在微软Azure公有云上的测试显示 , 因为采用了InfiniBand动态路由和拥塞控制技术 , 实现了云上性能的保障 。 同时 , 成功的将不同的业务之间进行性能隔离 , 让一个业务不会影响到其他的业务 , 实现了真正的完全的Bare-metal的性能 。
3U一体 , 给云原生架构赋予无限算力资源
未来 , 随着数据中心的发展 , 需要将计算移至接近数据的位置 。
DPU的出现 , 为用户提供了另外一个对业务性能进行优化的思路 。 通过更明细的分工来实现效率的提升、实现总体系统的成本最优化 , DPU来运行通信框架 , CPU和GPU执行浮点计算 , 通过DPU加速HPC业务中的通信 , 实现了计算和通信的重叠 。
DPU是集数据中心基础架构于芯片的通用处理器 。 从DPU概念的提出者NVIDIA的现有技术发展趋势来看 , 未来的技术发展趋势将会是高度集成化的片上数据中心的模式(Data Center Infrastructure on a chip) , 即一个GPU、CPU、DPU共存的时代 。

文章图片
NVIDIA布局的数据中心从核心到边缘(Edge)都采用了统一的一个计算架构——CPU、GPU、DPU , 如图所示 , 形成了“3U”一体架构 。 3U一体的统一计算单元架构将会让管理程序、调度程序都会变得非常容易 。
宋庆春解释说 , 在这种新的3U一体的数据中心架构之下 , 将传统Infrastructure的操作都放到了BlueField DPU上 , 由DPU执行通信框架、存储框架、安全框架和业务隔离等 , 将Host里面的CPU和GPU资源统统释放给应用 , 通过这一架构可以让业务性能得到更优的发挥 , 甚至比在Bare-metal状况下它的性能还会有更好的提升 。
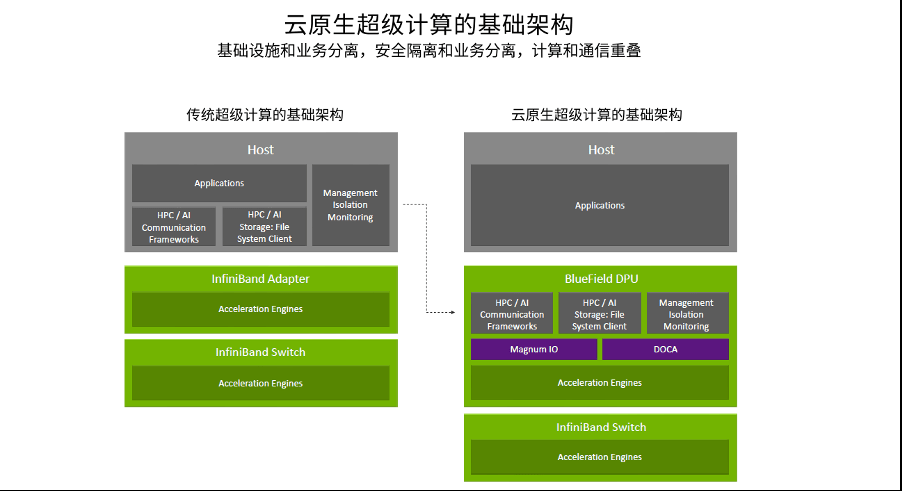
文章图片
比如iAlltoall是在HPC应用、AI做推荐时的经常会用到的通信模型 。 通过用DPU和CPU实现计算和通信的重叠 , 让iAlltoall性能得到44%的提升 。 iAllgather是做大规模模型训练时用到的一个通信模型 , 通过DPU和CPU计算通信的Overlap , 能够让iAllgather性能提升36% 。
宋庆春表示 , DPU的出现弥补了数据中心Infrastructure加速能力不足的问题 , 让数据中心成为新的计算单元 , 给数据中心算力优化提供了全新的资源 。 因此 , 3U一体已经成为数据中心的一个必然的架构 , 而且 , 在这样一个必然的架构中通过DPU、CPU和GPU的分工合作实现一个数据中心中最优的性能 。
云原生软件定义安全为零信任提供安全保障
随着数据的传输越来越快 , 越来越复杂 , 传统的方式或者工具已经没有办法满足现在数据中心的安全需求 。
在传统的数据中心 , 发现一个漏洞 , 可能需要超半年的时间 , 而要修复这个漏洞需要超过两个多月的时间 , 这个对于基于零信任(Zero-trust)的前提下是绝对不可接受的 , 这说明整个数据中心是非常不安全的 。
推荐阅读







- 星链|石豪:在太空,马斯克和美国当局是如何作恶的
- 代码|GGV纪源资本连投三轮,这家无代码公司想让运营流程变简单
- 智能化|适老化服务让银行更有温度
- bug|这款小工具让你的Win10用上“Win11亚克力半透明菜单”
- 软件和应用|AcrylicMenus:让Windows 10右键菜单获得半透明效果
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- ASUS|ROG Maximus Z690 APEX DDR5主板实测 转接卡让DDR4内存顺利点亮
- Tencent|原生版微信上架统信UOS应用商店:适配X86、ARM、LoongArch架构
- 飞腾|原生版微信登陆统信UOS应用商店,已适配X86/ARM/LoongArch架构
- 电子商务|员工抱怨亚马逊太冷酷:工伤后得不到赔偿 还不让休假