在计算机视觉领域 , 手势识别是机器读懂人类手势、高效实现人机交互的重要方式 , 广泛应用于物联网、文娱、智能汽车等领域 。
那么 , 0基础的小白、AI开发者们 , 如何快速搭建和部署一个高精度的手势识别系统?
近期 , 英伟达x量子位发起了系列CV公开课 , 在第三期课程中 , NVIDIA开发者社区的老师通过代码演示、分享了如何利用TLT 3.0、Triton等工具低门槛、快速搭建和部署手势识别系统 。
分享大纲如下:
· 手势识别任务介绍
· 工具介绍:NVIDIA TLT 3.0 & Triton
· 实战演示:利用TLT和Triton快速搭建和部署手势识别系统以下为分享内容整理:
【部署|NVIDIA专家代码实战演示,带你高效搭建部署手势识别系统】大家好 , 我是来自NVIDIA开发者社区的何琨 , 很高兴与大家参与今天的直播 。 我主要负责与各位开发者朋友交流沟通 , 如果大家对我们的产品有什么建议、或者有哪些需求 , 也期待反馈给我们 。
手势识别任务 今天分享的内容是“快速搭建手势识别系统” , 即通过搭建和部署AI模型、对人物的手势动作进行识别 。
今天我将通过这个案例 , 向大家分享如何利用NVIDIA的工具包快速、高效率地实现AI开发 。 大家可以通过这一案例、入门AI开发 , 实现更多CV项目 。
今天的任务将会用到两个工具包:Transfer Learning Toolkit 3.0和 Triton 。
分享过程中 , 首先会为新来的朋友介绍下这两个工具 , 然后通过代码实例 , 向大家展示如何利用这两个工具 , 简单、高效地实现AI模型的训练与部署 。
课程后大家可以利用我们提供的代码、亲手操作一遍 。 (课程中所需的代码见本文末)
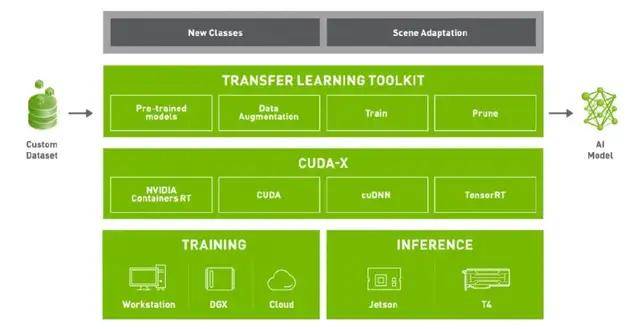
Transfer Learning Toolkit Transfer Learning Toolkit(TLT)是一个简单的、集成化的工具 , 可以帮助大家简化深度学习模型的开发流程 。 Develop like a pro with zero coding , 利用TLT不需要太多编程的内容就可以实现AI模型训练、优化与导出 。
文章图片
Transfer Learning Toolkit强调的Transfer Learning , 即迁移式学习 , 它的主要特点是为开发者提供了大量预训练模型 。 开发者可以结合自己的数据集 , 根据不同的使用场景和需求 , 在这些预训练模型的基础上进行模型训练、调整、剪枝 , 以及导出模型进行部署等 。 而且大家可以通过简单的几行代码来实现上述功能 。
TLT有几个主要的特点:
第一 , 在异构的多GPU环境下进行模型调整与重新训练 。 只通过一两个命令 , 就能够对多GPU进行合理的利用和分配 。
文章图片
第二 , 丰富的预训练模型库 。 包含大量的常见任务模型 , 在视觉、语音等方面都有很多可以实际应用的模型 。 大家可以在NGC上免费下载(ngc.nvidia.com) , 进而应用到实际的项目中 。
第三 , 优化模型 。 一方面可以利用TLT修剪、缩小模型尺寸 , 应用起来非常便捷、只需要非常简单的代码即可实现;另一方面 , 可以将模型转化成TensorRT、DeepStream、Triton等可以直接使用的深度学习推理引擎 , 可以方便的部署到几乎所有的NVIDIA产品上 。
Triton工具简介 Triton是我们今天完成课程任务需要的另一个工具 。
文章图片
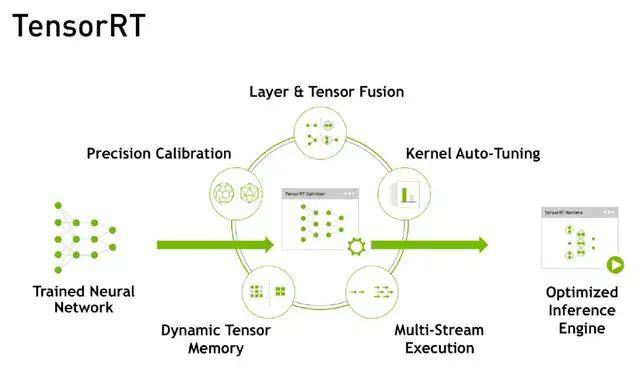
Triton的前身是TensorRT Inference Server平台 , 是一个基于TensorRT的推理服务引擎 。 TensorRT是NVIDIA专门为GPU在深度学习推理阶段的加速而开发的引擎 , 能够让GPU发挥出更强大计算能力 。
TensorRT主要通过5个步骤实现对GPU推理过程的优化:精度校正、动态Memory管理、多流的执行、Kernel参数的调优、网络层融合计算 。 通过这一系列步骤 , 在速度和吞吐量上对推理模型进行优化 。
而Triton推理服务器能够简化AI模型的大规模部署流程 , 开发者可以从本地存储或云平台的任何框架部署训练好的AI模型 , 或基于GPU、CPU的基础设施 。
Triton更像是一个即时响应的、Web Request的工具 。 它的应用场景主要是网页端、远程的数据中心 , 当然也支持嵌入式平台 。 能够大幅简化模型部署流程 , 搭建好之后只需调用其中的接口 , 不需要再操心模型的训练及优化 。
文章图片
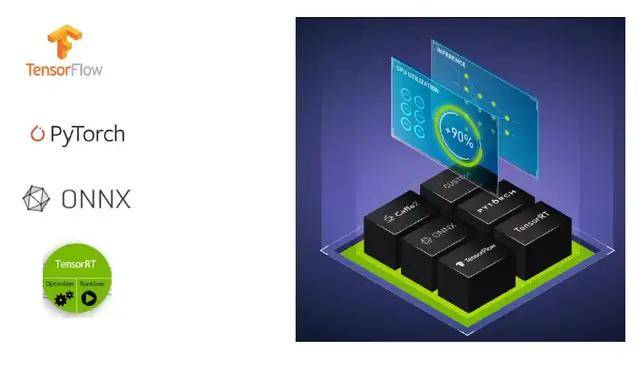
特点一:支持多种框架 。 Triton支持市面上几乎所有的框架 , 比如常见的TensorFlow、Pytorch、ONNX等 , 也支持一些自定义的框架 。
文章图片
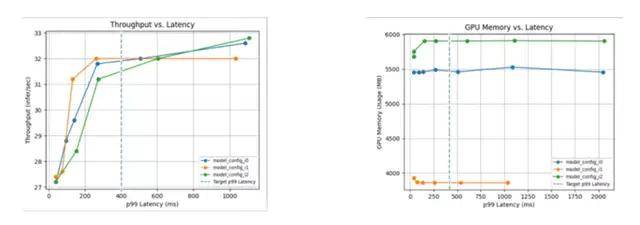
特点二:高性能的推理能力 。 Triton的推理能力不仅速度快 , 吞吐量也很高 。 可以极大加快集群的运行效率和执行效率 。
文章图片
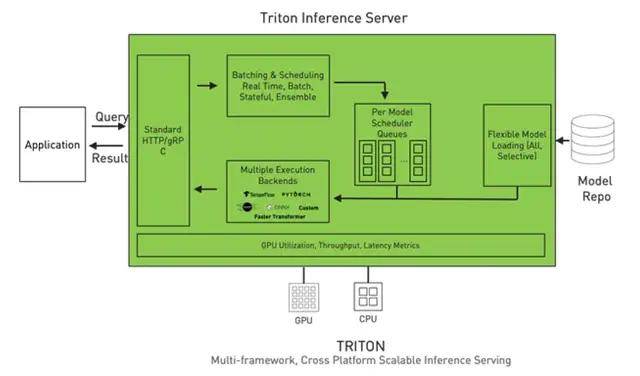
特点三:简化模型部署流程 。 上图是 Triton的架构 , 可以看到 , Triton将深度学习处理的流程封装在一起了 , 部署在我们的服务器上 。 开发者只需几步即可完成部署:
第一 , 准备模型库 。
第二 , 调用接口加载模型 。 启动Triton Inference Server时 , 模型的序列、参数、执行方案等一系列内容即可直接加载完成 。
它的优点是 , 能够将模型库和使用这个模型的流程区分开 。 对于一些项目团队来说 , 有人擅长做算法 , 有人擅长做前端 , 但只要算法工程师将模型训练好 , 前端不需要懂得如何优化模型算法 , 只需要通过Triton调用接口就可以 。
其次 , 在多线程执行时 , Triton Server也能够自动分配好GPU的内存 , 减少安全隐患、降低能耗 。
文章图片
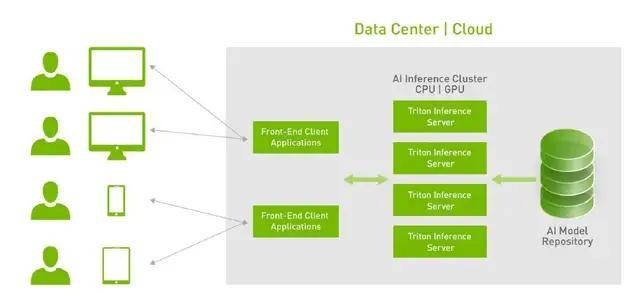
特点四:动态可扩展性 。 假设我们搭建好的两台服务器可以服务现有的10万用户 , 但是当用户量快速增加到100万时 , 我们只需要再增加几台服务器 , 直接通过Docker等方式扩展到新的服务器上 。
实战演示:搭建手势识别系统 下面 , 我们将通过一份简单的代码 , 调用TLT和Triton工具来实现手势识别模型的训练与部署 。
代码&课程PPT下载链接:https://pan.baidu.com/s/1OXyLeF7qU-bcA3UPAY2K_A
提取码: 81ik(百度网盘)
接下来 , 何琨老师通过代码讲解 , 向大家展示了如何借助TLT和Triton完成手势识别系统的训练与部署 。 大家可观看视频、继续学习:
直播回放链接:https://www.bilibili.com/video/BV1cB4y1u722/
p.s.代码演示部分从第30分钟开始~
— 完 —
推荐阅读







- 可持续性|人工智能将重塑健康管理,业内专家认为可持续性是最大挑战
- nVIDIA|英伟达有可能将于2022年1月5日凌晨发布新一代RTX显卡
- 数字货币|是继续欣欣向荣还是泡沫破灭? 专家给出加密货币2022年五大预测
- the|美国日增新冠确诊病例超44万 专家:美疫情已转向新阶段
- 第一医院|三明启动“云查房” 让基层百姓“零距离”共享专家医疗服务
- nVIDIA|NVIDIA的RTX 2060 12GB显卡被喷:贵了上千块 毫无意义
- 团队|年终策划 | 航天专家史青:为火箭“体检”给火星车装“耳朵”
- 托管|微信云托管现已支持公众号登录部署
- 时代|元宇宙时代数字安全怎么保护?专家解读
- nVIDIA|RTX 3080 Ti游戏本旗舰卡曝光:最大功耗175W