【大数据|白杨数说 | 用SPSS清洗数据之数据处理(一)】SPSS作为一款在市场研究、医学统计、政府和企业的数据分析应用中久享盛名的统计分析工具 , 大家对于它最熟悉的名字便是SPSS(Statistical Product and Service Solutions) , “统计产品与服务解决方案” , 不过 , 最初软件全称为“社会科学统计软件包”(Solutions Statistical Package for the Social Sciences) , 但是随着SPSS产品服务领域的扩大和服务深度的增加 , SPSS公司于2000年正式更改了软件的英文全称 , 而这也标志着SPSS的战略方向正在做出重大调整 。
凭借自身强大的数据兼容和拓展便利功能 , SPSS在数据分析领域有着不可替代的地位 , 其功能涵盖了数据分析的主要操作流程 , 不仅包括数据获取、数据处理、数据分析、数据展示等数据分析的操作 , SPSS还涵盖了各种统计方法和模型 , 从简单的描述性统计分析方法到复杂的多因素统计分析方法都可以在SPSS上得到实现 。
在今天的白杨数说中 , 小白杨就和大家一起来探索SPSS这一款功能强大的软件 , 实现数据处理的初步工作!
01
SPSS主界面概览
SPSS主界面主要有两个 , 一个是SPSS数据编辑窗口 , 另一个是SPSS输出窗口 。 数据编辑窗口由标题栏、菜单栏、工具栏、编辑栏、变量名栏、内容区、窗口切换标签页和状态栏组成 。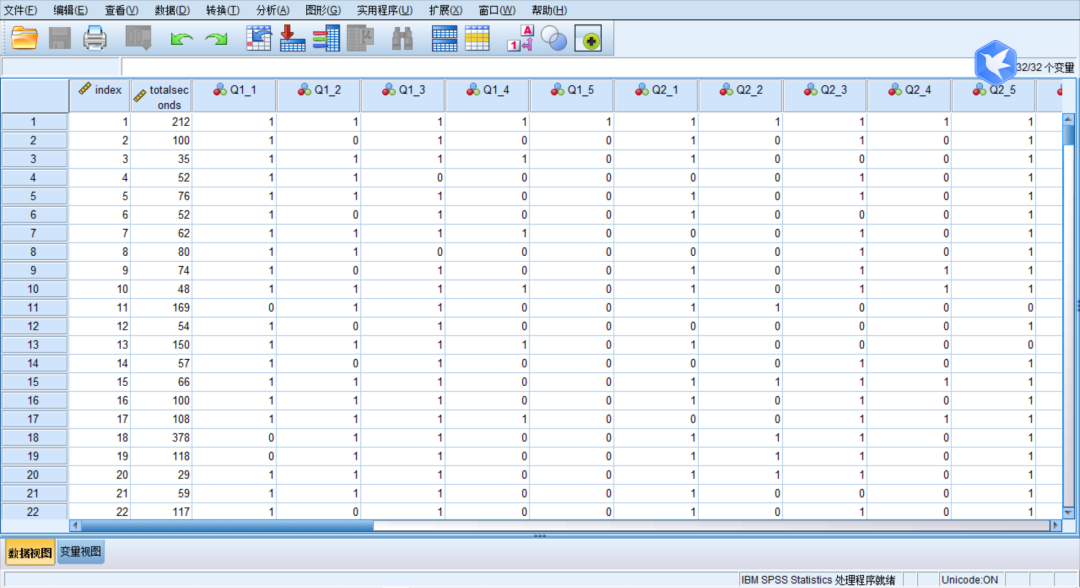
本文图片
SPSS主页面
该窗口下方有两个标签:“Data View”(数据视图)和“Variable View”(变量视图) 。 其中 ,“Data View”视图与Microsoft Excel所对应表格许多功能基本相同 , 不过仍然存在以下四方面区别 。
(1) 一个列对应一个变量 , 即每一列代表一个变量(Variable)或一个被观测量的特征 。 例如问卷上的每一项就是一个变量 。
(2) 行是观测 , 即每一行代表一个个体、一个观测、一个样品 , 在SPSS中称为事件(Case) 。 例如 , 问卷上的每一个人就是一个观测 。
(3)单元包含值 , 即每个单元包括一个观测中的单个变量值 。 单元(Cell)是观测和变量的交叉 。
(4)数据文件是一张长方形的二维表 。 数据文件的范围是由观测和变量的数目决定的 。 可以在任一单元中输入数据 。 如果在定义好的数据文件边界以外键入数据 , SPSS将数据长方形延长到可包括那个单元和文件边界之间的任何行和列 。
SPSS结果输出窗口名为Viewer , 它是显示和管理SPSS统计分析结果、报表及图形的窗口 。 读者可以将此窗口中的内容以结果文件.spo的形式保存 。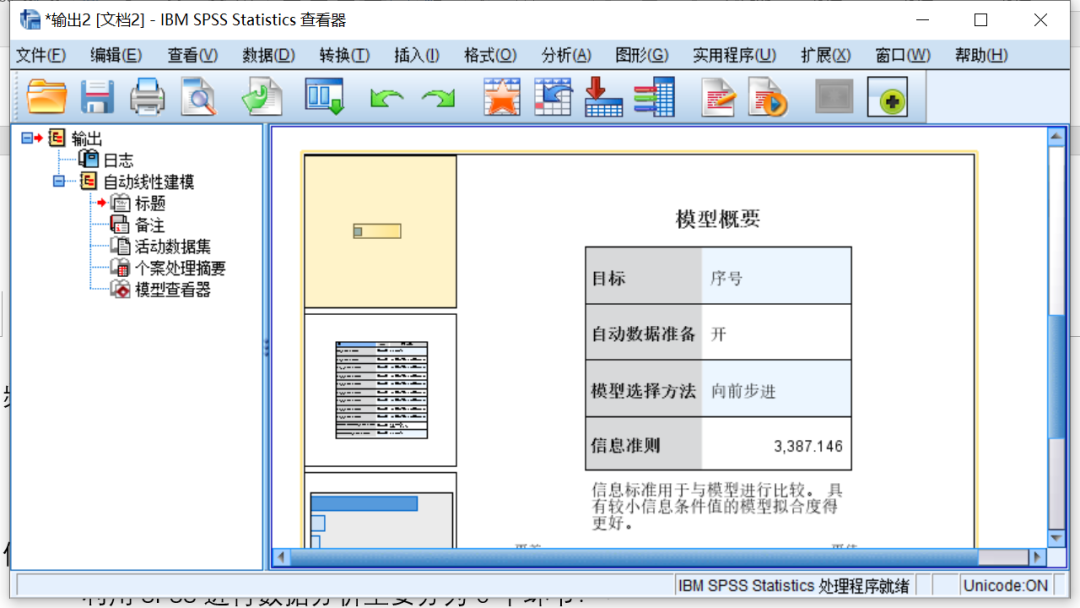
本文图片
SPSS输出窗口
结果输出部分分成左右两个部分 , 左边部分是索引输出区 , 用于显示已有的分析结果标题和内容索引;右边部分是各个分析的具体结果 , 称为详解输出区 。 这和Word的文档结构视图十分类似 。 输出区是详解输出区的一个视图 , 以简洁的方式反映出详解输出区中各个内容项 , 便于用户查找操作结果 。 可以对详解输出区中的表格进行编辑等操作 。
02
数据导入
在SPSS中常用的数据类型主要有EXCEL数据文件和TXT两种 , 其中EXCEL格式使用频率更高 , 其导入步骤如下:
文件——打开——数据——打开数据——选择EXCEL数据文件;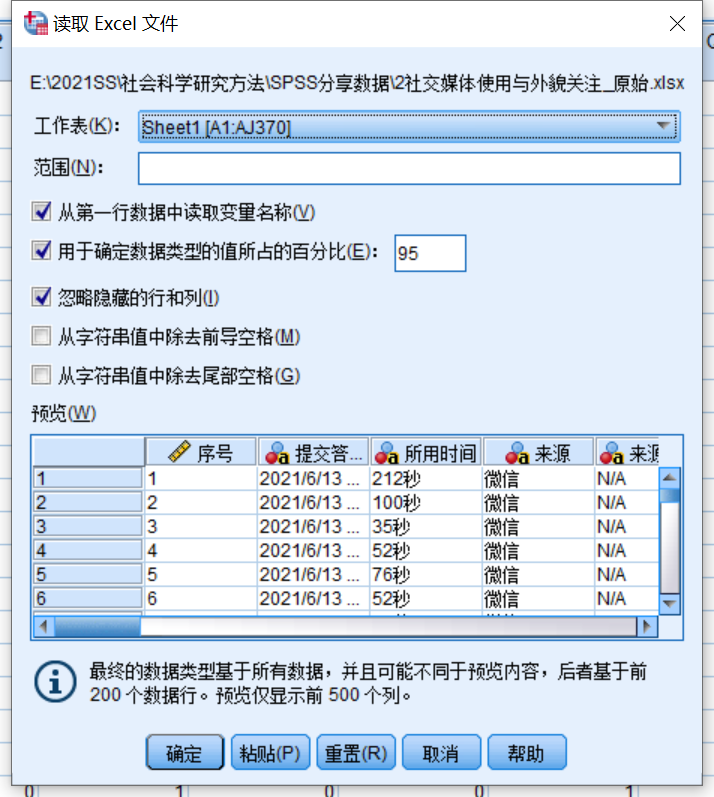
本文图片
导入EXCEL文件
SPSS 会根据实际情况设置好相关参数 , 我们只需确认参数是否设置正确即可 , 不正确则修改相应参数设置 , 确认无误后 , 点击确定按钮 。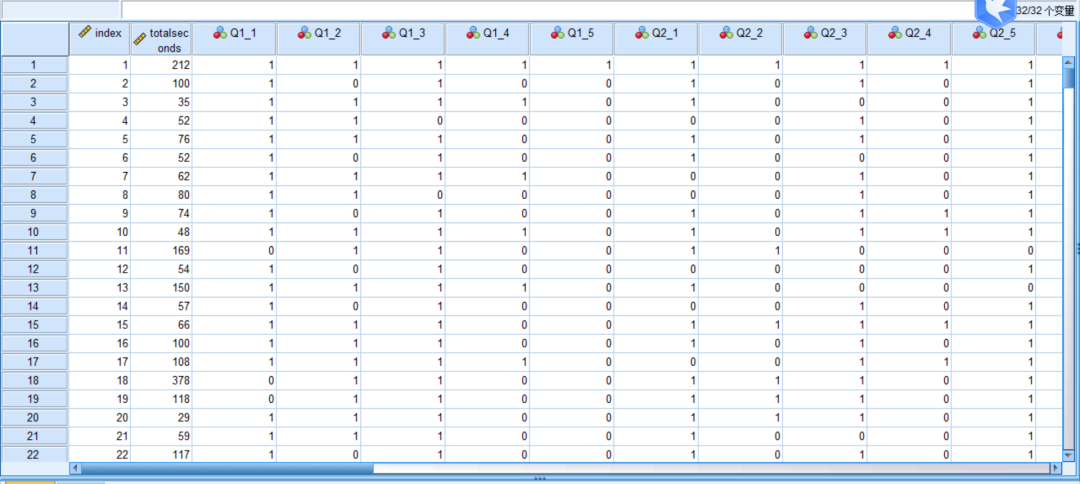
本文图片
EXCEL文件导入后界面
完成导入后 , 即可在数据视图中看到原始数据啦!
对于txt 文本导入其实和EXCEL数据文件导入的方式是类似的:
文件——打开——数据——打开数据——选择文本数据 , 更改文件类型——打开;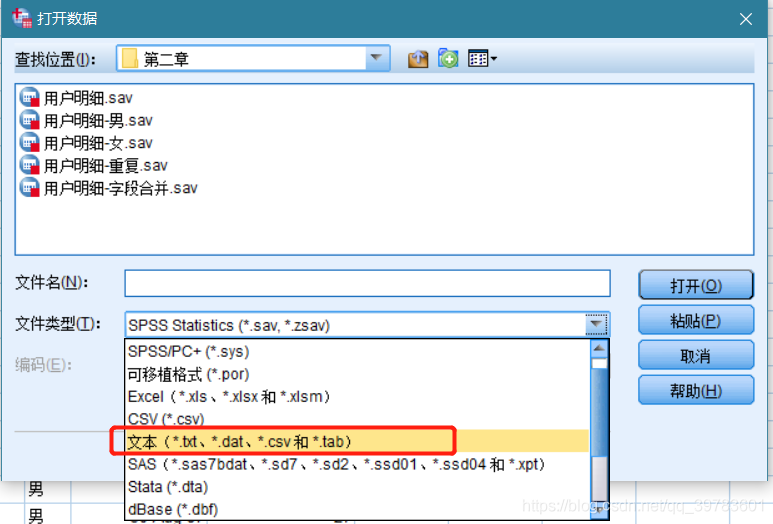
本文图片
TXT数据文件导入
需要注意的是 , 如果在导入文本文件时显示在第一步就显示乱码则多是由于编码格式没有选对 , 这时选择本地编码即可 。
03
数据清洗
数据清洗包括将重复的数据筛选清除 , 将损失的数据补充完整 , 将错误的数据纠正或删除等步骤 , 在Excel中有删除重复项是的功能 , 可以直接删除重复的数据记录 , 而SPSS没有提供类似于Excel删除重复项的功能 , 但我们可以分步操作:
1.先将重复记录找出并标记;
2.根据是否重复标记排序 , 将重复记录排在一起;
3.删除
具体操作过程如下:
首先 , 打开sav数据文件——数据——标识重复个案;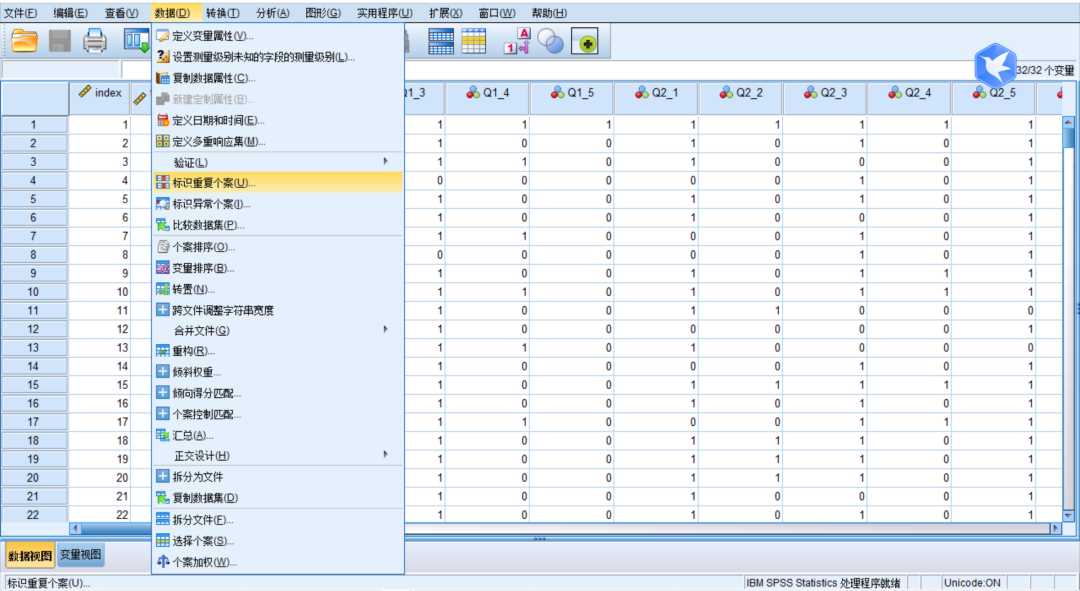
本文图片
标识重复个案
这时就生成一个重复数据记录标识变量“最后一个基本个案” , 0代表重复个案 , 1代表唯一或基本主个案;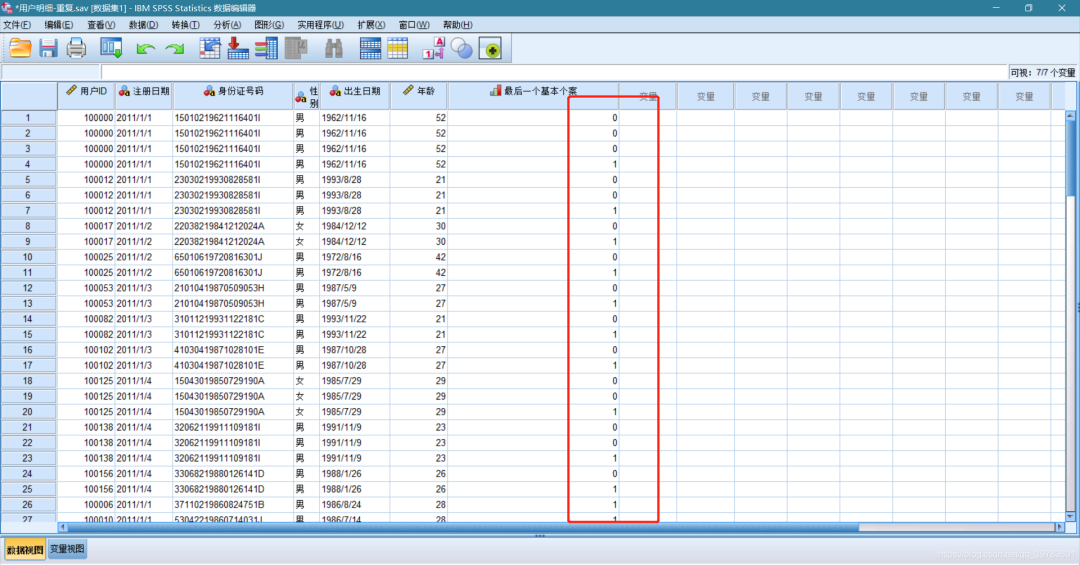
本文图片
整理后视图
选中“最后一个基本个案”变量——右键选择升序排列项——将“最后一个基本个案”变量值为0(重复)的个案都排在前面 , 这时在进行批量清除即可 。
批量清除
利用SPSS进行数据分析主要分为6个环节:
1.数据导入
2.数据清洗
3.数据抽取
4.数据合并
5.数据分组
6.数据标准化
今天我们共同学习了数据的导入与清洗 , 在下一次的白杨数说中 , 小白杨将与大家分享数据的抽取合并、分组以及标准化的操作步骤~
资料参考:
1《SPSS张文彤初级教程》
https://www.bilibili.com/video/av28448236/
2 CSDN博主三十二画生JH的原创文章https://blog.csdn.net/weixin_41847555/article/details/106774849
3 CSDN博主糖潮丽子的原创文章
https://blog.csdn.net/qq_39783601/article/details/107077940
4 CSDN博主炒冷饭的原创文章
https://blog.csdn.net/qq_40742223/article/details/105607335
推荐阅读







- 技术|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- 区块|面向2030:影响数据存储产业的十大应用(下):新兴应用
- 重大进展|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- 市场|激斗智能家居,大厂遇到新对手
- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- 最新消息|世界单体容量最大漂浮式光伏电站在德州并网发电
- 四平|智慧城市“奥斯卡”揭晓!祝贺柯桥客户荣获2021世界智慧城市治理大奖
- 项目|常德市二中2021青少年科技创新大赛再获佳绩
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖