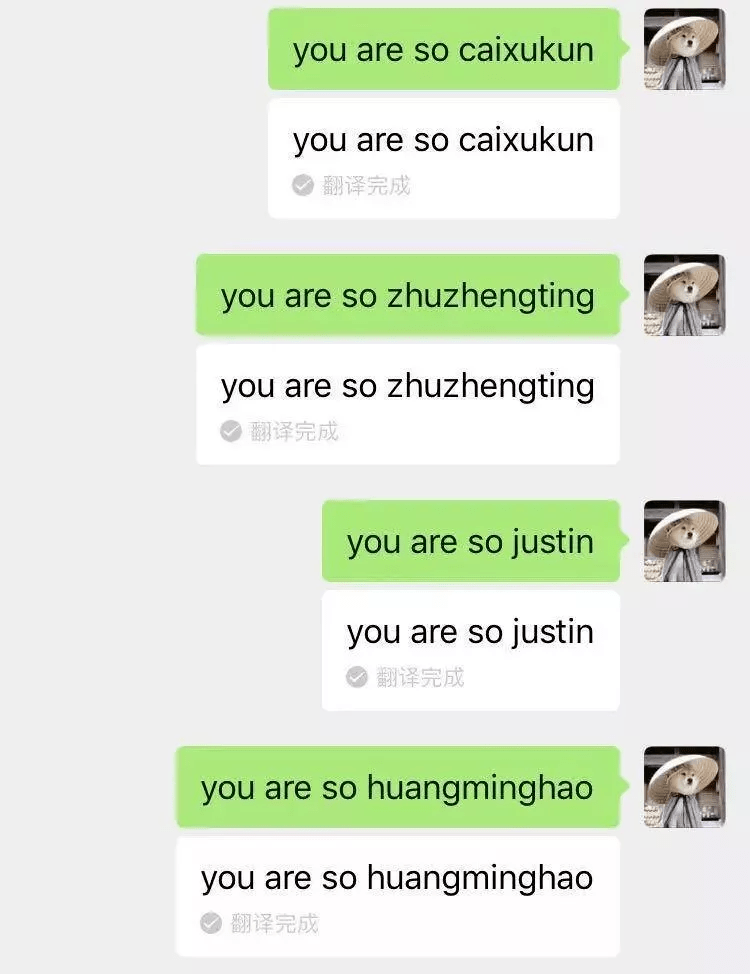
文章图片
除了解码器语言模型外 , 问题可能更多出现在语料库上 , 现在业界所做的机器翻译很大程度上靠语料“怼” , 只要平行语料数量足够多 , 质量足够好 ,一般的系统也可以训练出很好的结果 。
不过 , 如果训练语料多来自电影字幕、多语言会议等材料 , 那么模型最终呈现的翻译内容也会相对应比较“活泼”和“口语化” 。 面对库中不存在的词 , 比如caixunkun , 算法会自动匹配最经常出现 , 或者在同语境下最容易匹配的内容 , 比如形容词“帅哥”或“傻蛋” 。
当然除了微信 , 被业界视为先驱的谷歌也发生过类似的翻车案例 。
此前就有Reddit网友指出 , 谷歌翻译在学习过程中可能受到了输入来源的影响 , 将一些意味不明的语句翻译成了如圣经一般的语言 。 比如这个:
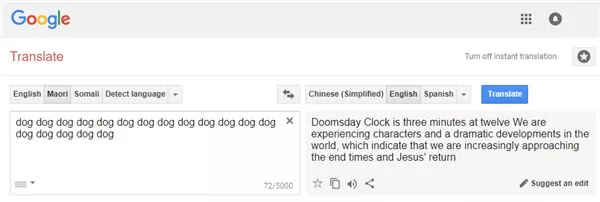
文章图片
英文大意为:世界末日时钟在12点3分钟 , 我们正在经历世界上的人物和戏剧性的发展 , 这表明我们越来越接近末日和耶稣的回归 。
哈佛大学助理教授、研究自然语言处理和计算机翻译的Andrew Rush认为 , 这些神秘的翻译结果可能和谷歌几年前采用的“神经机器翻译”技术有关 。 他表示 , 在神经机器翻译中 , 系统训练用了一种语言的大量文本来和另一种语言进行相应翻译 , 以在两者之间创建模型 。 但当输入的是无意义内容时 , 系统就会出现“幻觉性”的输出结果 。
在去年AI Time的一次辩论中 , 中科院自动化研究所研究员宗成庆就表示 , 机器翻译近几年的进步确实很大 , 但是其需要基于场景和任务 。 机器翻译在一些场景下确实能帮助人 , 比如旅游问路 , 但是在某些领域 , 比如高层次的翻译 , 要对机器翻译寄予太多的希望还为时过早 。
东北大学计算机学院教授朱靖波根据自己的经验列举出好的机器翻译系统需要的三个东西:一是扩大训练数据规模 , 提高品质;二是不断创新技术;三是根据问题不断打磨 , 三者缺一不可 。
【过程|机器翻译古文也翻车?读了20次“苟富贵勿相忘”后,谷歌:没钱的人总会被遗忘】看来 , 机器翻译未来还有很长一段路要走啊!
推荐阅读





- 生物地球化学过程|我国科学家发现第五条甲烷产生途径
- 过程|降解石油产甲烷 古菌拯救“老”油田
- Sreegs|前Tumblr开发者:苹果App Store审核过程令人困惑、随意
- 过程|涛飞网站:建设过程中遇到的问题好多!有同感入
- 刘润|12月23日:希望知识给你启发,求知过程给你更大的启发
- 过程|小马AI智能钢琴陪练课app,上了就知道~
- 方面|梁正:算法治理应关注技术使用过程及产生的影响
- 过程|长阳科技:入选国家级绿色工厂
- 过程|盐湖提锂技术突破,我国锂资源供给更有保障
- 过程|盐湖提锂新技术来了!我国锂资源供给更有保障