机器之心报道
编辑:蛋酱、小舟
在微软和英伟达的共同努力下 ,Turing NLG 17B 和 Megatron-LM 模型的继承者诞生了:5300 亿参数 , 天生强大 , 它的名字叫做「Megatron-Turing」 。刚刚 , 微软和英伟达联合推出了训练的「迄今为止最大、最强大的 AI 语言模型」:Megatron-Turing (MT-NLP) 。

文章图片
从公开披露的角度来看 , MT-NLP 应该是现存最大的公共模型 。
作为两家公司 Turing NLG 17B 和 Megatron-LM 模型的继承者 , MT-NLP 包含 5300 亿个参数 , 并在一系列广泛的自然语言任务中表现出了「无与伦比」的准确性 , 包括阅读理解、常识推理和自然语言推理 。
大规模语言模型
近年来 , 自然语言处理 (NLP) 中基于 Transformer 的语言模型在大规模计算、大型数据集以及用于训练这些模型的高级算法和软件的推动下发展迅速 。 具有大量参数、更多数据和更多训练时间的语言模型可以获得更丰富、更细致的语言理解 。
因此 , 它们可以很好地泛化为有效的零样本(zero-shot)或少样本(few-shot)学习器 , 在许多 NLP 任务和数据集上具有很高的准确性 。 NLP 领域的下游任务包括文本摘要、自动对话生成、翻译、语义搜索、代码自动生成等 。 当前 , SOTA NLP 模型中的参数数量呈指数增长 , 如下图 1 所示 。
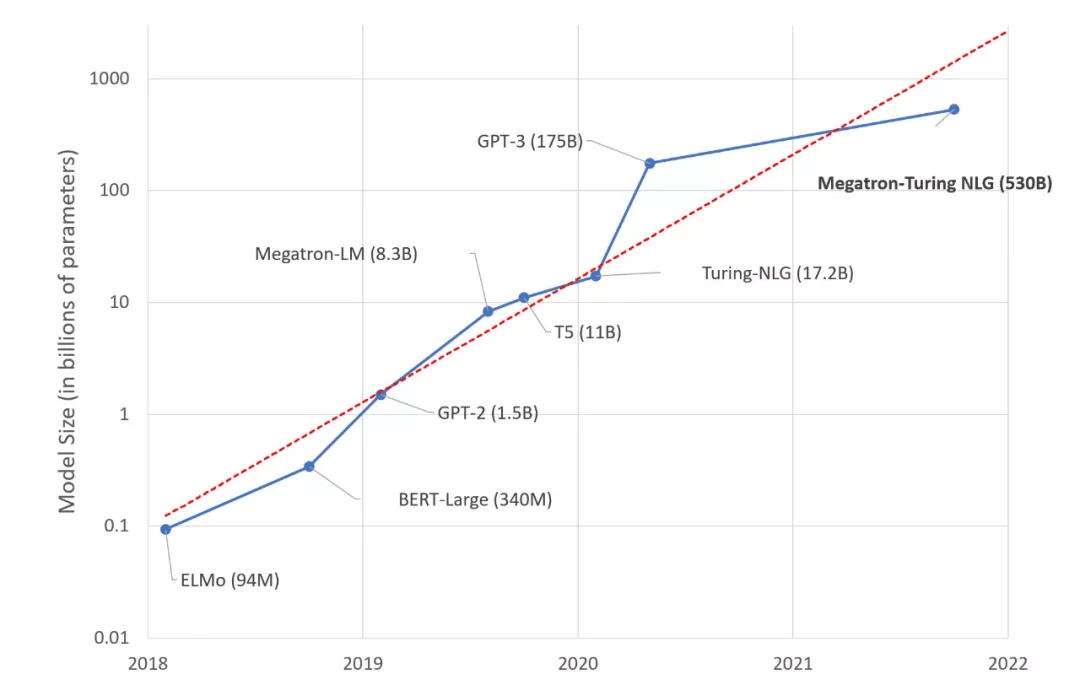
文章图片
图 1. SOTA NLP 模型的大小随时间变化的趋势
然而 , 训练此类模型具有挑战性 , 主要有两个原因:
- 即使使用最大的 GPU , 也不再可能在内存中拟合这些模型的参数 。
- 如果不特别优化算法、软件和硬件堆栈 , 所需的大量计算操作可能会导致不切实际的极长训练时间 。
下面我们来详细看下该研究的训练的各个方面和该方法的结果 。
大规模训练的基础设置
由英伟达 A100 Tensor Core GPU 和 HDR InfiniBand 网络支撑的 SOTA 超级计算集群(例如英伟达的 Selene 和微软的 Azure NDv4) 有足够的计算能力在合理的时间范围内训练具有数万亿个参数的模型 。 然而 , 要充分发挥这些超级计算机的潜力 , 需要在数千个 GPU 之间实现并行 , 在内存和计算上都高效且可扩展 。
推荐阅读








- 星链|石豪:在太空,马斯克和美国当局是如何作恶的
- 快报|“他,是能成就导师的学生”
- 区块|面向2030:影响数据存储产业的十大应用(下):新兴应用
- 年轻人|人生缺少的不是运气,而是少了这些高质量订阅号
- 生活|气笑了,这APP的年度报告是在嘲讽我吧
- bug|这款小工具让你的Win10用上“Win11亚克力半透明菜单”
- 苏宁|小门店里的暖心事,三位创业者的雪域坚守
- 历史|科普:詹姆斯·韦布空间望远镜——探索宇宙历史的“深空巨镜”
- 空间|(科技)科普:詹姆斯·韦布空间望远镜——探索宇宙历史的“深空巨镜”
- 生活|数字文旅的精彩生活