机器之心专栏
作者:常清
中国科学院自动化研究所智能感知与计算研究中心联合华为等企业提出面向行业的视觉物体检测一站式解决方案 GAIA 。在深度学习与大数据的浪潮下 , 视觉目标检测在各个基准数据集上已经达到了优异的性能 。 中国科学院自动化研究所智能感知与计算研究中心联合华为等企业提出面向行业的视觉物体检测一站式解决方案 GAIA 。 通过 GAIA , 用户可轻松获得不同硬件环境下的可直接用于部署的目标检测模型 。 GAIA 致力于构建一种生态 , 它以目标检测为基础 , 后续将会开枝散叶扩展到更多领域 , 期望更多的学者和用户共同维护 GAIA 的迭代 , 参与到 GAIA 社区中 。 该研究的论文已被 CVPR 2021接收 。

文章图片
论文地址:
https://arxiv.org/pdf/2106.11346.pdf
开源框架:
https://github.com/GAIA-vision
GAIA 应时而生
目标检测是识别图片中有哪些物体以及物体的位置(坐标位置)的技术 , 是计算机视觉应用的基础 , 比如实例分割、人体关键点提取、人脸识别等 。 在互联网、大数据、人工智能等技术的发展浪潮下 , 目标检测展现出巨大的应用价值 , 受到工业界、学术界的密切关注 。 各类研究机构争相构建并对外公开 COCO、OpenImage 等大规模数据集用于目标检测模型训练 。 数据集的日益丰富极大促进了技术的更新迭代 , 不断涌现出以 Faster R-CNN 为脉络发展的 Two-stage 和以 YOLO、SSD 为基础的 One-stage 目标检测新范式 。
目标检测技术在产业应用中的需求越来越广泛和深入 , 学术界已经训练好的模型评估都是基于标准 benchmark , 在产业化应用落地中通常表现出严重的 “水土不服” , 需要重新定制化开发 。 快速设计出最适合工业界不同业务场景的目标检测模型是一项很有挑战的工作 , 需要决定制化需求开发中的核心痛点问题:
一、数据整合难 。 数据治理是建模的基本要素 , 在 AI 应用开发过程中 , 从数据的采集、清洗和转换到最终生成算法所需的数据集需要经历繁琐的流程和花费高昂的成本 , 而且很有可能因为数据的准确性、完整性、有效性等问题 , 无法发挥模型优势 。
二、模型优化难 。 模型需有冗繁调参、预训练过程才能发挥其性能 。 很多终端用户由于没有足够相关专业领域知识 , 无法从纷繁复杂的模型及数据中选取最优资源 。 对个人用户来说 , 计算资源不足导致训练耗时过长 , 使得算法调优更是雪上加霜 。
三、资源共享难 。 不同用户可能有类似的需求 , 但是他们都需要分别进行一系列从数据到模型的重复开发 , 模型迁移难度大 , 而且资源浪费严重 。
四、模型定制难 。 针对不同的下游任务 , 往往需求千差万别 , 数据各式各样 , 算力各有不同 , 现在方法往往需要针对不同下游任务进行人工定制 , 费时费力 。
为此提出了面向行业的视觉物体检测一站式解决方案:视觉目标检测大模型 GAIA(相关人员包括:张兆翔研究员、彭君然博士、卜兴源、常清等) 。 该平台适应移动终端、个人电脑、大型服务器等任意场景 , 终端用户只需要在 GAIA 配置文件中设置检测的类别 , 输入简单的几行命令 , GAIA 迅速响应 , 自主学习数据集选择、模型选择和超参数优化等过程 , 用户可以轻松、快速获得任意下游数据、任意耗时要求的自适应解决方案(图 1) 。
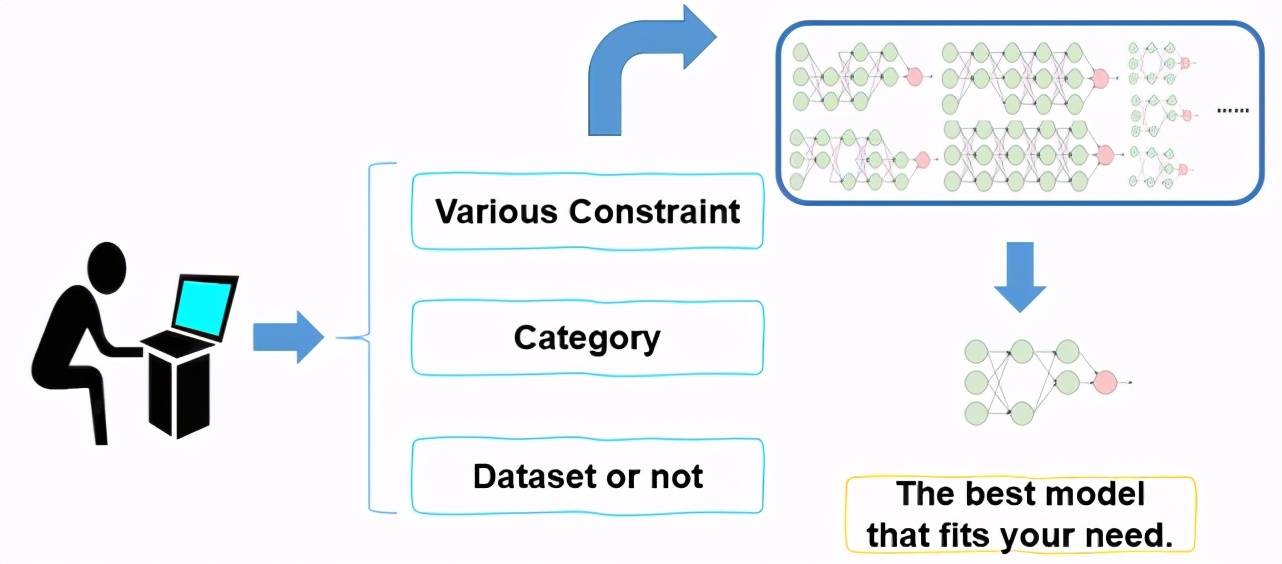
文章图片
图 1. GAIA - 面向行业的视觉物体检测一站式解决方案
GAIA 详解
视觉目标检测大模型 GAIA 作为面向行业打造的下一代一站式目标检测新方案 , 包含上游数据集、全模型训练、稀疏数据下数据选取和部署模型提取四个模块 。
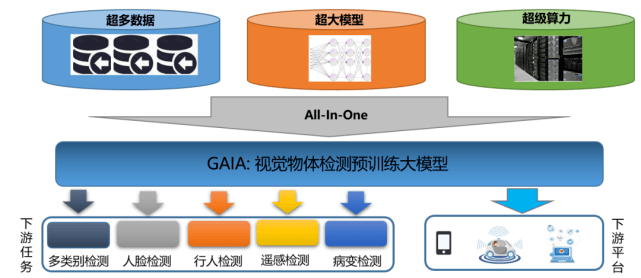
文章图片
图 2. 视觉目标检测大模型 GAIA 技术框架
上游数据集赋能
各类研究机构为不同的研究任务构建了各类目标检测公开数据集 , 如 COCO、Object365、Open Images、Caltech、CityPersons、UODB 等都是主流的目标检测数据集 。 学术界往往都是在上述标准数据集下进行检测任务的训练和测试 , 但是对产业界来讲 , 如何从已有的数据集中选取适合应用场景的子集却是举步维艰 。
借鉴大规模预训练模型 BERT、GPT-3 等在自然语言处理领域中的成功 , GAIA 将该范式延拓到视觉目标检测领域 , 对所有可用公开数据集整合并进行大规模预训练 , 增加模型的泛化能力和表示能力 。 由于自然语言中语料数据集本身是离散型 , 自然语言处理中的大规模预训练很容易构建无监督训练任务 。 但是这种方法迁移至计算机视觉领域就会遇到很多瓶颈 , 不同数据集的类别标签很容易出现歧义 , 比如像 earth、ground 可能在不同的数据集中都表示地面 , 或不同数据集类别标签之间存在包含关系 , 像绿植和树 。 GAIA 通过语义模型对类别建立语义相似度 , 将不同数据集中类别语义相似度大于阈值的归为同一类别 , 从而梳理出最终的类别和 ID 的映射关系 。
全模型训练
神经网络架构搜索算法 OFA、BigNAS 等在训练超网时 , 对其中的子网同时训练 , 这样只需花费很小的代价就可得到不需要微调就性能优异的子网络 。 与 BERT、GPT 等预训练大模型相比 , GAIA 不同之处在于将 NAS 与大规模预训练进行结合 , 提供涵盖各种 latency 下的高性能预训练网络 。 设计良好的子网采样空间对网络的训练至关重要 , 在我们进行探索的过程中发现网络深度和输入图像分辨率是影响模型性能的核心因素 , 网络宽度是模型运行占用显存的关键因素(图 3) 。 因此 GAIA 的采样空间从网络深度、输入分辨率、网络宽度三个维度出发 , 根据已有的经典网络模型设置锚点 , 在锚点周围空间从三个维度进行子网抽取 , 让整个模型训练过程更加有效 。
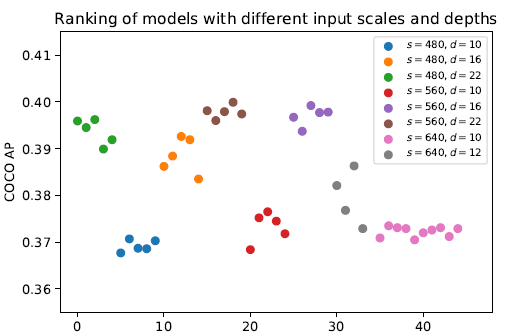
文章图片
图 3. 模型性能分析
特定下游任务数据选取
用户在本地下游任务中 , 能提供的有标签数据十分有限 , 已有的开源数据集虽然包含的数据类别十分丰富 , 数量也十分庞大 , 但是相同类别的数据存在域间差异 , 比如漫画图片中的鸟和自然场景中的鸟存在很大差异 , 直接通过类别使用开源数据集 , 只会对用户本地下游任务产生不利的影响 , 选取合适数据集 , 帮助下游任务是一项不小的挑战 。
如果终端用户提供的有标签数据数量没有达到预先设定好的阈值 , GAIA 会直接根据该使用的语义模型找到本地类别中语义信息最近似的类别 , 在该类别的上游数据集上通过模型映射向量的相似度找到域间差异最小的一部分图片(如图 5) , 并对提取模型快速训练 。 通过该功能 , 即使用户只能够提供几张图片的数据场景下 , GAIA 同样可以提供十分出色的模型 。

文章图片
图 5. 特定任务数据选取
下游模型选择
GAIA 已经测好所包含各种子网的 FLPOPS TABLE , 以及多种硬件平台下的 LATENCY TABLE(图 6) 。 对于初级使用者而言 , 只需要在本地提供 FLPOPS、LATENCY 和硬件平台 , 就可以获得满足这些约束的性能最佳的子网 。 对于经验丰富的使用者 , 可通过 GAIA 提供的接口 , 自定义添加其他约束条件 , 轻松获取性能优异的定制化子网模型
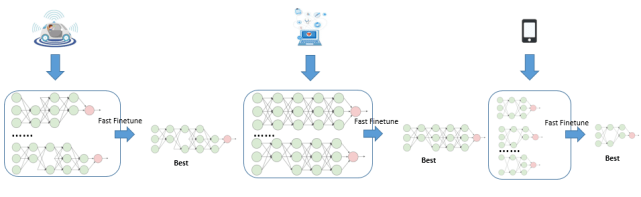
文章图片
图 6. 下游模型结构选取
优越性能
GAIA 的强大之处最直接体现在可以满足用户给出的任意时延或任意下游数据 , 快速定制可部署检测模型 , 以 COCO 数据集为例 , GAIA-det 可以快速提供时延 16~53ms、AP 38.2~46.2 的模型 。 用户不需要再花费很大的精力从数据到模型重新开发 。
GAIA 已经在 VOC、Object365、OpenImages、Caltech、KITTI 等 15 个目标检测常用公开数据集上通过测试(图 7) , 发现 GAIA 提供的模型可以很好的满足终端用户的定制需求 。
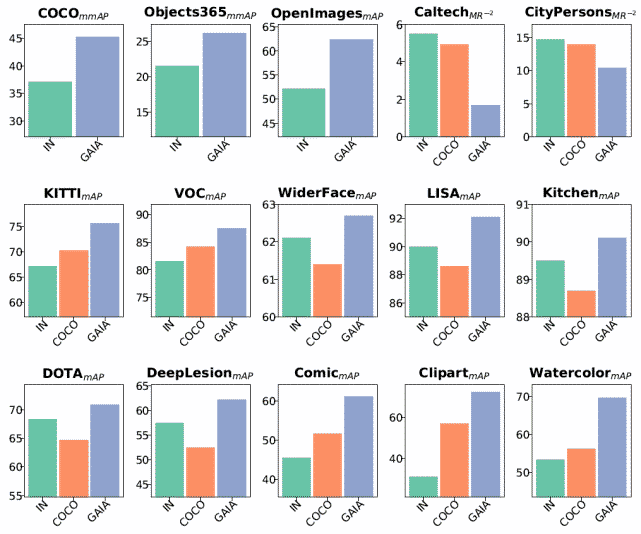
文章图片
图 7. GAIA 在目标检测常用数据集的性能对比
未来展望
视觉目标检测大模型 GAIA 是面向行业的视觉物体检测一站式解决方案 , 随着应用场景的日益丰富和理论技术的突破 , 不断更新的上游数据集会定期汇聚到 GAIA , 新的训练模型和网络架构都会通过测试验证后迭代至 GAIA , 确保 GAIA 一直为终端用户提供最优质的行业解决方案 。 现阶段 , GAIA-det 已在 Github 上开源 , GAIA-seg、GAIA-ssl 接近完成 , 即将推出 , 致力于解决更多领域的问题 。。 GAIA 是我们大家共同的 GAIA , GAIA 需要大家的宝贵意见和建议 , 期望更多的学者和用户共同维护 GAIA 的迭代 , 参与到 GAIA 生态建设中 , 一起让 GAIA 成长得更快更好 。
参考文献:
【物体|视觉目标检测大模型GAIA:面向行业的视觉物体检测一站式解决方案】Xingyuan Bu*, Junran Peng*, Junjie Yan, Tieniu Tan, Zhaoxiang Zhang?, GAIA: A Transfer Learning System of Object Detection that Fits Your Needs, IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Online (Nashville, United States), June 19-25, 2021
推荐阅读







- 视觉|超高色准打破行业天花板,创维S82还原真实世界
- 曾学忠|光弘科技 2000 万台小米智能手机下线,明年目标 4000 万台
- 曾学忠|小米手机部总裁曾学忠:希望明年与光弘科技完成智能手机4000万台目标 将引入高端和旗舰项目提升合作规模
- 能源|新思科技葛群:以科技重塑能源格局,助力双碳目标实现
- 车路|首份聚焦AI助力“双碳”目标报告发布:到2030年将推动交通减碳7000万吨
- 苹果|苹果目标达成,Apple Music中的9000万首歌曲已全部达到无损标准
- 识别率|一群年轻人教“AI”学手语,目标是让千万聋人被“听见”
- 产业|绿色和平强调,数字基础设施需加速转型以助力实现碳中和目标
- 具体目标|《“十四五”智能制造发展规划》发布
- 视觉|下瓦房“钻石壹号”品牌区 ——全新升级 耀世登场