量化|大模型高效释放生产性能,HuggingFace开源Transformer扩展优化新库( 二 )
然而 , 由于需要大量的算力 , 将基于 Transformer 的模型应用于工业生产很困难 , 开销巨大 。 有许多技术试图解决这一问题 , 其中最流行的方法是量化 。 可惜的是 , 在大多数情况下 , 模型量化需要大量的工作 , 原因如下:
【量化|大模型高效释放生产性能,HuggingFace开源Transformer扩展优化新库】首先 , 需要对模型进行编辑 。 具体地 , 我们需要将一些操作替换为其量化后的形式 , 并插入一些新的操作(量化和去量化节点) , 其它操作需要适应权值和激活值被量化的情况 。
例如 , PyTorch 是在动态图模式下工作的 , 因此这部分非常耗时 , 这意味着需要将上述修改添加到模型实现本身中 。 PyTorch 现在提供了名为「torch.fx」的工具 , 使用户可以在不改变模型实现的情况下对模型进行变换 , 但是当模型不支持跟踪时 , 就很难使用该工具 。 在此基础之上 , 用户还需要找到模型需要被编辑的部分 , 考虑哪些操作有可用的量化内核版本等问题 。
其次 , 将模型编辑好后 , 需要对许多参数进行选择 , 从而找到最佳的量化设定 , 需要考虑以下三个问题:
- 应该使用怎样的观测方式进行范围校正?
- 应该使用哪种量化方案?
- 目标设备支持哪些与量化相关的数据类型(int8、uint8、int16)?
最后 , 从目标设备导出量化模型 。
尽管 PyTorch 和 TensorFlow 在简化量化方面取得了很大的进展 , 但是基于 Transformer 的模型十分复杂 , 难以在不付出大量努力的情况下使用现成的工具让模型工作起来 。
英特尔的量化神器:Neural Compressor
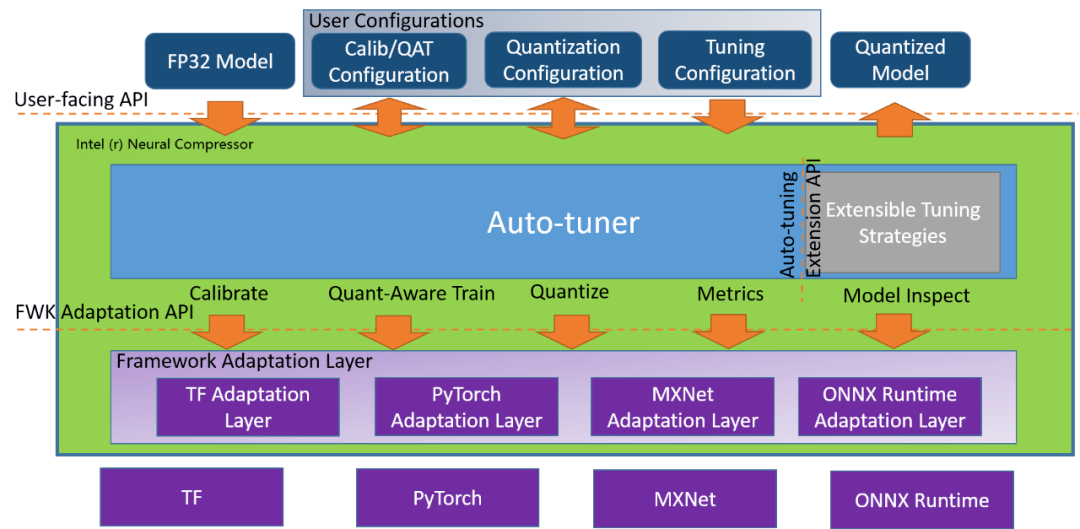
文章图片
Neural Compressor 架构示意图 。 地址:https://github.com/intel/neural-compressor
英特尔开源的 Python 程序库 Neural Compressor(曾用名「低精度优化工具」——LPOT)用于帮助用户部署低精度的推理解决方案 , 它通过用于深度学习模型的低精度方法实现最优的生产目标 , 例如:推理性能和内存使用 。
Neural Compressor 支持训练后量化、量化的训练以及动态量化 。 为了指定量子化方法、目标和性能评测标准 , 用户需要提供指定调优参数的配置 yaml 文件 。 配置文件既可以托管在 Hugging Face 的 Model Hub 上 , 也可以通过本地文件夹路径给出 。
使用 Optimum 在英特尔至强 CPU 上轻松实现 Transformer 量化
实现代码如下:

文章图片
踏上 ML 生产性能下放的大众化之路
推荐阅读







- Insight|太卷了!太不容易了!
- 网友|重磅!2021年度『量化』关键词揭榜
- 移动|全国首台低温高效提取移动智能工厂落户江西
- RNA|高等植物第四种RNA聚合酶 可与“伙伴”高效合成双链RNA
- 沈余银|视频化趋势下,云技术如何让视频表达更高效?
- 模型|2022前展望大模型的未来,周志华、唐杰、杨红霞这些大咖怎么看?
- 设备|小米拍拍 4K 高清投屏器体验:「投屏」更高效的打开方式
- 设计|独特形态+创新功能 三星Galaxy Z Flip3 5G将便携高效精彩演绎
- 项目|横店东磁:年产2GW高效组件项目投产
- 服务|华为发布首本《Serverless核心技术与实践》,助力开发者高效构建应用