机器之心报道
机器之心编辑部
在 NLP 领域 , pretrain-finetune 和 prompt-tuning 技术能够提升 GPT-3 等大模型在各类任务上的性能 , 但这类大模型在零样本学习任务中的表现依然不突出 。 为了进一步挖掘零样本场景下的模型性能 , 谷歌 Quoc Le 等研究者训练了一个参数量为 1370 亿的自回归语言模型 Base LM , 并在其中采用了全新的指令调整(instruction tuning)技术 , 结果显示 , 采用指令调整技术后的模型在自然语言推理、阅读理解和开放域问答等未见过的任务上的零样本性能超越了 GPT-3 的小样本性能 。大规模语言模型(LM)已经被证明可以很好的应用到小样本学习任务 。 例如 OpenAI 提出的 GPT-3, 参数量达 1,750 亿 , 不仅可以更好地答题、翻译、写文章 , 还带有一些数学计算的能力等 。 在不进行微调的情况下 , 可以在多个 NLP 基准上达到最先进的性能 。
然而 , 像 GPT-3 这样的大规模语言模型在零样本(zero-shot)学习任务中表现不是很突出 。 例如 , GPT-3 在执行阅读理解、问答和自然语言推理等任务时 , 零样本的性能要比小样本(few-shot)性能差很多 。
本文中 , Quoc Le 等来自谷歌的研究者探索了一种简单的方法来提高大型语言模型在零样本情况下的性能 , 从而扩大受众范围 。 他们认为 NLP 任务可以通过自然语言指令来描述 , 例如「这部影评的情绪是正面的还是负面的?」或者「把『how are you』译成汉语」 。
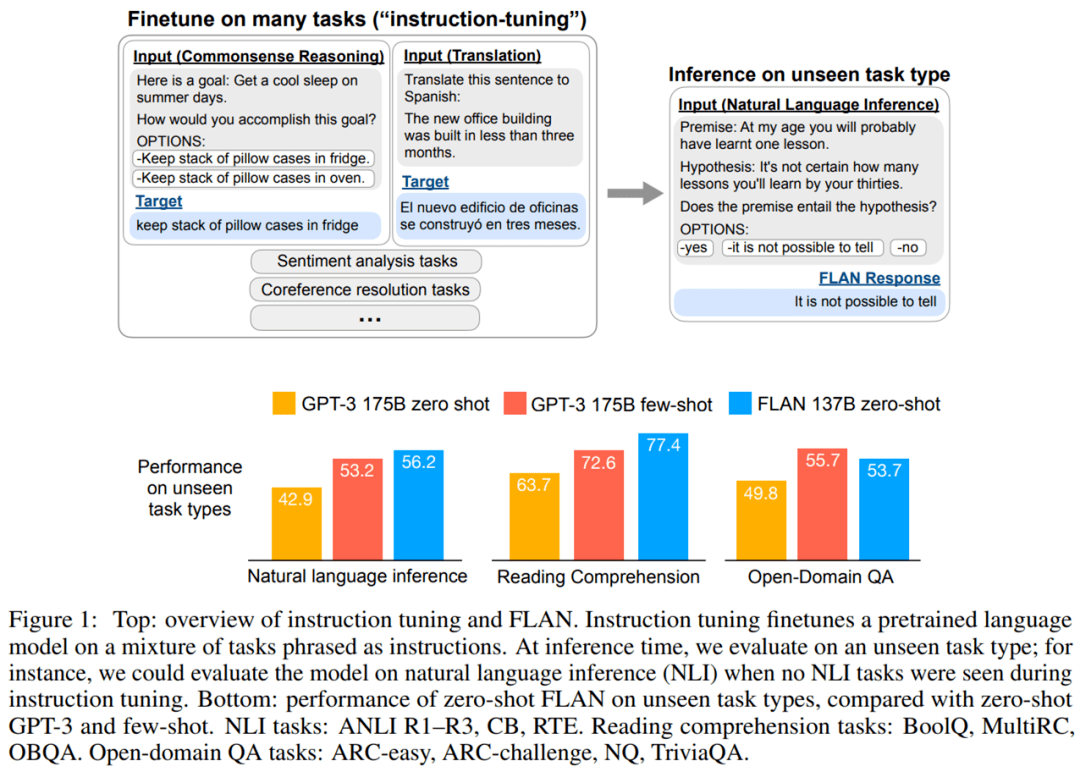
该研究采用具有 137B 参数的预训练模型并执行指令调整任务 , 对 60 多个通过自然语言指令表达的 NLP 任务进行调整 。 他们将这个结果模型称为 Finetuned LANguage Net , 或 FLAN 。

文章图片
- 论文地址:https://arxiv.org/pdf/2109.01652.pdf
- GitHub 地址:https://github.com/google-research/flan.
文章图片
评估表明 , FLAN 显著提高了模型(base 137B 参数)的零样本性能 。 在 25 个评估任务中 , FLAN 零样本在 19 项任务上优于具有 175B 参数 GPT-3 零样本 , 甚至在许多任务(如 ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA 和 StoryCloze)上也显著优于 GPT-3 小样本 。 在消融研究中 , 研究发现在指令调整中增加任务集群的数量 , 可以提高模型在未见过的任务的性能 , 并且指令调整的好处只有在模型规模足够大的情况下才会出现 。
推荐阅读







- 数字化|零售数字化转型显效 兴业银行手机银行接连获奖
- Apple|法官称苹果零售店搜包和解协议虽不完美,但可继续进行
- 水管|柔性泄水管概述、性能参数
- 影像|京东零售集团CEO辛利军空降小米“跑进2022”活动直播间为米粉送福利
- 样本|国内首个在库运行超百万份生物样本全自动化库落户广州
- 旗舰|小米12系列发布,自研芯片加持,18分钟从零充满电
- 数据|聚焦解决 “卡脖子”问题 三六零旗下国家工程研究中心纳入新序列
- Foxconn|吉利疑与富士康共同成立公司 涉及汽车零部件制造
- 售价|2799 元起,vivo S12 / Pro 明日零点开售
- 第一医院|三明启动“云查房” 让基层百姓“零距离”共享专家医疗服务