机器之心报道
作者:魔王、蛋酱
10 月初 , 英伟达推出了一项 AI 视频会议服务 Maxine , 使用了 AI 来提升分辨率、降低背景噪声、压缩视频、对齐人脸以及执行实时翻译和转录 。 最近 , 英伟达团队发布的新论文揭露了这背后的技术 。
如果让打工人用几个关键词总结 2020 年的生活 , 「视频会议」应该是其中一个 。
受疫情影响 , 这一年来 , 远程办公和视频会议正在成为新的潮流 。 在忍受会议枯燥的同时 , 很多人迷上了 AI 换脸 , 期望能够实现「一边开会 , 一边摸鱼」的梦想 。 此前机器之心也介绍过 这样的热门项目 。
只是…… 效果不一定很理想:
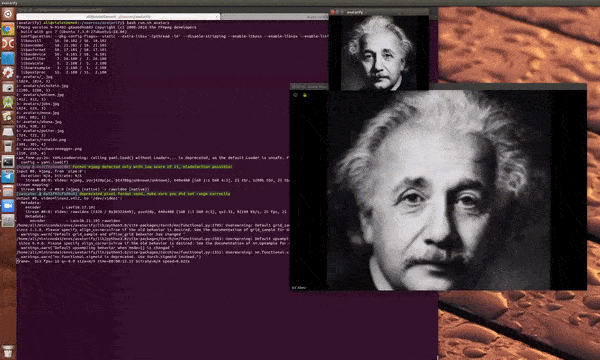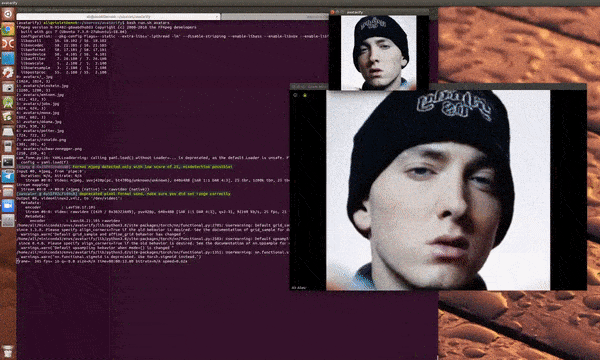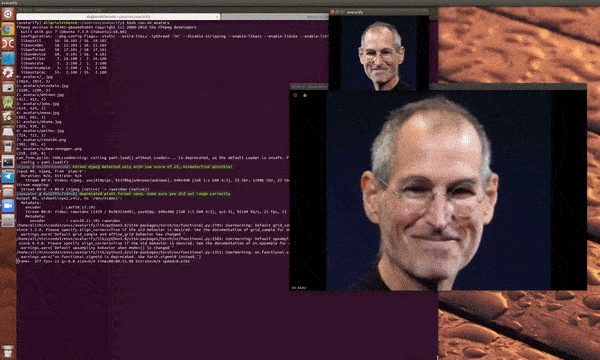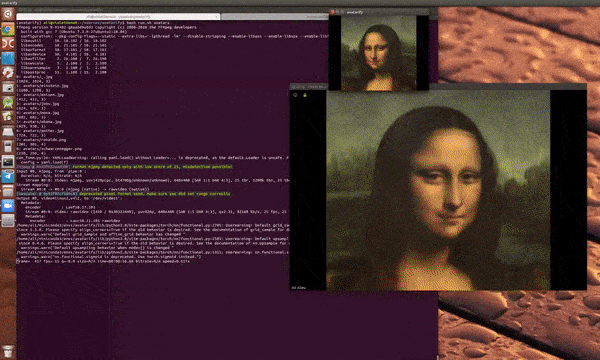
文章图片
给出一个人的源图像 , 和一个人的动作视频(此处称为驱动视频 (driving video) , 动作视频和源图像中的人物可以一致或不一致) , 如何合成逼真的说话者头部视频 , 即将源图像中的头像与驱动视频中的动作合二为一 。 源图像编码目标人物的外观 , 驱动视频决定输出视频中的人物动作 。
最近 , 针对这一任务 , 英伟达提出了一种纯神经式的渲染方法 , 即不使用人物头部的 3D 图模型 , 只使用在 one-shot 设置下训练而成的深度网络 , 进行说话者头部视频的渲染 。

文章图片
论文链接:https://arxiv.org/pdf/2011.15126.pdf
与 3D 图模型相比 , 基于 2D 的方法具备多项优势:首先 , 避免了繁杂、昂贵的 3D 模型获取;其次 , 2D 方法可以更好地处理头发、胡须等的合成 , 而获得这些区域的详细 3D 几何形状则有一定的挑战性;最后 , 无需 3D 模型 , 2D 方法可以直接合成源图像中的配饰 , 包括眼镜、帽子、围巾等 。
但是 , 现有的 2D 方法存在一些局限性 。 由于缺少 3D 图模型 , 2D 方法只能从原始视角合成说话者头部视频 , 无法从新的角度进行渲染 。
而英伟达的方法解决了 2D 方法的固定视角问题 , 并实现了局部自由视角合成 , 你可以在原始视角的一定范围内改变说话者头部的角度 。
该模型使用新型 3D 关键点表征来表示视频 , 3D 关键点表征的特点是将人物特定信息和动作相关信息分解开来 , 关键点及其分解均使用无监督学习方式得到 。 使用该分解 , 英伟达能够对人物特定表征应用 3D 变换 , 来模拟头部姿势的变化 , 如转动头部 。 下图 2 展示了英伟达提出的新方法:
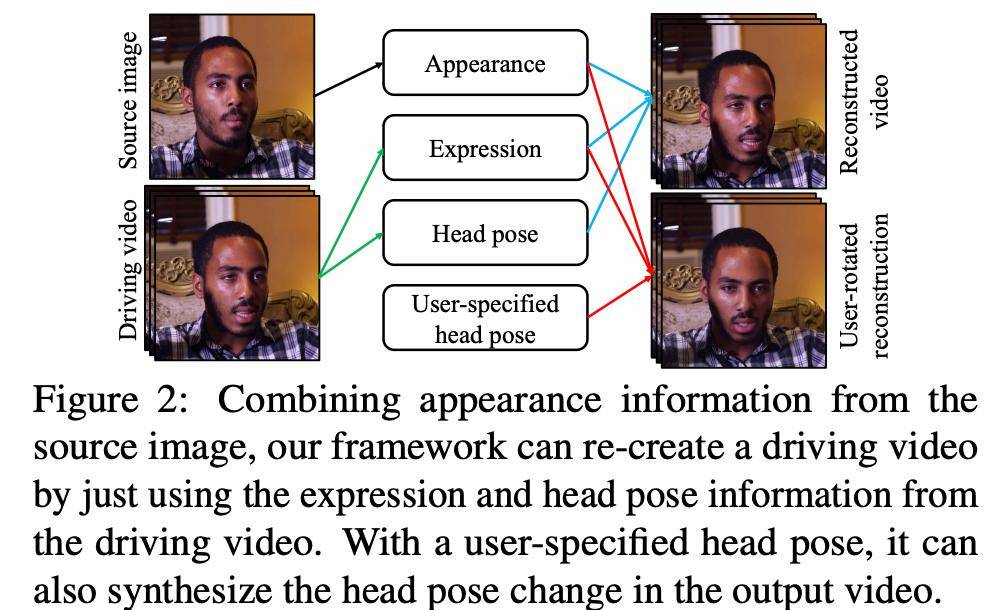
文章图片
研究者在多个说话者头部合成任务中进行了大量实验验证 , 包括视频重建、动作迁移和人脸重定向(face redirection) , 还将该方法应用于降低视频会议的带宽 。 通过仅发送关键点表征、在接收端重建源视频 , 该方法将视频会议带宽降至 H.264 商用标准所需带宽的十分之一 , 且不影响视觉质量 。

文章图片
视频重建效果 。

文章图片
动作迁移 。

文章图片
人脸重定向 。
这项研究基于前段时间英伟达开源的 库 , 也是英伟达 视频流平台背后的技术组成部分之一 。
GAN 发明者 Ian Goodfellow 在推特上点赞并表示:「Cool , 博士时期的实验室伙伴曾研究预训练阶段的 ML 压缩 , 我记得这很难 。 」
文章图片
主要贡献
该研究的主要贡献如下:
提出新型 one-shot 神经说话者头部合成方法 , 在基准数据集上获得了比 SOTA 方法更好的视觉质量;
在没有 3D 图模型的情况下 , 实现了对输出视频的局部自由视角控制 , 即在合成过程中允许改变说话者头部的角度;
将视频会议的带宽 , 降至 H.264 视频压缩标准所需带宽的十分之一 。
英伟达新方法
英伟达提出一种纯神经合成方法 , 不使用 3D 图模型 。 该方法包含三个主要步骤:
源图像特征提取;
驱动视频特征提取;
视频合成 。
研究者使用一组网络并进行联合训练 , 来完成这些步骤 。
其中前两个步骤参见下图 3:
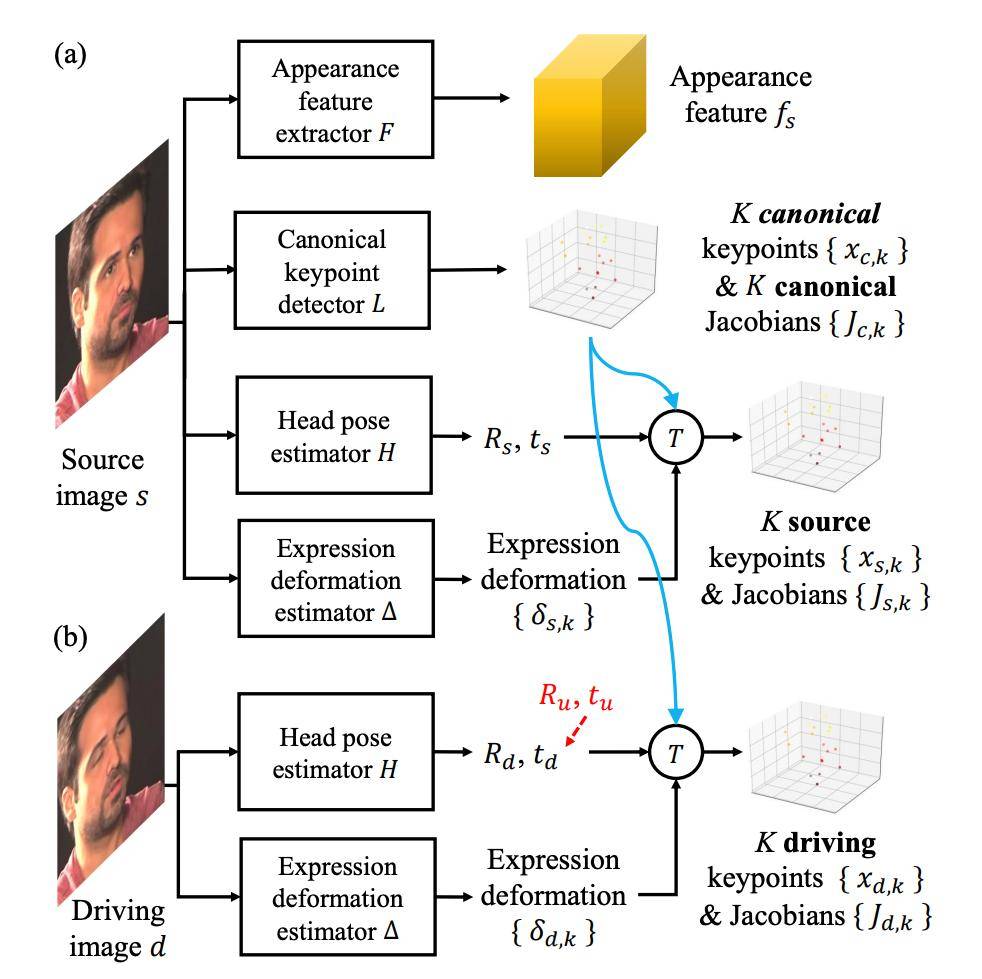
文章图片
图 3:源图像和驱动视频特征提取 。
具体而言 , 该研究从源图像中提取人物外观特征和 3D 典型关键点及其雅克比行列式 , 同时还估计人物头部姿势和表情变化引起的关键点扰动 , 利用它们来计算源关键点 。
对于驱动视频 , 研究者仍旧估计其头部姿势和表情形变 。 通过重用来自源图像的 3D 典型关键点 , 来计算驱动关键点 。
第三个步骤参见图 5:
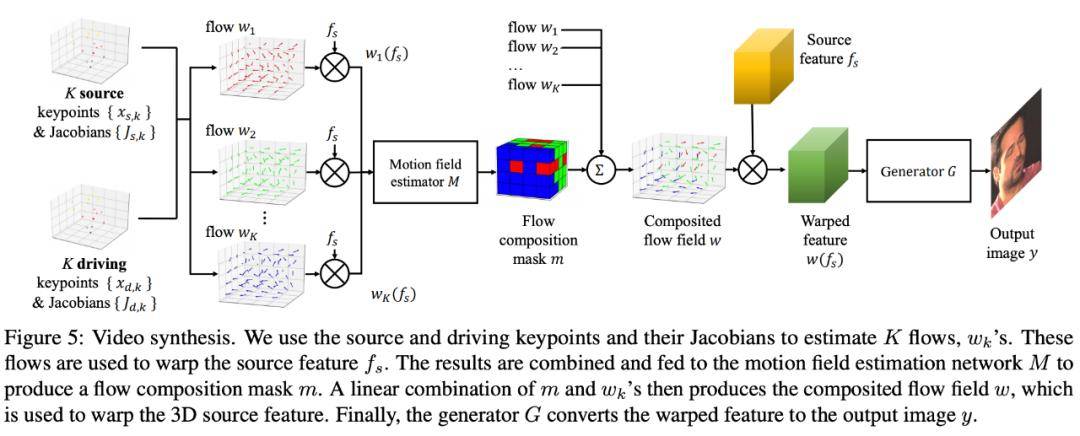
文章图片
图 5:视频合成 。
该步骤中 , 研究人员使用源关键点、驱动关键点及其雅克比行列式来估计 K 个 flow(w_1、w_2、w_k) , 这些 flow 用于扭曲源特征 f_s 。 然后将这些结果结合起来输入到运动场(motion field)估计网络 M , 得到流分解掩码 m 。 将 m 和 w_k flow 进行线性组合得到合成流场 w(composited flow field) , 可用于扭曲 3D 源特征 。 最后 , 生成器 G 将扭曲后的特征转换为输出图像 y 。
而该方法还包括一个主要环节:用无监督方式学习一组 3D 关键点及其分解 。 研究人员将这些关键点分解成两部分:一部分建模人脸表情 , 一部分建模人物的几何特征 。 二者与目标人物头部姿势相结合 , 就可以生成图像特定的关键点 , 然后利用它们学习两个图像之间的映射函数 。
在第一个步骤中 , 从源图像得到的关键点是图像特定的 , 且包含人物特征、姿势和表情信息 。 关键点计算流程参见下图 4:

文章图片
训练细节
下图展示了该模型中网络的实现细节 , 以及模型构造块详情:
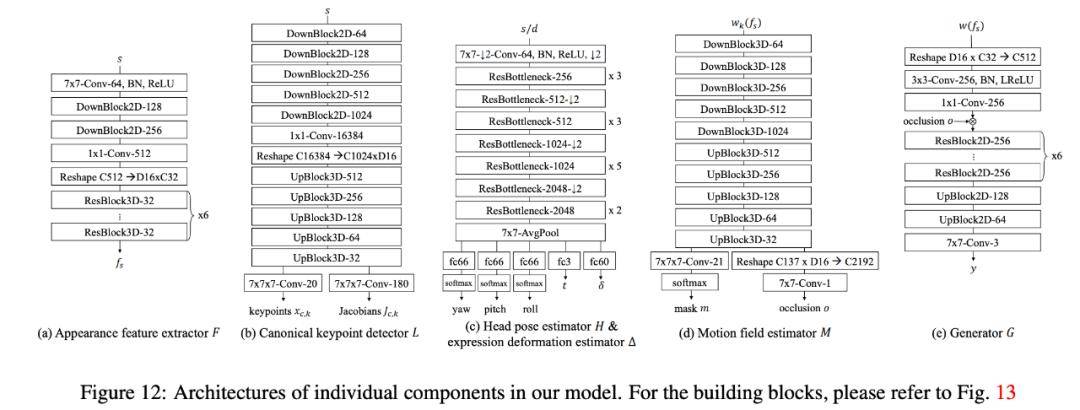
文章图片
图 12:模型中各个组件的具体架构 。
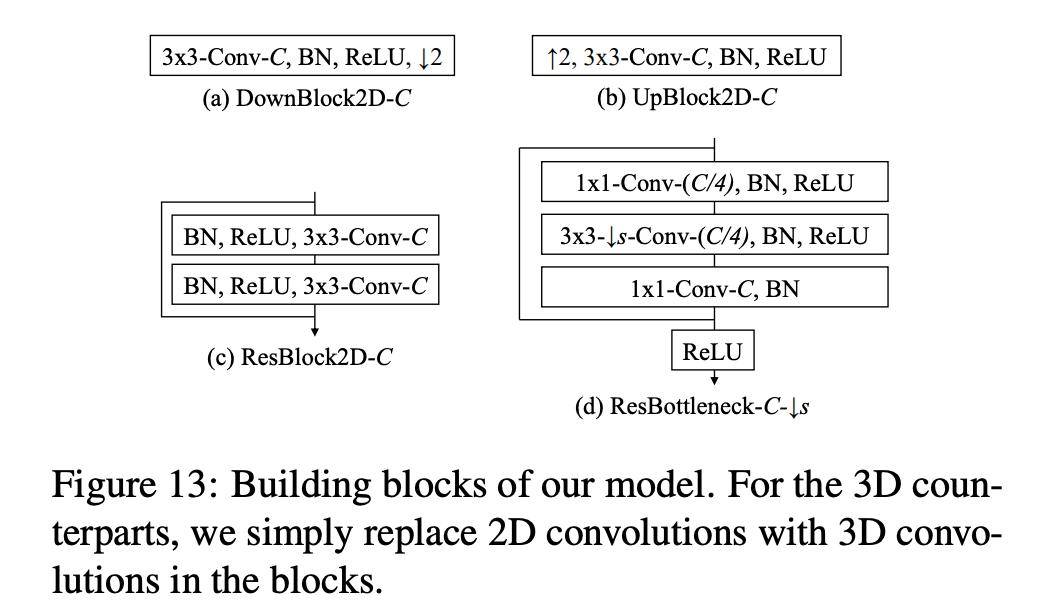
文章图片
图 13:模型构造块 。
实验
说话者头部图像合成
这部分涉及两个任务:相同人物的图像合成和不同人物的动作迁移 。
首先是源图像和驱动图像中人物身份一致的情况 。 研究者对比了五种人脸合成方法 , 量化评估结果参见下表 1 。 可以看出 , 该研究提出的方法在两个数据集的所有指标上的表现均优于其他方法 。
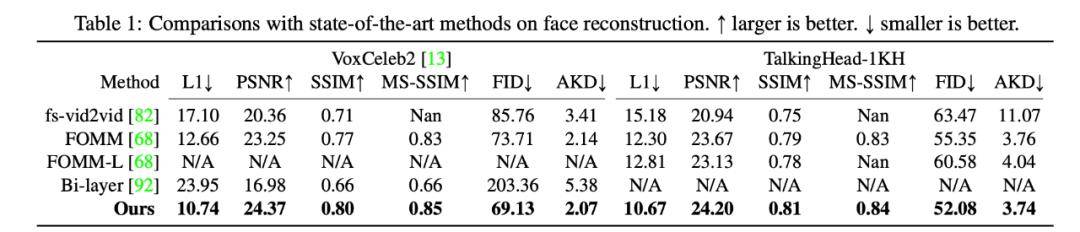
文章图片
在图 6 和图 7 中 , 研究者分别展示了不同方法的定性比较结果 , 该研究提出的方法能够更加真实地再现动作变化 。
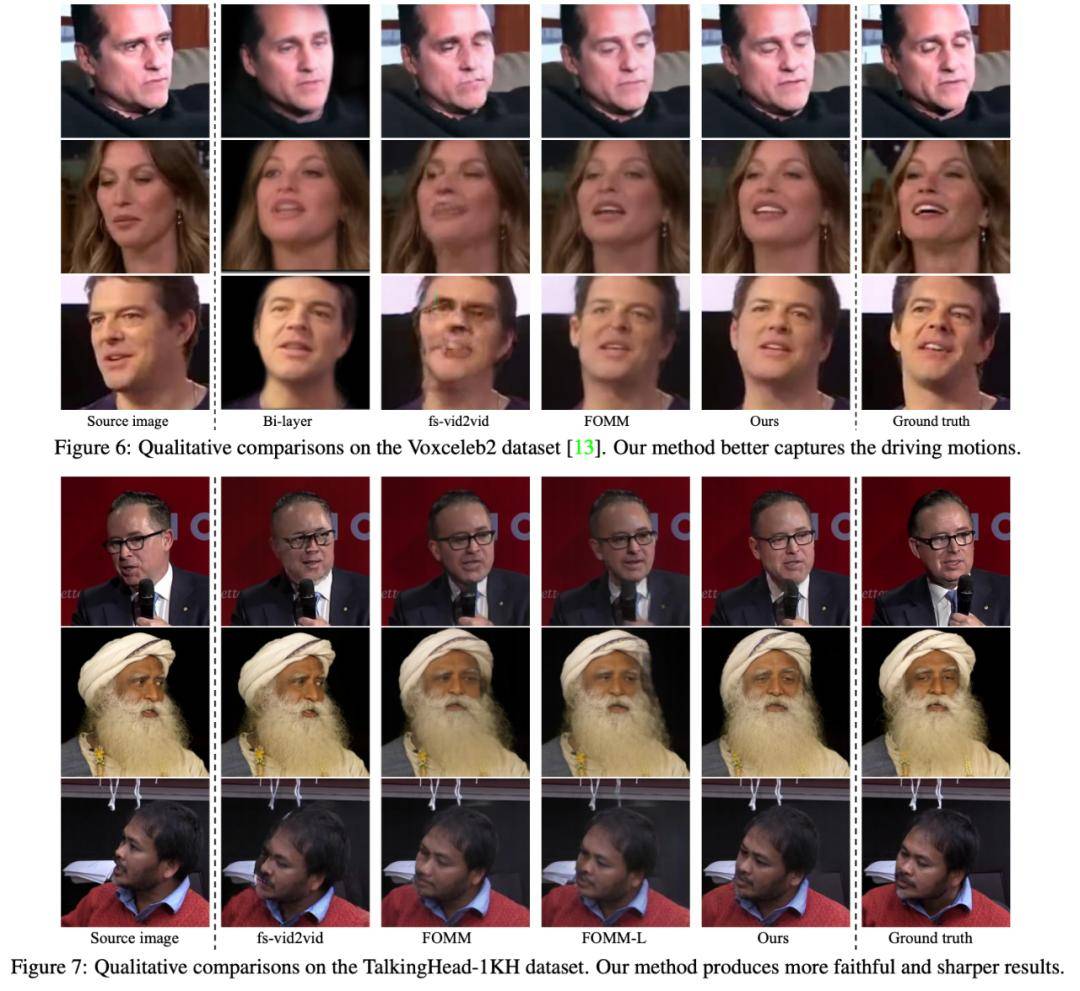
文章图片
【服务|告别渣画质,视频会议带宽降90%,英伟达公开Maxine服务背后重要技术】接下来 , 研究者在源图像和驱动图像中人物不同的情况下 , 进行方法对比 , 结果如表 2 所示 。 该研究提出的方法取得了最低的 FID 分数 。

文章图片
图 8 展示了不同方法间的对比结果 , 可以看出英伟达方法生成的结果更为真实 , 且保留了原有的人物特征 。

文章图片
人脸重定向
研究人员对 pixel2style2pixel (pSp)、Rotate-and-Render (RaR) 和该研究提出方法进行了量化对比 , 结果参见下表 3:
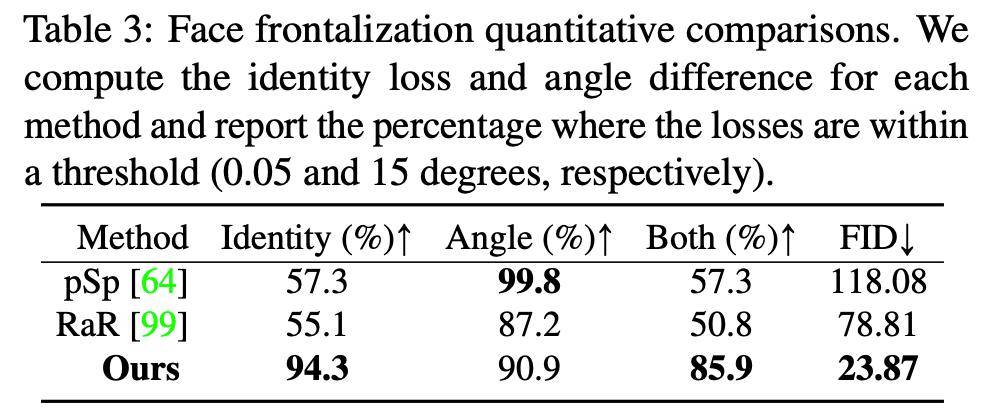
文章图片
三种方法的示例对比结果如图 9 所示 。
可以看出 , pSp 模型虽然能够将人脸前置 , 但会丢失人物的身份特征 。 RaR 采用了 3D 人脸模型 , 因此生成结果的视觉效果更具吸引力 , 但在人脸区域以外的地方存在问题 。 此外 , 这两种方法都存在时间稳定性问题 。 对比之下 , 该研究提出方法实现了不错的人脸前置效果 。

文章图片
在视频会议中的应用
该模型能够利用紧凑表征对驱动图像中的动作进行蒸馏 , 这有助于降低视频会议应用的带宽 。 视频会议流程可以看做接收者看到发送者面部的动态版本 。
图 10 展示了使用该研究提出的神经说话者头部模型搭建的视频会议系统 。
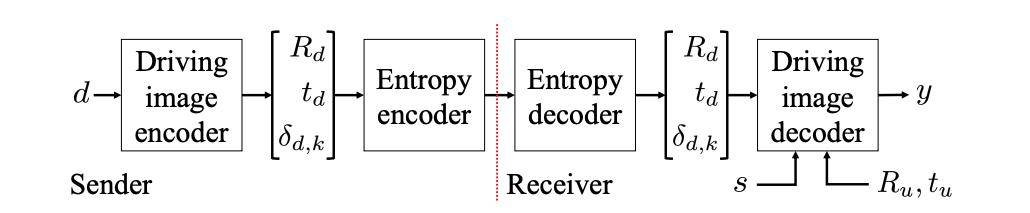
文章图片
图 10:视频压缩框架 。
在发送端 , 驱动图像编码器提出关键点扰动δ_d,k 和头部姿势 R_d 和 t_d , 然后使用熵编码器进行压缩并传送至接收端 。 接收端对信息进行解压缩 , 并将其与源图像 s 结合生成输入 d 的重建结果 y 。
论文作者表示 , 目前该方法在压缩方面的优势仅限于说话者头部视频 , 至于一般的视频压缩 , 还未能达到如此理想的效果 。
文章图片
目前 , 英伟达已经开放了在线演示网址:http://nvidia-research-mingyuliu.com/face_redirection
关于更多的论文细节 , 可参考下方视频:
2020 NeurIPS MeetUp
12月6日 , 机器之心将举办2020 NeurIPS MeetUp 。 此次MeetUp精选数十篇论文 , 覆盖深度学习、强化学习、计算机视觉、NLP等多个热门主题 , 设置4场Keynote、13篇论文分享和28个Poster 。
时间:12月6日9:00-18:00
地址:北京燕莎中心凯宾斯基饭店(亮马桥)
_原题《告别渣画质 , 视频会议带宽降90% , 英伟达公开Maxine服务背后重要技术》
阅读原文
推荐阅读







- 智能化|适老化服务让银行更有温度
- 手机|黑莓宣布 1 月 4 日起将终止 BlackBerry OS 设备服务支持
- |南安市交通运输局强化渣土 运输安全专项整治
- |南安市交通运输局:履行行业监管职责,扎实推进公路工程中介服务专项整治
- Lenovo|联想将推出135W Type-C充电器:游戏本告别“砖头”
- 上海|上海供水热线与城投水务官网合并上线,一站式服务更便民
- 审判|直接服务“三城一区”主平台,怀柔科学城知识产权巡回审判庭成立
- 服务|互联网+税务让服务更优质 杭州代开发票税务进入新局面
- 华为|Insights直播回顾手语服务,助力沟通无障碍
- 平台|数梦工场助力北京市中小企业公共服务平台用数据驱动业务创新