【数据|思必驰在中文文本相似度计算任务上的探索与进展】文本相似度计算旨在识别两段文本在语义上是否相似 , 是自然语言处理领域的一个重要研究方向 , 其在智能问答、信息检索等领域都发挥重要作用 , 具有很高的商业价值 。
近期 , 思必驰知识服务团队在中文文本相似度计算方向投入研究 , 并取得阶段性成果:
1)在第十四届全国知识图谱与语义计算大会(CCKS: China Conference on Knowledge Graph and Semantic Computing)[1]上发表相关论文一篇《Neural Fusion Model for Chinese Semantic Matching》 。
该会议是国内知识图谱、语义技术、链接数据等领域的核心学术会议 , 聚集了知识表示、自然语言理解、知识获取、智能问答、链接数据、图数据库、图计算、自动推理等相关技术领域的和研究人员的学者和研究人员 。

文章图片
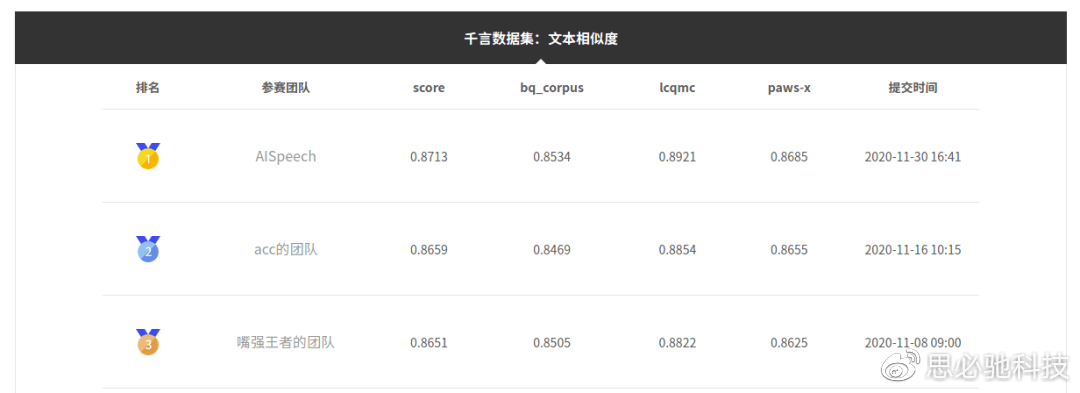
2)在“千言数据集:文本相似度”评测[2]中取得阶段性进展 。 该评测的文本相似度数据集包括公开的三个文本相似度数据集 , 分别为哈工大(深圳) LCQMC 、 BQ Corpus和谷歌的 PAWS-X(中文) 。 目前 , 思必驰知识服务团队在三个数据集上均暂列第一 。
文章图片
针对中文文本相似度计算的鲁棒性和泛化性问题 , 思必驰知识服务团队在以下几个方面开展了技术研究:1)针对中文特点的字、词融合编码器;2)基于预训练模型的领域自适应训练;3)目标应用领域导向的多阶段模型微调 。 相关技术实现在上述公开评测中得到了应用和验证 。
语言智能常被称为人工智能皇冠上的一颗明珠 。 在未来 , 思必驰知识服务团队将继续深耕认知智能领域 , 在面向通用领域的文本相似度计算基础上 , 打造领域自适应的文本相似度计算系统 , 推动文本相似度在垂直领域的应用和发展 。
参考文献:[1] 第十四届全国知识图谱与语义计算大会(CCKS: China Conference on Knowledge Graph and Semantic Computing)http://sigkg.cn/ccks2020/
[2] 千言数据集:阅读理解公开评测https://aistudio.baidu.com/aistudio/competition/detail/45
推荐阅读







- 区块|面向2030:影响数据存储产业的十大应用(下):新兴应用
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 数据|数智安防时代 东芝硬盘助力智慧安防新赛道
- 平台|数梦工场助力北京市中小企业公共服务平台用数据驱动业务创新
- 数据|中标 | 数梦工场以数字新动能助力科技优鄂
- 建设|数据赋能业务,数梦工场助力湖北省智慧应急“十四五”开局
- 市民|大数据、人工智能带来城市新变化 科技赋能深化文明成效
- 趋势|[转]从“智能湖仓”升级看数据平台架构未来方向
- 数据|天问一号火星离子与中性粒子分析仪首个成果面世