图8:VQ-VAE 学到的离散编码可找到并区分图像中的对象
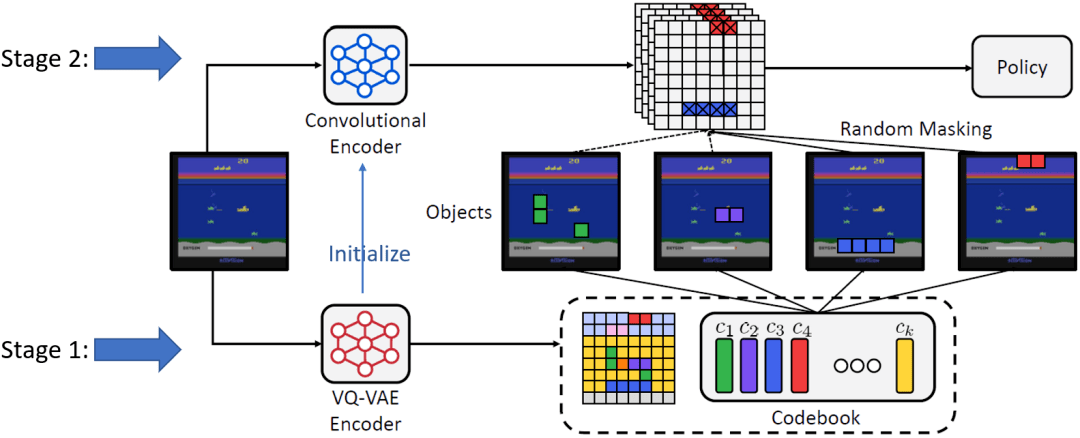
对于第二个任务 , 研究员们对每一个离散编码的值随机地决定是否选择它 , 并在图像的 VQ-VAE 编码中掩盖掉具有所选离散值的格点 。 此操作掩盖掉了编码中的一些对象 , 迫使策略模型关注未被掩盖掉的对象 , 避免仅关注个别对象 。 这是与现有方法最大的不同 , 现有方法掩盖掉的都是空间上相近的区域 , 并不反映具有语义的对象 。 因此 , 此方法被称为 “察觉对象的正则化方法”(Object-aware REgularizatiOn , OREO) 。 图9展示了 OREO 方法的流程 。 第一阶段训练 VQ-VAE 提取对象表示 , 第二阶段学习基于 VQ-VAE 编码的策略模型 , 其间通过所述随机掩盖对象的方法做正则化 。
文章图片
图9:“察觉对象的正则化方法”(OREO)的流程
实验
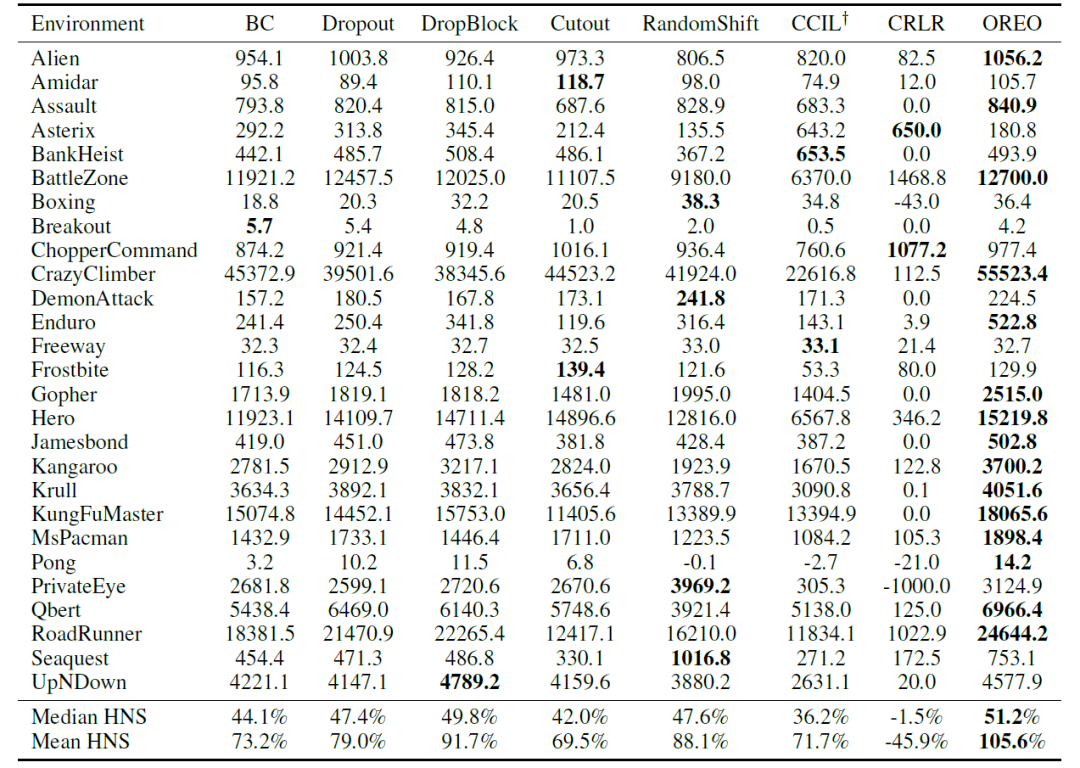
首先 , 考虑混淆雅达利游戏(confounded Atari games)环境 , 这是 De Haan 等人(2019) 所提出的考察因果混淆问题的环境 , 其中游戏图像的每一帧都额外显示玩家上一步采取的动作 。 如表3所示 , OREO 方法在大部分游戏中都取得了最好的表现 。 特别地一点 , OREO 方法胜过在空间区域上随机掩盖的方法(Dropout, DropBlock)、数据增广(data augmentation)方法(Cutout, RandomShift)、以及空间式地随机掩盖 beta-VAE 所学编码的方法(CCIL)[De Hann’19] , 说明了用察觉对象的方式进行正则化的优势 。 OREO 也胜过了因果预测方法 CRLR , 说明简单直接地应用因果方法并不一定有效 , 因为其假设在模仿学习任务中并不成立 , 例如图像数据各维度间并没有明确的因果关系 , 且变量关系也非线性 。 图10的可视化结果表明 , 行为克隆所学到的策略确实仅关注个别物体 , 而 OREO 学到的则更广泛地关注图中的相关对象 。 对于真实场景任务 , 研究员们也考察了在 CARLA 驾驶模拟环境中的表现 。 表4中的结果表明 OREO 也取得了最好的表现 。 论文原文及附录中提供了更多实验结果 。
文章图片
表3:混淆雅达利游戏环境中各模仿学习算法的表现比较

文章图片
图10:使用行为克隆(第一行)及 OREO 方法(第二行)在混淆雅达利环境(左列)及原本的雅达利环境(右列)下学到的策略模型的可视化结果
表4:CARLA 驾驶模拟环境中各任务下各模仿学习算法的成功率
参考文献:
1. [Ribeiro’16] M. T. Ribeiro, S. Singh, and C. Guestrin. “Why should I trust you?": Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13-17, 2016, pages 1135–1144, 2016.
推荐阅读









- Google|谷歌暂缓2021年12月更新推送 调查Pixel 6遇到的掉线断连问题
- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- 四平|智慧城市“奥斯卡”揭晓!祝贺柯桥客户荣获2021世界智慧城市治理大奖
- 系列|2021中国航天发射圆满收官!年发射55次居世界第一
- 项目|常德市二中2021青少年科技创新大赛再获佳绩
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 公司|外媒:2021,人类太空事业的重大年份
- 语境|B站2021个人年度报告发布:你共计看了多少个视频
- 最新消息|IT系统出错 英国银行给7.5万人多发11亿工资