2021年 , 百度AI技术研究依然保持着高质量产出 。 近期 , ICML、IJCAI、ISIT等机器学习领域顶会收录了来自百度的数十篇论文 , 涵盖深度神经网络、多语言预训练、视频描述生成、AI辅助医疗诊断、量子信息等多个研究方向 。
国际机器学习会议(ICML)、国际人工智能联合会议(IJCAI)、IEEE信息论国际研讨会(ISIT)都是人工智能领域的国际顶级学术会议 。 在今年ICML大会开展同期 , 百度还举办了以飞桨为主题的ICML EXPO Workshop 。 这也是本次由国内企业主办的唯一一个Expo 。 本次Expo从计算视觉、自然语言处理、语音、量子计算等多个角度 , 全面展示了飞桨在深度学习领域强大的技术优势和深厚的产业实践积累 。
百度此次共有数十篇优质论文入选三大AI国际顶会 , 不仅展现了在人工智能多个技术领域的深耕与创新成果 , 更与技术不断落地应用、深入实际场景息息相关 。 目前 , 百度AI技术已赋能工业、能源、医疗、金融、农业、城市管理、交通、信息技术等各行业 , 推动AI工业大生产进程加速的同时 , 实际应用也为技术的迭代突破持续反哺 。
以下为百度此次在ICML、IJCA、ISIT上的主要论文介绍 。
百度ICML 2021论文
1.随机傅立叶特征的量化算法
Quantization Algorithms for Random Fourier Features
论文链接:http://proceedings.mlr.press/v139/li21i/li21i.pdf
非线性核方法是被工业界广泛应用的重要的机器学习模型之一 。 由于核函数矩阵的维度正比于数据点个数 , 大规模数据集在时间和存储上都给直接使用非线性核方法带来极大困难 。 对于最常见的高斯核函数 , 随机傅立叶特征(Random Fourier Features, RFF)可以有效地在线性时间内接近非线性核学习的效果 , 并且不需要直接计算庞大的核函数矩阵 , 因此成为大规模非线性核学习的重要工具之一 。
本文首次通过研究随机傅立叶特征的统计分布 , 提出基于Lloyd-Max(LM)最小失真准则的量化方法 , 以此进一步显著减少RFF的存储成本 。 我们给出LM量化下高斯核函数估计量的一系列严格理论结果 , 证明LM估计量的正确性和优越性 , 以及规范化量化后的傅立叶特征可以进一步降低高斯核估计的除偏方差 。 基于多个大规模数据集的实证分析证明 , 在平均可降低10倍以上的存储成本的前提下 , 经LM量化后的特征可以达到使用全精度傅立叶特征的准确率 。 该方法的表现显著优于过去已提出的随机量化方法 。 本文为工业级大规模非线性核学习提供了一种存储便利且效果极佳的压缩数据表征方法 。
百度在大规模非线性机器学习加速、随机投影和随机傅立叶特征等领域都有多年积累和丰富的成果 。 2021年发表的相关论文还包括:
- lAISTATS 2021, One Sketch for All: Non-linear Random Features from Compressed Linear Measurements
- lWWW 2021, Consistent Sampling Through Extremal Process
- lAAAI 2021, Fast and Compact Bilinear Pooling by Shifted Random Maclaurin
- lAAAI 2021, Rejection Sampling for Weighted Jaccard Similarity Revisited
Optimal Estimation of High Dimensional Smooth Additive Function Based on Noisy Observations
论文链接:http://proceedings.mlr.press/v139/zhou21c/zhou21c.pdf
随着机器学习在工业界中被广泛应用 , 各类算法和模型开始触及个人用户数据的方方面面 。 在使用各类算法和利用用户数据为大众生活提供便利的同时保障用户隐私就显得尤为重要 。 一个简单且被普遍使用的应对策略就是在收集的数据上通过添加噪声来达到保护用户隐私的目的 。
虽然添加噪声从一定程度上解决了保护用户隐私的问题 , 但随之而来的是运用带有噪音的高维数据到训练好的模型中 , 预测结果的准确率往往很低 。 造成此现象的根本原因是在高维统计学习中的一个基本问题:带有噪声的高维数据会使得模型预测的偏差随维度增加而变大 。
在本篇论文中应用了国际上前沿的统计学习理论专家们在近两年开发的iterative bootstrap技术 , 在高维additive model这一经典且被广泛应用的非参统计回归模型中 , 从理论上以及实践中解决了上述问题 。 相比于已有的方法 , 我们的估计模型不仅可以有效的降低高维度带来的误差 , 并且被证明是很多经典问题上的最优解 。 此类前瞻性的工作在随着业界对用户数据隐私越来越重视 , 而产生深刻且有意义的影响 。
3.潜变量模型的参数估计方法
On Estimation in Latent Variable Models
论文链接:http://proceedings.mlr.press/v139/fang21a/fang21a.pdf
潜变量模型是对不可观测变量进行数学建模 。 它在经济学、心理学、统计学和机器学习中扮演了重要的角色 。 由于潜变量的存在 , 人们通常不能直接对似然函数最大化来球的最优的参数估计而却需要通过繁琐的积分来去掉潜变量的影响 , 从而导致计算复杂度的提升 。
本文提出了一个基于方差减小化的随机梯度下降方法的参数估计算法来加速潜变量模型参数估计的过程 。 该方法不需要求解精确的后验分布 , 加快了迭代过程 , 可以让估计值更快的进入收敛区域 。 在不同的统计结构假设下 , 文章给出了算法收敛性的证明 , 复杂度上界以及估计值的渐近性质 。 当样本量充分大时 , 实验结果表明该方法可以比经典的梯度下降法有着更快的收敛速度 。
文章图片
4.基于双聚类模型的贝叶斯变分推断理论
On Variational Inference in Biclustering Models
【量化|百度入选ICML、IJCAI、ISIT等机器学习顶会的论文都在关注什么?】论文链接:http://proceedings.mlr.press/v139/fang21b/fang21b.pdf
双聚类模型是对数据矩阵同时进行行聚类和列聚类的一种统计学习方法 。 它在基因表征分类 , 用用户行为分析 , 局部特征学习中起着重要的作用 。 目前双聚类算法大多基于数据出发 , 例如谱算法 , 双重k-means算法 , 贝叶斯抽样算法等 , 而双聚类算法的理论性质却没有得到充分的研究 。
近来贝叶斯变分推断已经成为了一个热门的机器学习计算方法 , 其对具有隐变量结构的复杂模型参数估计方法有着特殊的优势 。 它利用选取合理的近似后验分布来节省计算的复杂度 。 在这个变分推断的框架下 , 我们给出了双聚类模型参数估计值的一系列全新的理论 , 包括变分估计的上界和下界 , 分类的强弱收敛性 , 变分梯度下降法的局部收敛和全局收敛的性质等 。 这些新的理论给机器学习领域带来了对贝叶斯变分推断和双聚类模型的交叉领域更深的理解 。
5.融合声音和文本编码的跨模态多语言预训练和语音翻译模型
文章图片
Fused Acoustic and Text Encoding for Multimodal Bilingual Pretraining and Speech Translation
论文链接:http://proceedings.mlr.press/v139/zheng21a/zheng21a.pdf
近来 , 文本和语音表示学习成功大幅提升了许多与语言与语音相关的任务 。 但是 , 现有方法只能从文本或语音的一种输入模态的数据中学习 , 而许多常见的跨模态的任务 , 例如语音翻译 , 则需要统一的声音和文本表示 。
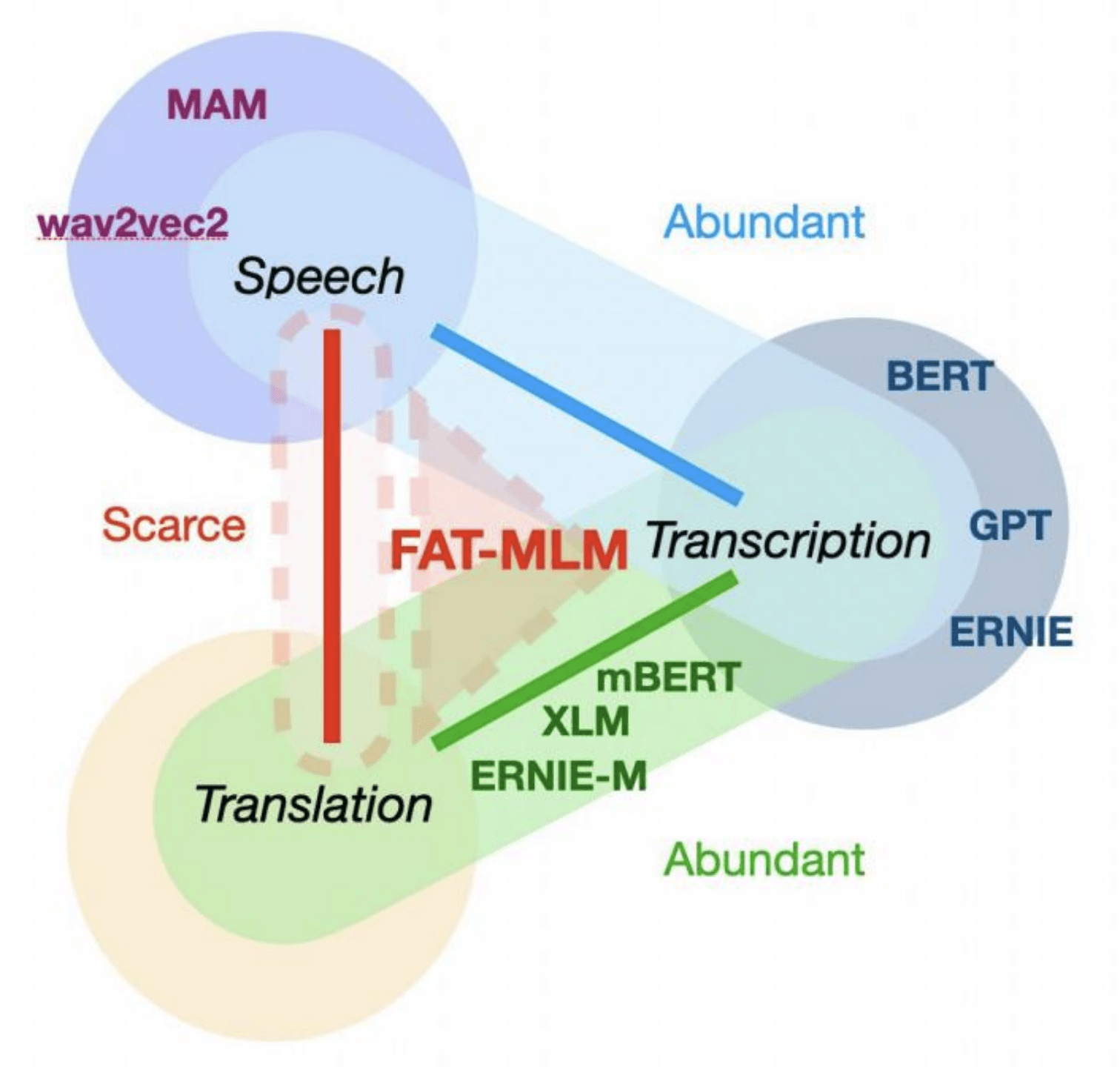
为解决这个问题 , 我们提出了一种融合语音和文本的语言模型Fused Acoustic and Text Masked Language Model(FAT-MLM) , 该模型可以学习统一的语音和文本表示 。 在这种跨模态表示学习框架下 , 我们进一步提出了融合语音和文本的端到端语音翻译模型FAT-ST 。 在三个翻译方向上进行的实验表明 , 我们在FAT-MLM预训练基础上的语音翻译模型可以显着提高翻译质量(+5.90 BLEU) 。
百度IJCAI 2021论文
文章图片
6.UniMP:基于掩盖标签预测策略的统一消息传递模型
Masked Label Prediction: Unified Message Passing Model for Semi-Supervised Classification
论文链接:https://arxiv.org/abs/2009.03509
GitHub: https://github.com/PaddlePaddle/PGL/tree/main/ogb_examples/nodeproppred/unimp
一般应用于半监督节点分类的算法分为图神经网络和标签传递算法两类 , 它们都是通过消息传递的方式(前者传递特征、后者传递标签)进行节点标签的学习和预测 。 其中经典标签传递算法如LPA , 只考虑了将标签在图上进行传递 , 而图神经网络算法大多也只是使用了节点特征以及图的链接信息进行分类 。 但是单纯考虑标签传递或者节点特征都是不足够的 。
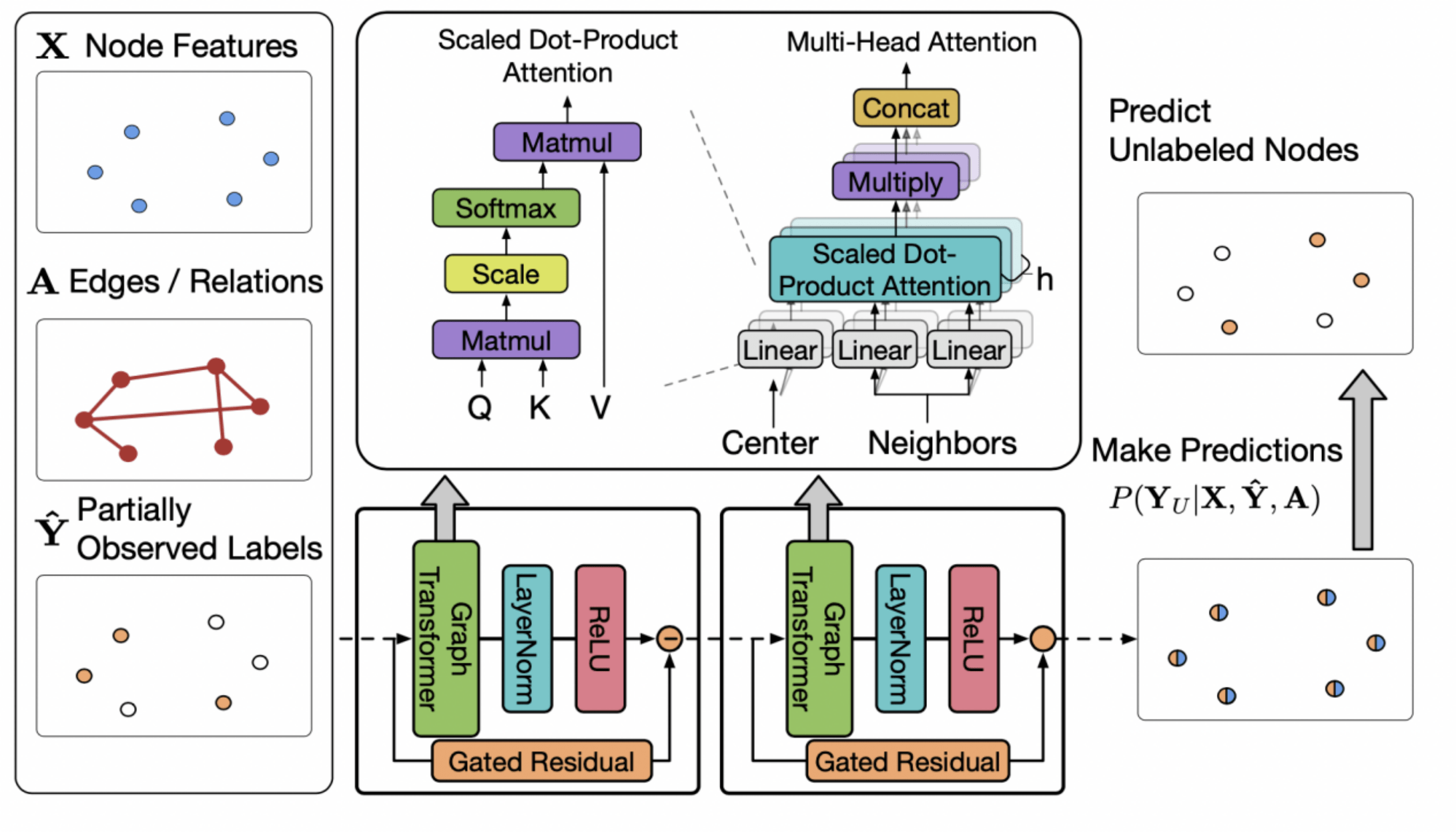
百度提出的统一消息传递模型UniMP将上述两种消息统一到框架中 , 同时实现了节点的特征与标签传递 , 显著提升了模型的泛化效果 。 UniMP以Graph Transformer模型作为基础骨架 , 联合使用标签嵌入方法 , 将节点特征和部分节点标签同时输入至模型中 , 从而实现了节点特征和标签的同时传递 。
简单的加入标签信息会带来标签泄漏的问题 , 即标签信息即是特征又是训练目标 。 为此 , UniMP提出了标签掩码学习策略 。 UniMP每一次随机将一定量的节点标签掩码为未知 , 用部分已有的标注信息、图结构信息以及节点特征来还原训练数据的标签 。 最终 , UniMP在OGB三个半监督节点分类任务上取得SOTA效果 , 并在论文的消融实验上 , 验证了方法的有效性 。
文章图片
7.基于知识蒸馏和跨模态匹配的弱监督稠密视频描述生成
Weakly Supervised Dense Video Captioning via Jointly Usage of Knowledge Distillation and Cross-modal Matching
论文链接:https://arxiv.org/abs/2105.08252
稠密视频描述生成是近两年来多模态生成的热门研究方向之一 , 其挑战在于对大规模领域标注数据的强依赖 。 为了解决这个难题 , 本文创新性地提出了结合知识蒸馏(Knowledge Distillation)和跨模态匹配(Cross-modal Matching)的弱监督稠密视频描述生成模型 。 在不需要视频精彩片段标注的前提下 , 仅使用外领域多源视频描述数据 , 即可同时实现视频精彩片段提取和细粒度的内容描述生成 。 进一步地 , 我们首次使用图文描述数据显著增强了视频描述生成的效果 。
实验表明 , 本文提出的方法能够有效利用外部数据集的知识 , 准确的定位视频的精彩片段并生成流畅、准确的描述文本 。 在精彩片段提取子任务上 , 基于我们提出的知识蒸馏策略训练的模型甚至超过全监督数据训练的模型的效果 。 在描述生成子任务上 , 本文在ActivityNet Captioning数据集上取得了当前的最优表现 。 同时 , 本文也为该任务使用大规模弱监督数据提供了一种有效的解决方案 。
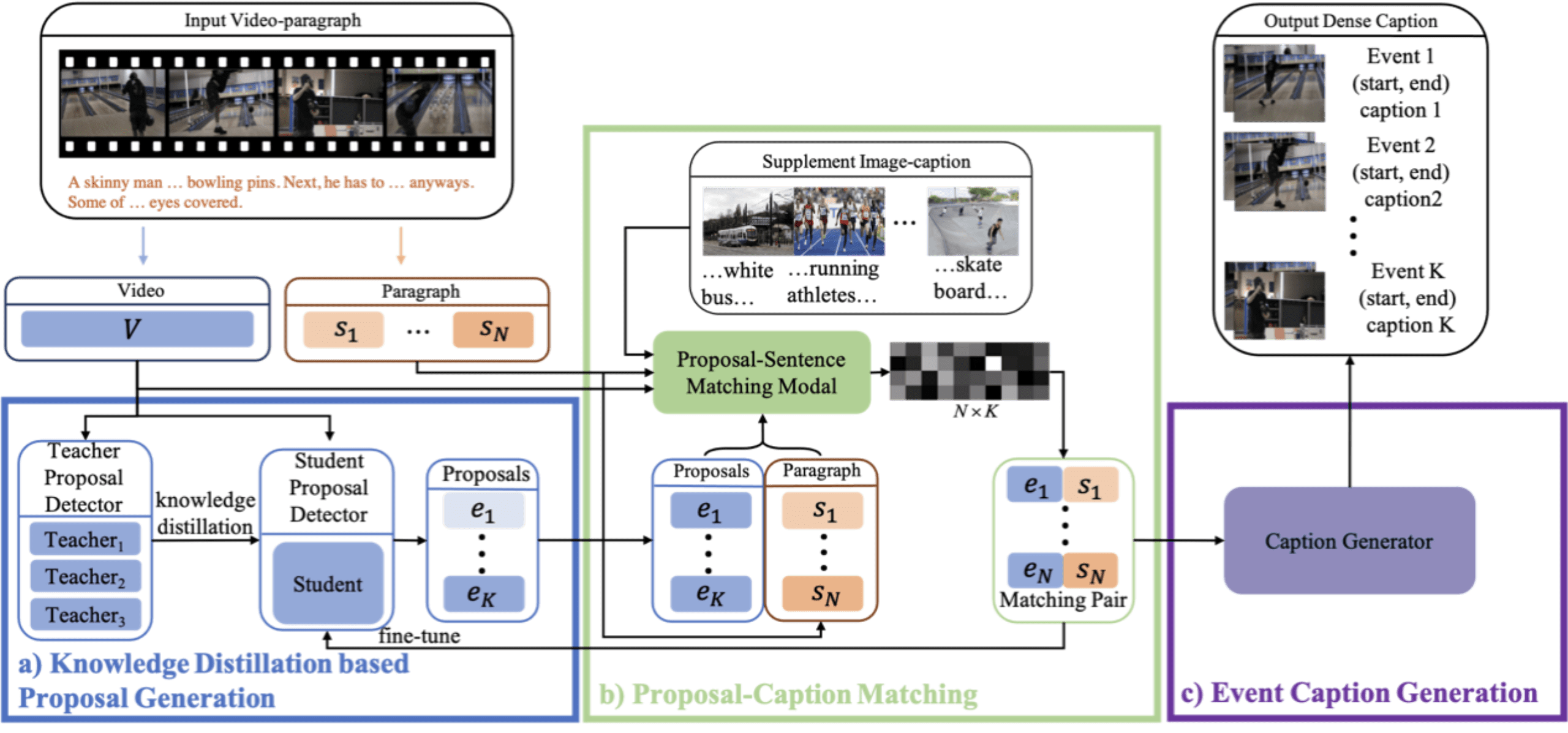
文章图片
8.Seq2Subgraph:一种基于子图结构的医疗文本处理新框架
A Novel Sequence-to-Subgraph Framework for Diagnosis Classification
基于电子病历文本的AI辅助诊断是智慧医疗领域最重要和最具挑战的问题之一 。 传统的NLP深度学习在开放域下以序列模型建模文本为主 , 若以该方式处理医疗文本(例如电子病历)则难以表达复杂的医学概念之间二元或多元知识关系 , 难以将蕴含在文本段落中的复杂医学关系与临床诊疗推理结合 。
在本文中 , 我们提出了一种新的医疗文本处理框架Seq2Subgraph , 它通过结合医学知识图谱 , 将医疗文本处理成多层级的子图结构 , 改变了传统NLP序列模型处理医疗文本的固定套路 , 能更好的区分同时患有多疾病的病历中不同疾病关联的病情信息 , 兼顾医疗文本的结构特征和序列特征 。 在中文和英文电子病历数据上 , 本文提出的算法均取得了最佳的效果 。
值得一提的是 , 该工作是继2020年ACL和IJCAI后 , 百度智慧医疗在AI辅助诊断上的延续性技术创新 。 在突破了诊断可解释性和知识与数据双驱动诊疗技术后 , 本次研究进一步革新了医疗文本处理模式 , 在维度升级的复杂电子病历下 , 针对数据与知识的联合建模方式做了更深层次的探索和应用 。
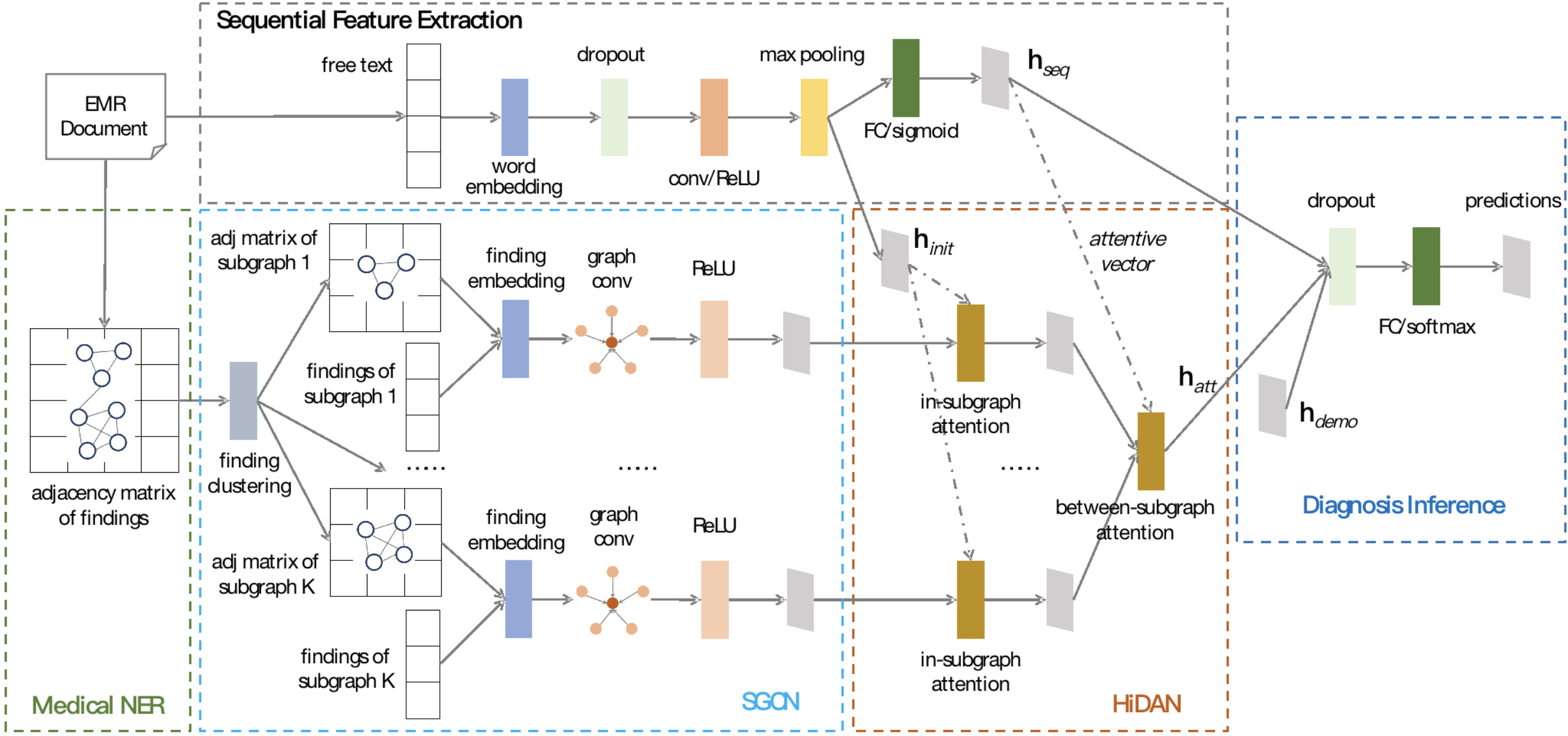
文章图片
9.监控场景下的弱监督时空异常检测
Weakly-Supervised Spatio-Temporal Anomaly Detection in Surveillance Video
针对视频监控场景下的异常事件检测 , 我们提出弱监督时-空异常检测(WSSTAD)的新任务 。 即 , 仅仅利用视频级别标签作为弱监督信号 , 对输入的一段视频中异常事件出现的时间以及空间位置进行检测 。 前序研究中 , 弱监督方法仅能实现单一时间纬度的异常定位 , 无法进行空间位置的定位 。 本文提出的弱监督算法框架 , 首次实现了时间-空间两个纬度的异常事件定位 , 并且在经典数据集中取得了最佳的指标 。 由于训练阶段仅需要视频级别的标签 , 本文提出的方法可以极大节省标注人力 。
具体而言 , 我们采用多实例学习框架(MIL) , 首先会从输入视频中提取不同粒度的时-空proposal作为实例 , 其中包括由连续帧中检测框所组成的tube实例 , 以及由视频片段组成的videolet实例 。 随后 , 将tube实例以及videolet实例分别送入一个双分支的网络 , 在每个网络分支中 , 采用C3D提取特征 , 并采用注意力机制实现特征增强 。 最后 , 通过两个分支之间的互助损失 , 实现时-空两个维度定位的互助学习 。 整体算法框架如下图所示 。 本文提出的方法在ST-UCF-Crime以及新提出的STRA两个数据集上获得了最佳的效果 , VAUC分别达到了87.65%和92.88% 。
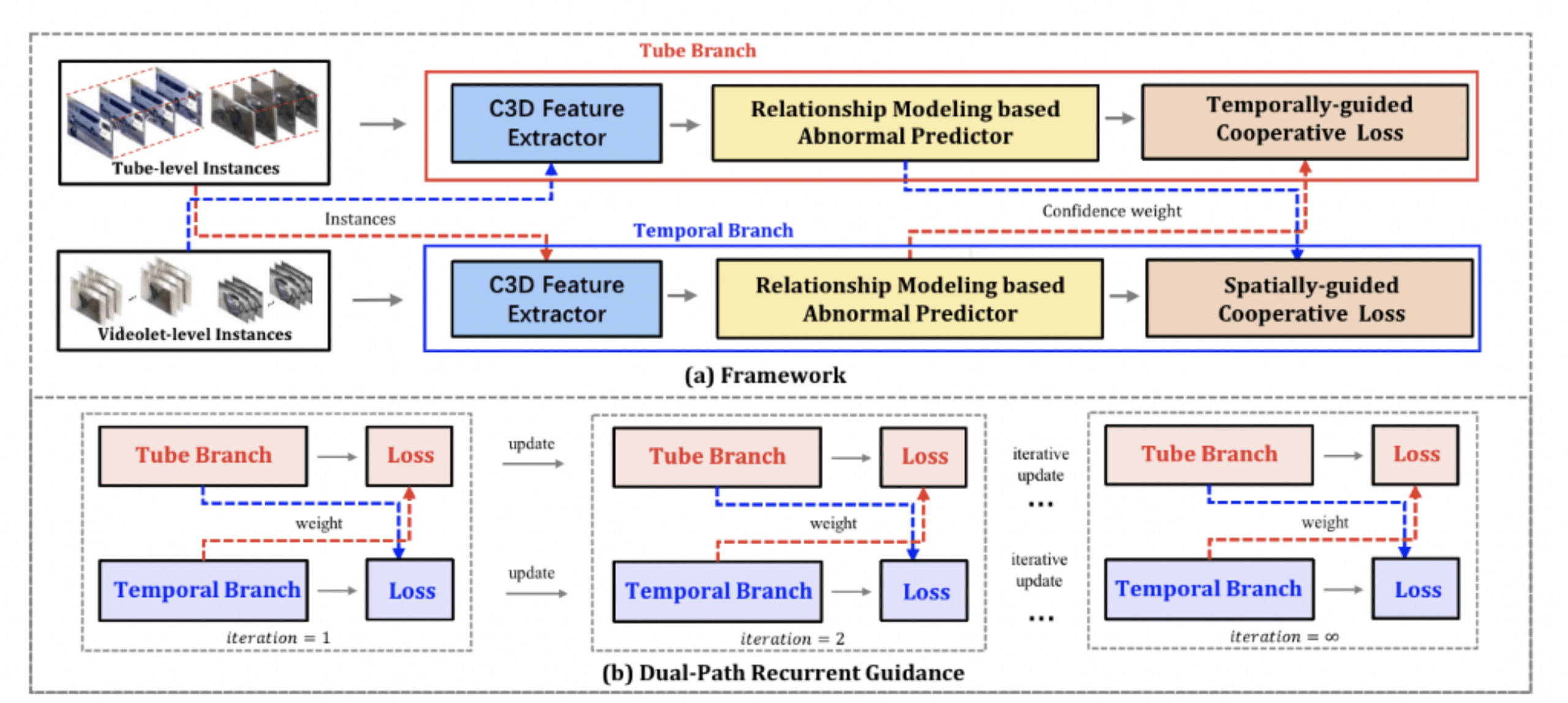
文章图片
10.DU-VAE: 从隐变量空间多样性和不确定的角度增强变分自编码器
Regularizing Variational Autoencoder with Diversity and Uncertainty Awareness
作为最受欢迎的生成式表征模型之一 , 变分自编码器近年来已经被应用于各个领域 。 然而在具体实践中 , 当我们使用拟合能力很强的模型作为解码器时 , 变分自编码器时常会遇到后验坍缩(posterior collapse) 现象 。 彼时 , 所有样本的隐变量后验分布趋近于相同 , 模型无法学习到有效的表征 。
针对于这一问题 , 本文首先从隐变量空间的多样性与不确定性两种几何特性出发 , 分析发现只需要简单控制后验参数的分布 , 就可以有效地避免后延坍缩现象 。 并以此为理论依据提出 , 通过对于后验参数同时使用批处理标准化(Batch Normalization)与Dropout正则化 , 实现对于后验参数的控制 。 在三个公开数据集上的数值试验表明 , 该算法有效地提升了变分自编码器的性能 , 在数据拟合与分类任务中都取得了最好的效果 。
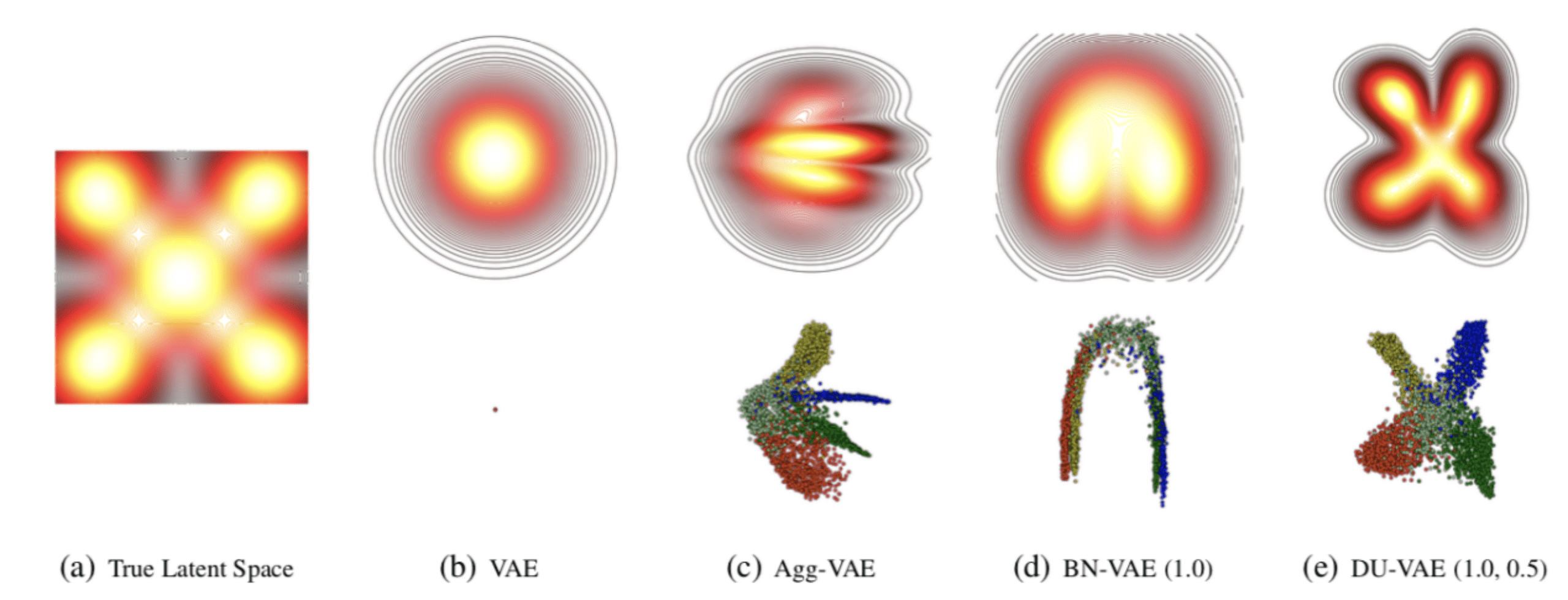
文章图片
11.关于神经网络泛化、记忆与频谱偏好的再思考
Rethink the Connections among Generalization, Memorization, and the Spectral Bias of DNNs
本文从频谱偏好 (spectral bias)入手研究神经网络的泛化性、记忆性的关系 。 近来的研究发现神经网络在训练过程中往往呈现出泛化误差二次下降的现象 , 即在优化过程中其泛化误差呈现出“下降-上升-再次下降”的变化趋势 。 而这显然与以往对频谱偏好的单调性结论(神经网络从低频到高频、从简单到复杂地引入频率分量)相矛盾 。
我们在泛化误差二次下降的实验设置下(引入部分标签噪声并且训练较多的回合数)对神经网络输出的频谱进行了统计 。 实验现象如下图 , 在前两个过程中高频分量被不断引入到神经网络的输出 , 表明模型的复杂度不断增加 。 然而通过进一步训练 , 模型的高频分量在第三个阶段由上升转为下降 , 使得模型的泛化误差再次开始下降 。 我们进一步发现 , 频谱的非单调变化是两种情况的组合:训练流形上的输出持续地引入高频分量来拟合噪声点 , 而非训练流形的输出频谱逐渐趋向于低频分量 。 训练流形上的准确率在记忆噪声点后开始下降 , 但是非训练流形的准确率却在相同阶段持续提升 。 这两种频谱现象的叠加效果最终揭示了泛化误差的二次下降 。
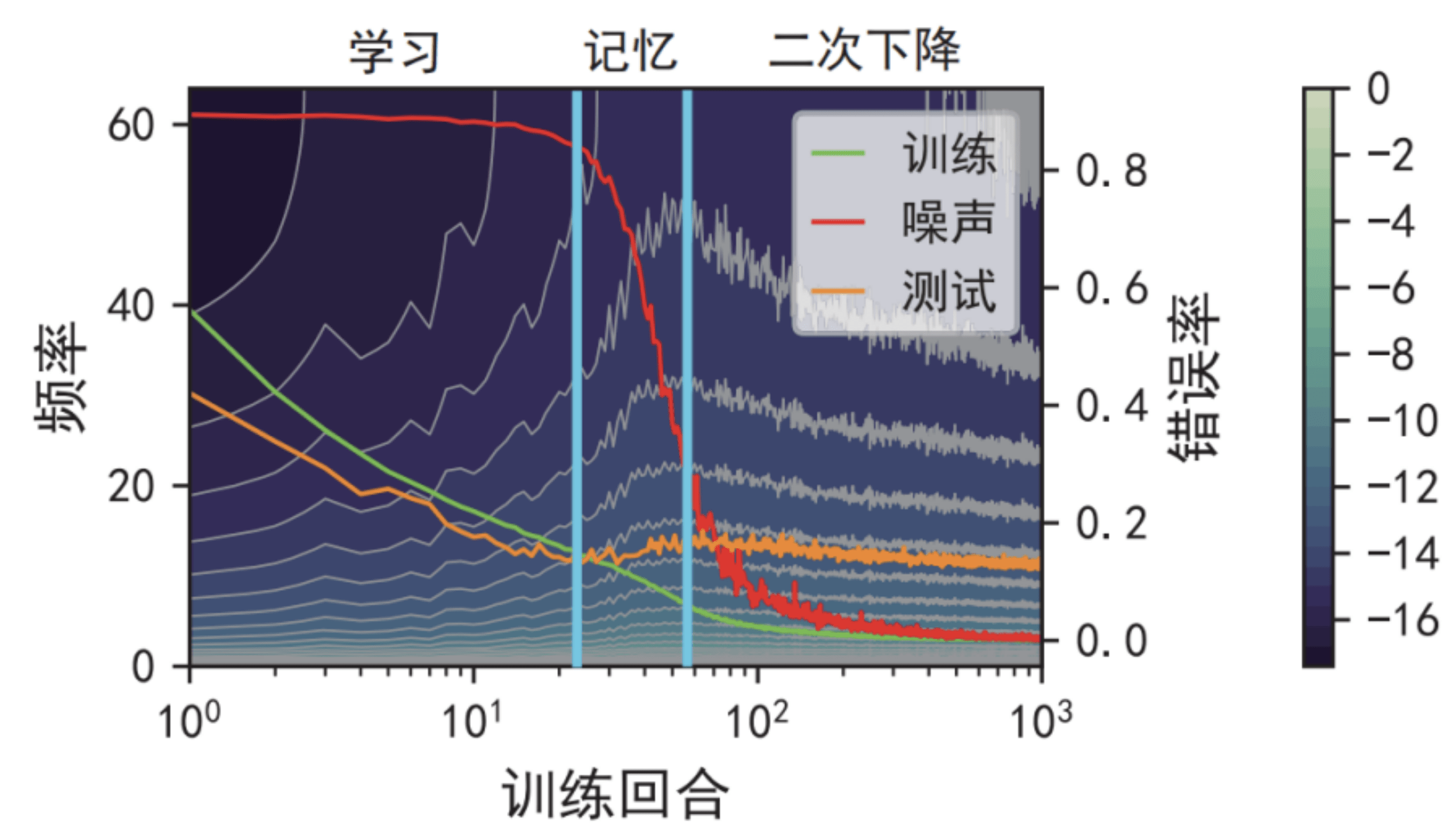
文章图片
12.不确定性感知二值神经网络
Uncertainty-aware Binary Neural Networks
二值神经网络(BNN)是一种很有前途的机器学习解决方案 , 用于在资源有限的设备上部署 。 最近训练BNN的方法已经产生了令人印象深刻的结果 , 但是最小化全精确网络的精度下降仍然是一个目前面临的挑战 。 其中一个原因是 , 传统的BNN忽略了权值接近于零所引起的不确定性 , 导致了学习时的不稳定性或频繁翻转 。
本文研究了接近零的权重消失的内在不确定性 , 这使得训练容易受到不稳定性的影响;同时引入了一种不确定性感知的BNN (UaBNN) , 利用一种新的映射函数确定符号(c-sign)来减少这些权值的不确定性 。 本文介绍的c-符号函数是第一个训练具有降低不确定性的BNN进行二值化的函数 。 该方法导致了神经网络的受控学习过程;同时还介绍了一种简单而有效的基于高斯函数的不确定度测量方法 。 大量实验表明 , 该方法改进了多种BNN方法 , 提高了训练的稳定性 , 取得了比现有技术更高的性能 。
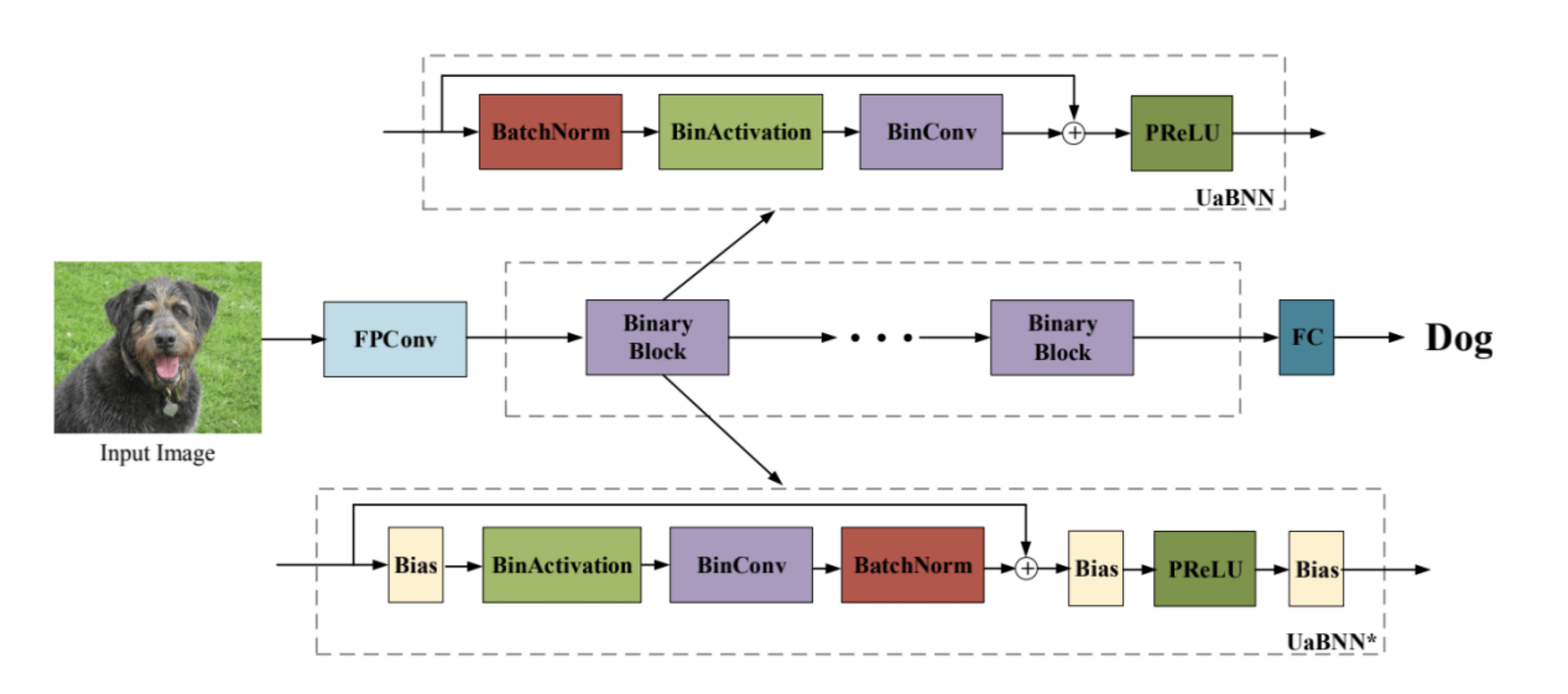
文章图片
13.疟疾控制的样本高效强本学习方法
Data-Efficient Reinforcement Learning for Malaria Control
论文链接: https://arxiv.org/abs/2105.01620
成本敏感任务下的序列决策通常都令人望而生畏 , 尤其是对人们日常生活有重大影响的问题 , 例如疟疾控制、治疗建议 。 政策制定者面临的主要挑战是需要在与复杂环境只做几次互动的前提下 , 作出正确的策略 。 本工作引入了一种实用的、数据高效的策略学习方法 , 名为方差鼓励的蒙特卡洛树搜索方法 , 它可以应对数据量极少的情况 , 并且只需几次试验就可以学习到控制策略 。 具体来说 , 解决方案采用了基于模型的强化学习方法 。 为了避免模型偏差 , 我们应用高斯过程回归来显示建模状态的转换(称为世界模型) 。 基于这个世界模型 , 我们提出了通过估计的方差来衡量世界的不确定性 。 并在蒙特卡洛树搜索中将估计的方差作为额外的奖励 , 使得探索方法能更好的平衡探索和利用 。 此外 , 我们推导了方法的样本复杂度 , 结果表明方差鼓励的蒙特卡洛树搜索方法是样本高效的 。 最后 , 在KDD CUP的强化学习比赛中本方法出色的表现和大量的实验结果证实了其在具有挑战性的疟疾控制任务中明显优于SOTA 。
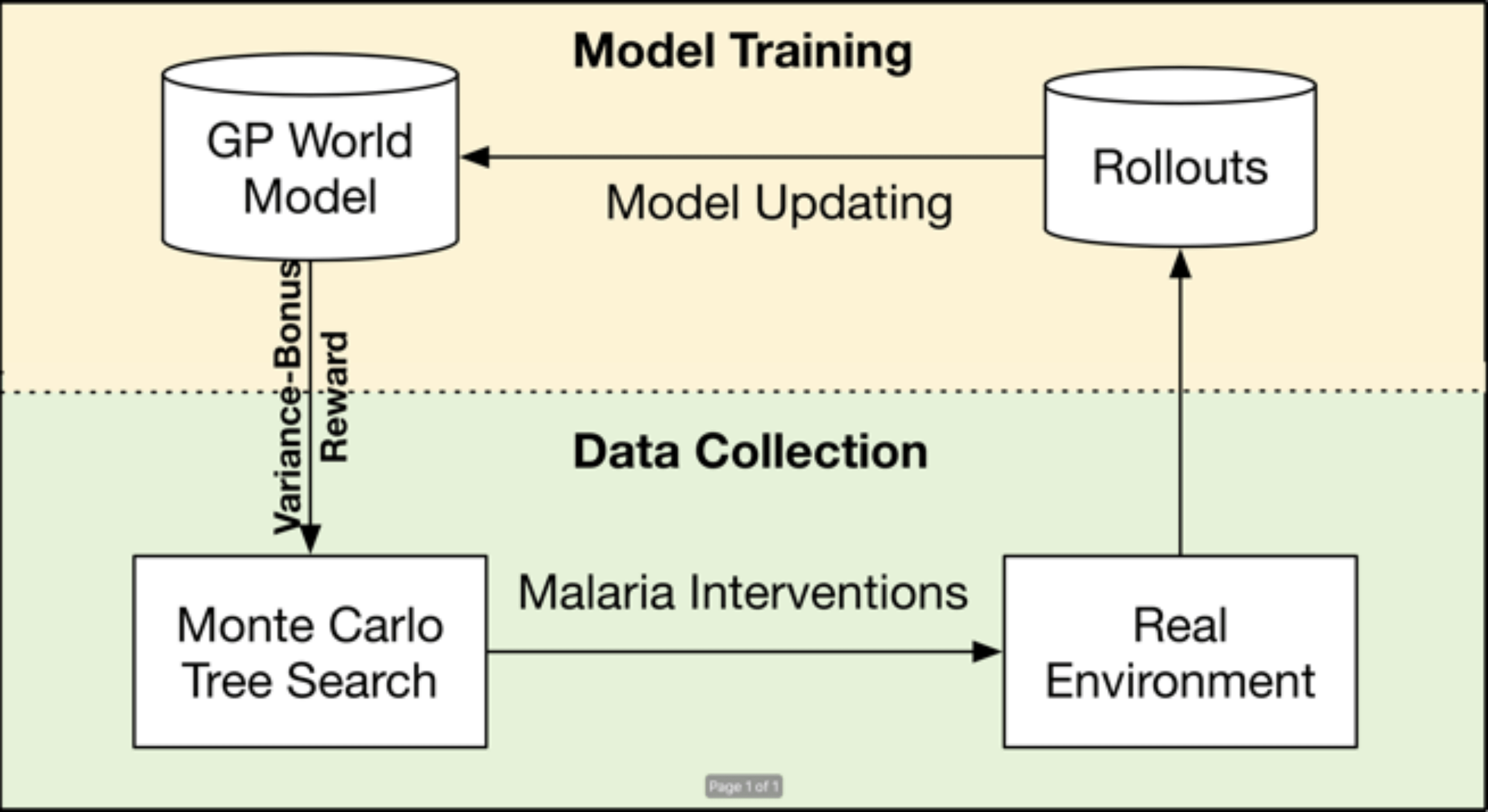
文章图片
14.基于模式扩展的对抗策略学习网络在序列推荐中的应用
Pattern-enhanced Contrastive Policy Learning Network for Sequential Recommendation
本论文跟北京邮电大学、武汉大学多位教授合作 , 关注的是序列推荐场景中对用户历史序列的去噪问题 。 由于用户行为的随机性和多样性 , 用户的历史记录中并不是所有的商品都对预测下一次的行为有帮助 。 大多数序列推荐方法都无法抽取出与目标商品存在可信赖的序列依赖关系 , 模型的可解释性也受到了很大的限制 。 我们希望从历史购物序列中挑选出对预测具有真正影响力的相关商品 , 去除序列中不相关的商品 , 从而提升序列推荐效果 。 如何在无标注的情况下 , 自动挖掘出与推荐结果相匹配的时序模式 , 提高推荐的可解释性和准确性 , 是本文最大的挑战 。 基于以上几点考虑 , 我们把序列去噪问题形式化为一个马尔可夫决策过程 , 将挖掘出来的序列模式用以增强每个商品的表达 , 作为指导去噪过程的一种先验知识 。 然后采用一种强化学习的策略模块 , 来判定用户购物序列中的商品与目标商品之间的关联性 , 从而将相关和不相关的商品区分开 , 并通过一个对比学习模块来加强模型的学习进程 。 实验结果表明 , 我们提出的方法可以有效地提取出相关商品并提升推荐效果 。
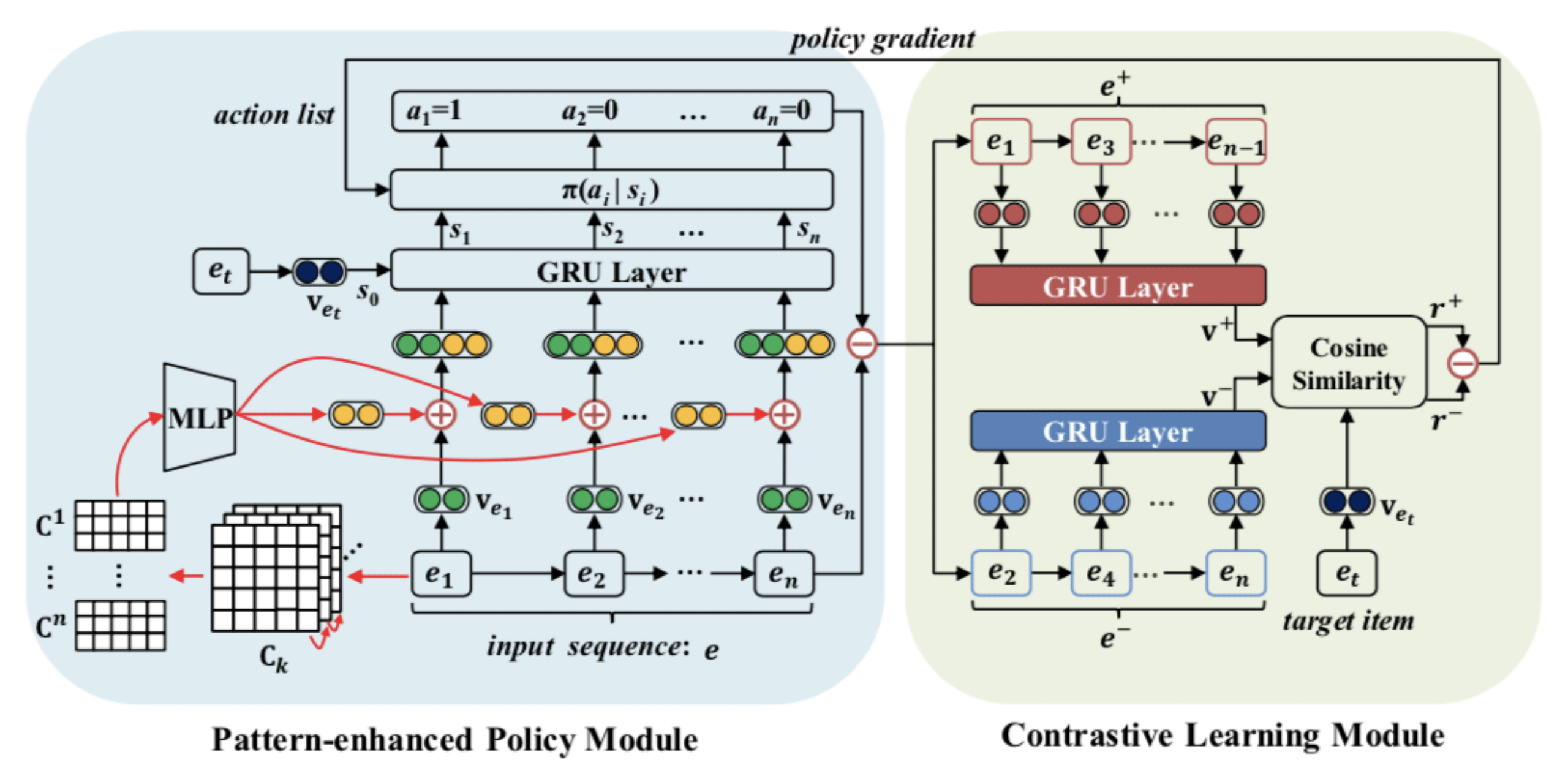
文章图片
15.基于语义共享模型的有监督跨模态检索
Rethinking Label-Wise Cross-Modal Retrieval from A Semantic Sharing Perspective
有监督跨模态检索是当前多模态领域的研究热点 , 旨在利用一种模态的样本去检索其他模态相似语义的样本 。 由于不同模态特征表示的差异性(异构鸿沟) , 跨模态检索需要为不同模态学习语义一致的特征表示 。 传统方法通常使用真实标签和一致性损失来约束模态内和模态间的特征表示 , 但忽略了一致性损失对于各模态分类性能的影响 。
本文重新思考了一致性损失对有监督跨模态检索的影响 , 发现由于不同模态的嵌入模型具有不同的泛化性能 , 使用一致性损失的端到端联合学习会导致各模态的分类性能下降 , 进而影响跨模态语义一致特征表示的学习 。 为此 , 本文提出一种基于语义共享分类模型的有监督跨模态检索方法 , 该模型直接采用基于自注意力的共享分类模型 , 并对两个模态进行迭代训练 , 保证各模态在共享模型上的分类性能 , 进而学习语义一致的特征表示 , 以此提升各模态的检索性能 。 实验表明 , 在图像-文字跨模态检索的标签任务上 , 所提方法在NDCG指标下取得了比现有技术更高的检索性能 。
百度ISIT 2021论文
文章图片
16.乱序稀疏信号恢复的理论分析和实际算法
Sparse Recovery with Shuffled Labels: Statistical Limits and Practical Estimators
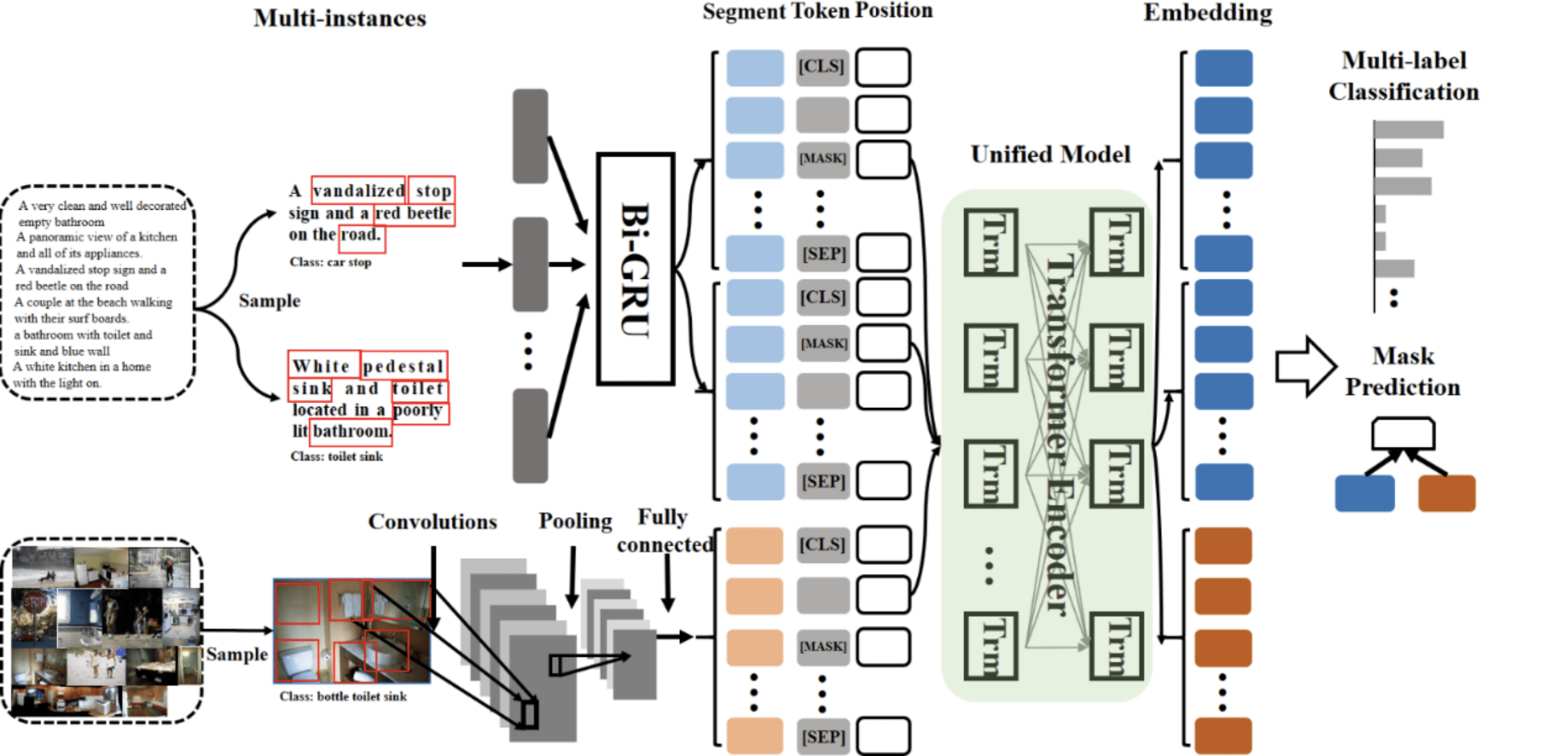
我们首次考虑了在乱序情况下恢复稀疏信号 。 相较之前的工作 (需要观测数量n大于二倍的信号长度p) , 我们的工作首次考虑了n小于p的情况 。 假设稀疏信号只有个非零元素 , 我们的目标是同时恢复排列关系和稀疏信号的支撑集两个信息 。 这个工作主要有三方面的贡献:
1)首次得到了正确恢复上述两个信息说需要的最少观测数量n和最低信噪比SNR 。 值得注意的是 , 我们对上述SNR的最低要求给出了一个基于香农编码理论的非常直观的解释 。 大致思路是将观测关系建模成一个通信过程(如下图所示) , 基于香农的理论 , 正确的解码需要码率小于信道容量 , 借此我们可以得到关于SNR的最低要求 。
文章图片
2)提出了一个基于遍历搜索的估计方法 , 并证明只要满足上述的最低要求 , 就可以得到正确的信息(在某些情况下) 。
3)提出了一个实用的算法 , 并证明了在某些情况下我们的算法在第一步就能得到正确的信息 。 鉴于遍历搜索的算法有很大的时间复杂度 , 我们提出了一个相继更新支撑集和排列矩阵的迭代算法 。
这方面的研究在数据库和数据隐私方面拥有非常广泛的应用 。 百度在该领域已经积累了不少世界领先的成果 , 包括:
- lIEEE Trans Information Theory 2021, The Benefits of Diversity: Permutation Recovery in Unlabeled Sensing from Multiple Measurement Vectors
- lICML 2020, Optimal Estimator for Unlabeled Linear Regression
- lJMLR 2020, Two-stage approach to multivariate linear regression with sparsely mismatched data
- lISIT 2019, Permutation recovery from multiple measurement vectors in unlabeled sensing
- lUAI 2019, A sparse representation-based approach to linear regression with partially shuffled labels
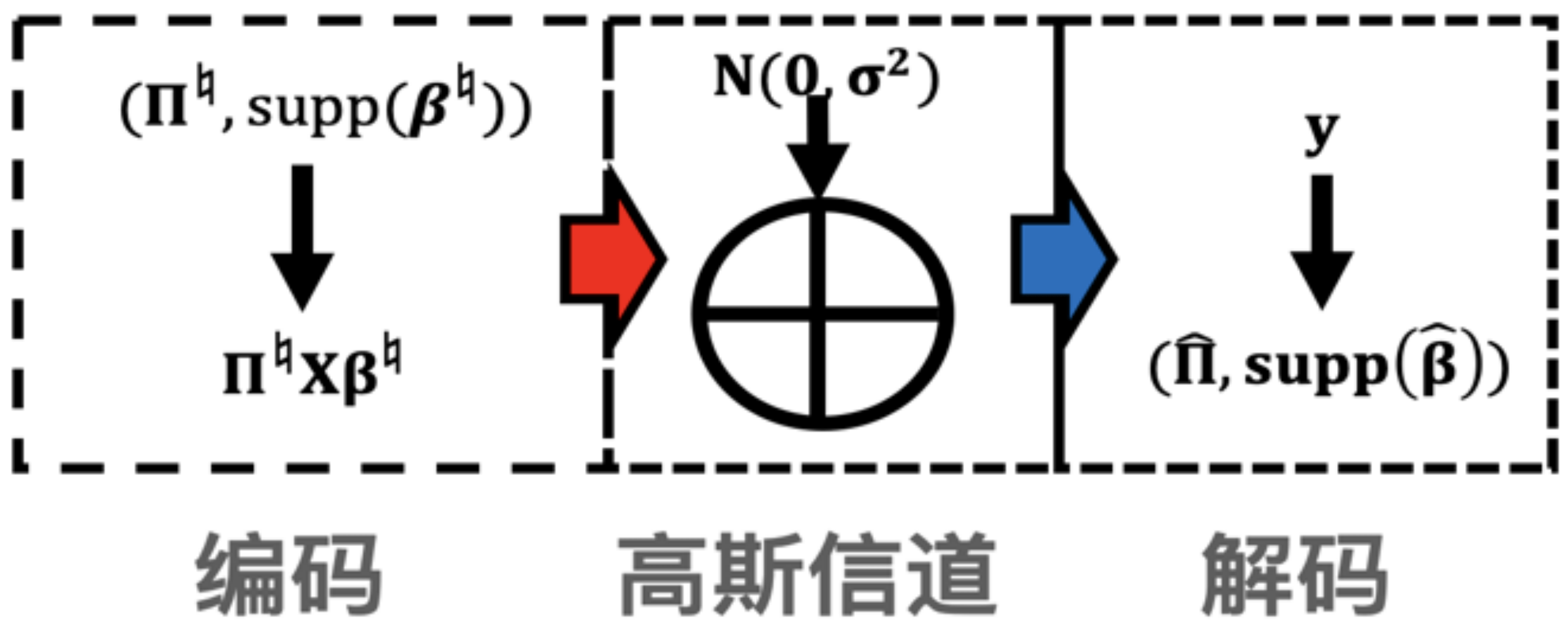
FROS: Fast Regularized Optimization by Sketching
本文提出了一种用矩阵缩略(sketching)的方式加速优化的通用方法 。 矩阵缩略是随机优化领域的重要方法 , 其主旨是通过矩阵缩略将原优化问题的数据矩阵进行压缩 , 从而得到一个较小规模的新优化问题 。 通过解小规模的新问题 , 矩阵缩略方法可以得到原优化问题的近似解 。 随机优化领域里已经充分研究了在凸优化问题上矩阵缩略的结果 。 然而 , 目前的方法局限在凸优化上 , 对于目标函数里有非凸正则项的情况 , 矩阵缩略的效果仍然是一个公开性问题 。 本文提出了针对非凸正则项的矩阵缩略方法 , 在理论上证明了矩阵缩略对于带非凸正则项的优化问题仍然可以有效地近似原问题的解 。 基于这个理论结果 , 本文进一步提出了一种迭代式的优化方法 , 在每一步迭代中都用矩阵缩略方法来逼近原问题的解 。 通过迭代使用矩阵缩略 (图(a)), 近似解可以以几何级数逼近原问题的解(图(b))。
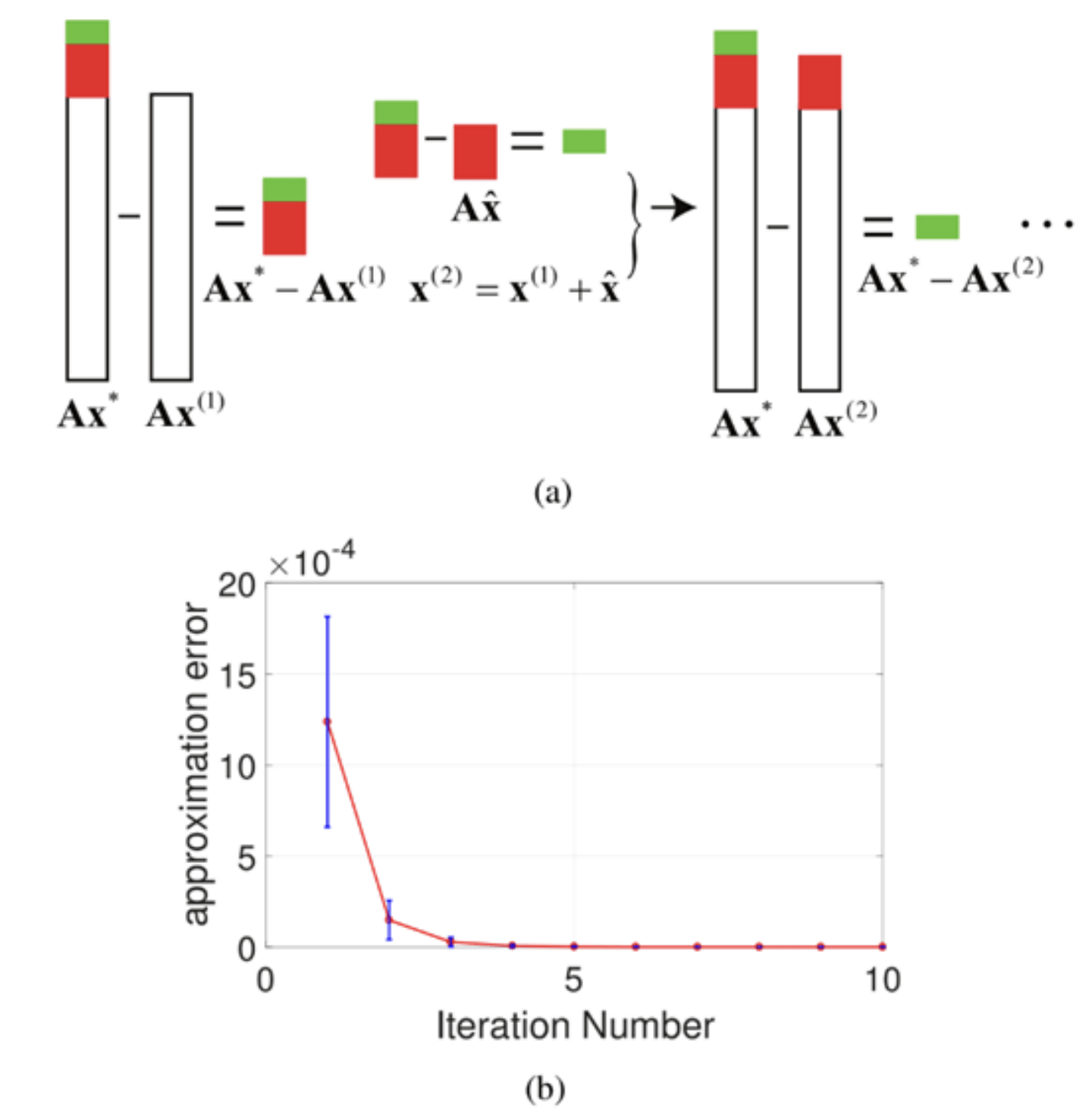
文章图片
Sketching和数据压缩是一个学术界和工业界都非常热门的课题 , 百度的研究员 , 从2005年(加入百度前)就开始从事这方面的研究 , 曾获得KDD和NIPS的最佳论文奖 , 和CommunicationsoftheACM的受邀曝光论文 。 近年来 , 百度在这方面的论文包括:
- lAAAI 2019, Sign-Full Random Projection
- lNeurIPS 2019, Random Projections with Asymmetric Quantization
- lNeurIPS 2019, Generalization Error Analysis of Quantized Compressive Learning
- lNeurIPS 2019, Re-randomized Densification for One Permutation Hashing and Bin-wise Consistent Weighted Sampling
- lIEEE Trans Information Theory 2018, On the Trade-Off Between Bit Depth and Number of Samples for a Basic Approach to Structured Signal Recovery From b-Bit Quantized Linear Measurements
- lKDD 2018, R2SDH: Robust Rotated Supervised Discrete Hashing
- lNIPS 2017, Simple strategies for recovering inner products from coarsely quantized random projections
- lWWW 2017, Theory of the GMM Kernel
Two-Timescale Stochastic EM Algorithms
期望最大化 (EM) 算法是学习潜变量模型的流行方法 。 在本文中 , 我们基于随机更新的两阶段方法提出了一类称为双时间尺度EM方法的通用算法 , 来解决潜变量模型中很困难的非凸优化任务 。 我们通过在两个噪声源上调用该方法每个阶段的方差减少优点来激发双动态的选择 , 增量更新的索引采样和MC近似 。 我们为非凸目标函数建立有限时间和全局收敛边界 。 文中还介绍了在各种模型上的数值应用 , 例如用于图像分析的可变形模板或高斯混合模型 , 来说明我们的发现 。

文章图片
19.量子相干性提纯和随机数提取的有限元分析
Finite Block Length Analysis on Quantum Coherence Distillation and Incoherent Randomness Extraction
论文链接:https://arxiv.org/abs/2002.12004
量子计算被认为是下一代计算科技的核心 , 其强大的计算能力来源于量子比特所特有的相干性或叠加性 。 由于外界环境会干扰量子比特 , 如何长时间维持或者提高/提纯一个量子比特的相干性是一个急于解决的问题 。 理论上 , 研究者们对多个弱相干量子比特转化到少量强相干量子比特进行了大量研究 , 并且重点关注前后量子比特的转化率 。 之前的研究在各种情形下对此转化率进行了一阶估计 , 但实际使用时非常粗糙 。
本文通过引入一个量子随机数提取的新模型 , 并建立此模型和量子相干性提纯的一一对应关系 , 首次获得了相干比特转化率的精确的二阶估计 , 极大地强化了已有的结果 。 本文在推进量子相干性研究的同时 , 也证明了相干性和随机性准确的对应关系 , 揭示了两种不同量子属性的共同本质 。
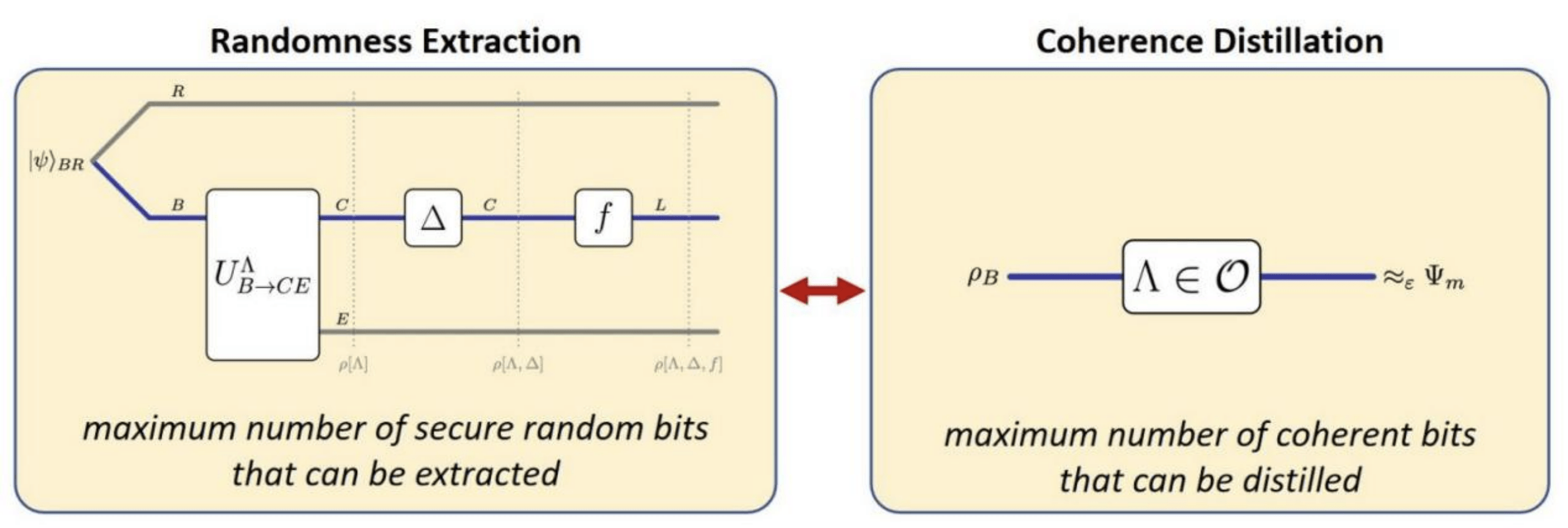
文章图片
20.量子信道反馈辅助信道容量的上界
Upper Bound on the Classical Capacity of A Quantum Channel Assisted by Classical Feedback
论文链接:https://arxiv.org/abs/2010.01058
量子通信是量子科技的核心 , 量子信道用于传输经典信息的能力是量子信息研究的中心课题 。 不同于经典信息论 , 量子信息论中的信道容量问题至今还没有完全解决 , 如何确定量子信道的信道容量是非常关键但又充满挑战的问题 。
本文通过引入两方量子信道的信息度量的方法 , 首次给出了量子信道反馈辅助信道容量的系统分析 。 该文中建立的量子信道容量的上界可以通过半正定规划进行高效计算 , 可直接用于估计量子信道在反馈辅助的情况下能无错误传送的最大信息率 。 值得一提的是 , 本文作者之一是著名的解决大数分解问题量子算法的提出者——Peter Shor教授 。
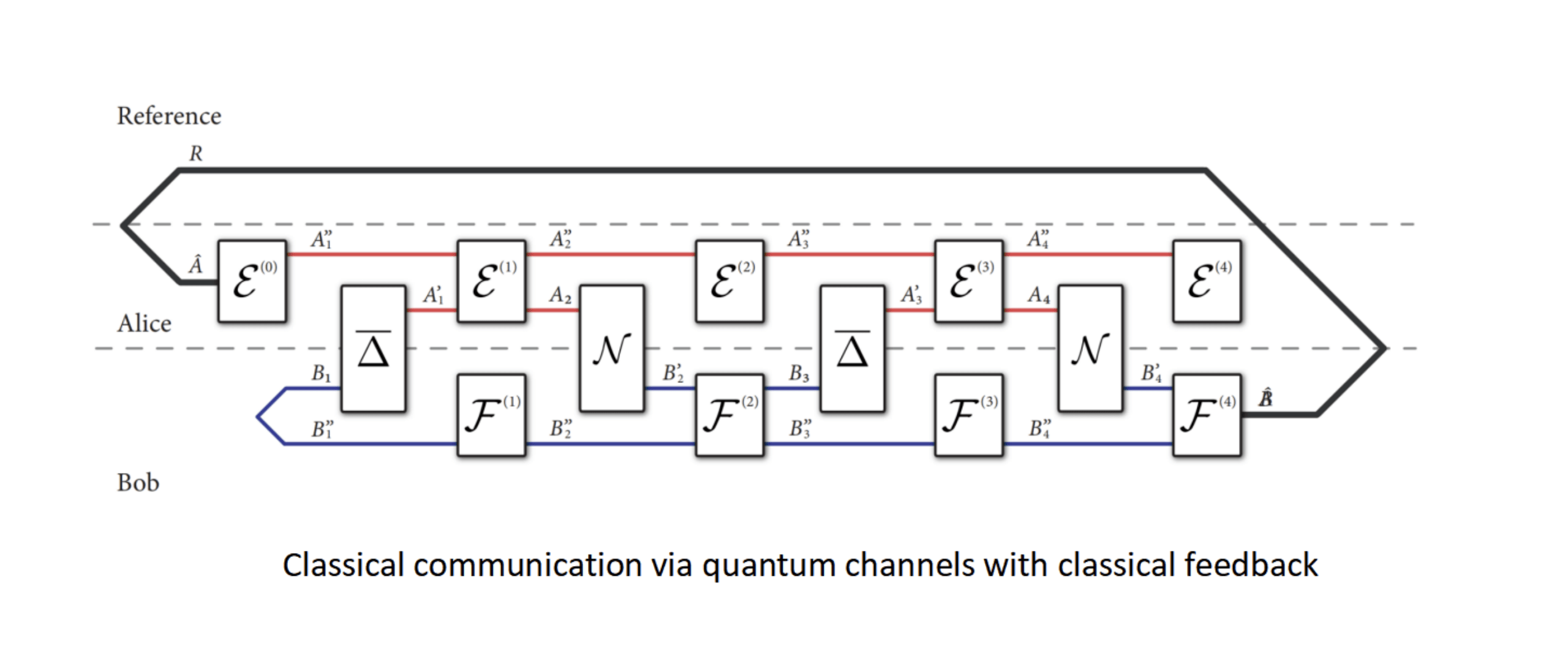
文章图片
推荐阅读







- 网络|天津联通全力助推天津市入选全国首批千兆城市
- Insight|太卷了!太不容易了!
- Baidu|百度抢跑元宇宙 却默认“输给”字节?
- 解决方案|蓝思科技:两智能制造项目入选工信部示范工厂揭榜单位和优秀解决方案榜单
- 网友|重磅!2021年度『量化』关键词揭榜
- Tencent|继百度网盘后腾讯微云也已解除限速 不用单独下载App
- 词条|百度百科上线2500万词条,超750万用户参与共创科普知识内容
- Baidu|百度网盘青春版正式上线 只能传3次文件被吐槽是“一次性App”
- 青春|百度网盘青春版正式上线:免费空间 10GB,支持无差别速率下载
- Create|什么是元宇宙游戏?百度《希壤》成国内第一个吃螃蟹的人