架构|综合LSTM、transformer优势,DeepMind强化学习智能体提高数据效率( 二 )
CoBERL 架构
在自然语言处理和计算机视觉任务当中 , transformer 在连接长范围数据依赖性方面非常有效 , 但在 RL 设置中 , transformer 难以训练并且容易过拟合 。 相反 , LSTM 在 RL 中已经被证明非常有用 。 尽管 LSTM 不能很好地捕获长范围的依赖关系 , 但却可以高效地捕获短范围的依赖关系 。
该研究提出了一个简单但强大的架构改变:在 GTrXL 顶部添加了一个 LSTM 层 , 同时在 LSTM 和 GTrXL 之间有一个额外的门控残差连接 , 由 GTrXL 的输入进行调制 。 此外 , 该架构还有一个包含从 transformer 输入到 LSTM 输出的跳跃连接 。 更具体地说 , Y_t 在时间 t 时编码器网络的输出 , 可以用下列方程定义附加模块:
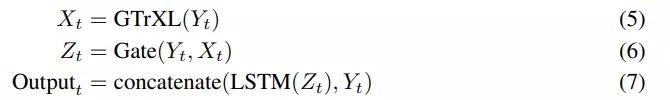
文章图片
这些模块是互补的 , 因为 transformer 没有最近偏差 , 而 LSTM 的偏差可以表示最近的输入——等式 6 中的 Gate 允许编码器表征和 transformer 输出混合 。 这种内存架构与 RL 机制的选择无关 , 研究者在开启和关闭策略(on and off-policy)设置中评估了这种架构 。 对于 on-policy 设置 , 该研究使用 V-MPO 作为 RL 算法 。 V-MPO 使用目标分布进行策略更新 , 并在 KL 约束下将参数部分移向该目标 。 对于 off-policy 设置 , 研究者使用 R2D2 。
R2D2 智能体:R2D2(Recurrent Replay Distributed DQN) 演示了如何调整 replay 和 RL 学习目标 , 以适用于具有循环架构的智能体 。 鉴于其在 Atari-57 和 DMLab-30 上的竞争性能 , 研究者在 R2D2 的背景下实现了 CoBERL 架构 。 他们用门控 transformer 和 LSTM 组合有效地替换了 LSTM , 并添加了对比表示学习损失 。 因此 , 通过 R2D2 , 以及分布式经验收集的益处 , 将循环智能体状态存储在 replay buffer 中 , 并在训练期间「烧入」(burning in)具有 replay 序列展开网络的一部分 。
V-MPO 智能体:鉴于 V-MPO 在 DMLab-30 上的强大性能 , 特别是与作为 CoBERL 关键组件的 GTrXL 架构相结合 , 该研究使用 V-MPO 和 DMLab30 来演示 CoBERL 与 on-policy 算法的使用 。 V-MPO 是一种基于最大后验概率策略优化(MPO)的 on-policy 自适应算法 。 为了避免策略梯度方法中经常出现的高方差 , V-MPO 使用目标分布进行策略更新 , 受基于样本的 KL 约束 , 计算梯度将参数部分移向目标 , 这样也同样受 KL 约束 。 与 MPO 不同 , V-MPO 使用可学习的状态 - 价值函数 V(s) 而不是状态 - 动作价值函数 。
实验细节
研究者证明了 1) CoBERL 在更为广泛的环境和任务中能够提高性能 , 2)最大化性能还需要所有组件 。 实验展示了 CoBERL 在 Atari57 、DeepMind Control Suite 和 DMLab-30 中的性能 。
下表 1 为目前可获得的不同智能体的结果 。 由结果可得 , CoBERL 在大多数游戏中的表现高于人类平均水平 , 并且显著高于同类算法平均性能 。 R2D2-GTrXL 的中值(median)略优于 CoBERL , 表明 R2D2-GTrXL 确实是 Atari 上的强大变体 。 研究者还观察到在检查「25th Pct 以及 5th Pct」时, CoBERL 的性能和其他算法的差异更大 ,这表明 CoBERL 提高了数据效率 。
推荐阅读







- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- Tencent|原生版微信上架统信UOS应用商店:适配X86、ARM、LoongArch架构
- 飞腾|原生版微信登陆统信UOS应用商店,已适配X86/ARM/LoongArch架构
- 趋势|[转]从“智能湖仓”升级看数据平台架构未来方向
- 架构|ROG 预热新款魔霸游戏本,依旧采用大下巴设计
- 综合|千村万乡驭风:国家电投上海能科小(微)风机破局分散式风电
- 综合|佳都科技:获“CPSE安博会头部企业”等5项大奖
- 技术|2025年数字商业的AI综合渗透率约至30%,影谱科技位列数字商业内容首位
- 监测|我国再添一枚资源监测利器
- 综合|自贡室外巡逻机器人