Jiangmen
作者:香港中文大学在读博士生 吴桐
ECCV 2020系列文章专题
第·19·期
本文将分享来自 香港中文大学在读博士生吴桐等人在 ECCV Spotlight的工作 。文章关注的是长尾分布下的多标签分类问题 , 并提出了一种分布平衡损失函数 (Distribution-Balanced Loss) , 在 COCO-MLT 和 VOC-MLT 这两个人工构造的多标签长尾数据集上进行实验验证 , 均取得了很好的效果 。
更多ECCV精彩内容 , 后台回复“ECCV”即可查看!

文章图片
论文地址:
https://arxiv.org/abs/2007.09654
代码链接:
https://github.com/wutong16/DistributionBalancedLoss
视频链接:
youtu.be/AoEJF-osMgM
一、背景
真实世界中的数据分布往往是不平衡的 , 少数几个头部类别(比如人、车等)拥有大量可训练样本 , 而大多数类别的样本数量十分有限 , 在统计直方图上形成长长的“尾巴” 。
然而 , 采集自真实场景的图片常常具有丰富的语义信息 , 多个物体共存是一种普遍情形 。 因此长尾分布下的多标签分类任务是这篇文章主要关注的问题 。
二、动机
从单标签向多标签的转换 , 有几个自然的思路:对前者有效的方法对后者来说是否仍适用?两种设定在训练时的主要区别有哪些 , 又有怎样的影响呢?
1. 采样难解耦
对于第一个问题 , 我们注意到重采样(re-sampling)是一个常见而有效的策略 , 在几个最新工作 [1,2,3,4] 中都作为关键组件出现 , 其中 [3,4] 提出重采样法对分类器学习有显著促进作用 。 但这种方法并不能顺滑地迁移到多标签情景中 , 因为标签的共存性(co-occurrence)将导致不同类别在采样时无法解耦 。
举个栗子 , 如果数据集中有限的几张牙刷图片样本都同时包含刷牙的人在其中 , 那么在对“牙刷”这一尾部类别进行重采样时 , 对“人”这一头部类别的采样也会只多不少 。 同时 , 注意到“刷牙的人”此时就会比“单独出现的人”具有显著更高的采样频率 , 为头部类别额外引入类内不均衡的问题 。
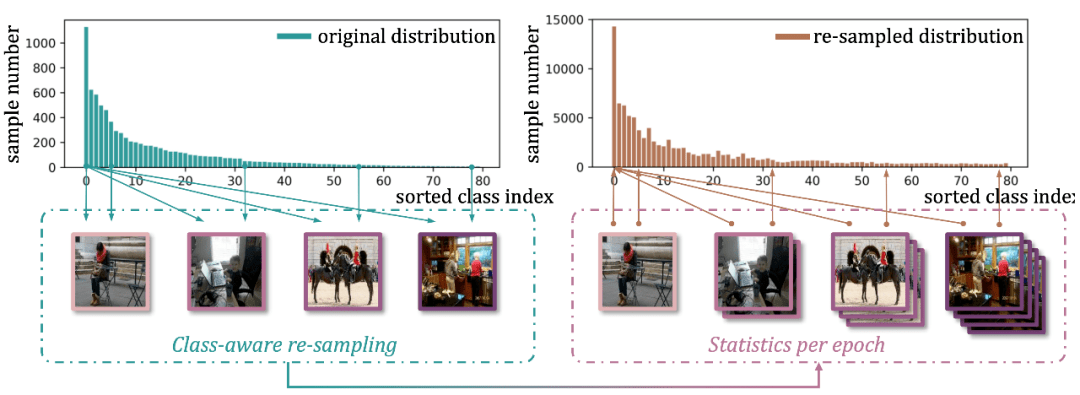
文章图片
图1 重采样过程以及采样前后分布直方图对比
2. 分类器出走
对于第二个问题 , 我们知道Cross-Entropy Loss(CE Loss)是单标签分类中常见的损失函数 , 其中 softmax 的计算强调分类器需要输出唯一最大预测值 , 同时正负类别的预测值在损失函数中存在相互影响;而多标签分类则多使用 Binary Cross-Entropy Loss(BCE Loss) , 将任务拆解为一系列相互独立的二分类问题 , 并以 sigmoid 计算每一类别的输出预测值 。
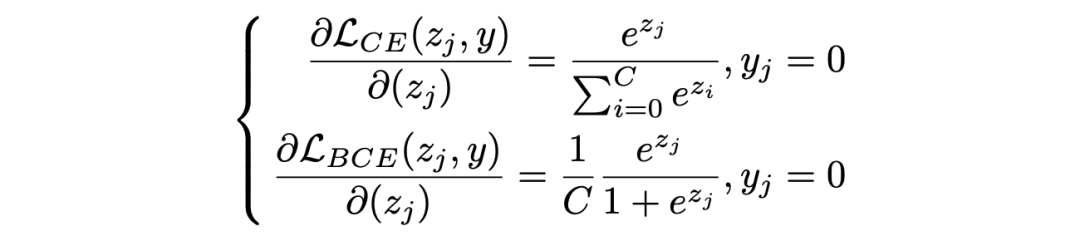
文章图片
现在我们来考虑分类器对一个负类输出值的求导 , 两种损失函数对应梯度的差别如上式所示 。 对于 CE Loss , 当同一样本中的正类输出足够高时 , 对负类输出求导的梯度值也会随之减小 , 而对 BCE Loss 来说 , 构造上的独立性导致只有不断降低负类输出值本身才能够降低自身梯度值 , 从而在训练后期该输出将稳定在一个相对更低的位置上 。
这个过程的二者的可视化对比如下图所示 。 (注意这里是损失函数的梯度函数 , 梯度值的大小影响优化速度)
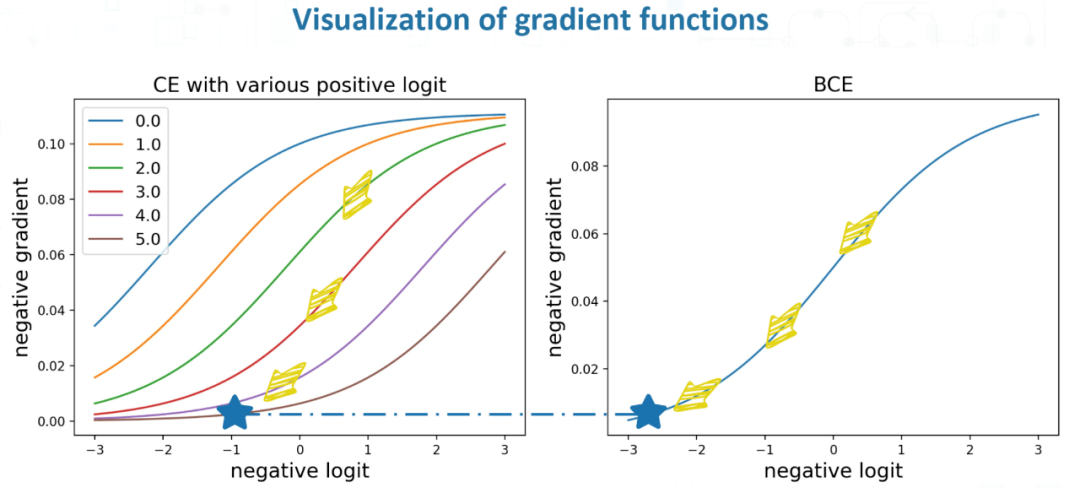
文章图片
图2 CE 和 BCE 对负类输出的梯度函数可视化
然而 , 对于一个特定类别(尤其是尾部) , 数据集中绝大多数都是它的负样本 , 当分类器被海量负样本包围 , 且被要求对每一个负样本都输出一个足够低的预测值时 , 分类器向量在训练过程中将被迫远远偏离大量自然样本的分布 , 而仅仅过拟合在它的个别正样本上 。
可以想像分类器预测值在特征向量(feature vector)空间中的分布具有一个尖锐的波峰 , 泛化性能很差 。
三、方法
针对上述问题 , 我们分别提出了 Re-balanced weighting 和 Negative-tolerant regularization两个策略 , 并最终整合为一个损失函数的形式 。
1. 理想现实有差距 , 加权弥补
现在来对采样过程做一个简单的定量分析:假设我们希望所有类别都以相同的概率被采样到 , 那么在不考虑标签共存时 , 包含类别
的样本
被采样到的概率可记作
;但该样本还可能含有其它正标签 , 每一个正标签都对它实际的采样概率有所贡献 , 后者可以计算出并记为
。
我们通过计算上述二者的比值
并以其作为加权系数加入训练 , 来弥补期待与实际采样概率之间的差距 。 特别的 , 我们还设计了一个平滑函数 , 将权重系数映射到一个合理范围内 。 权重系数的计算过程如下所示 。
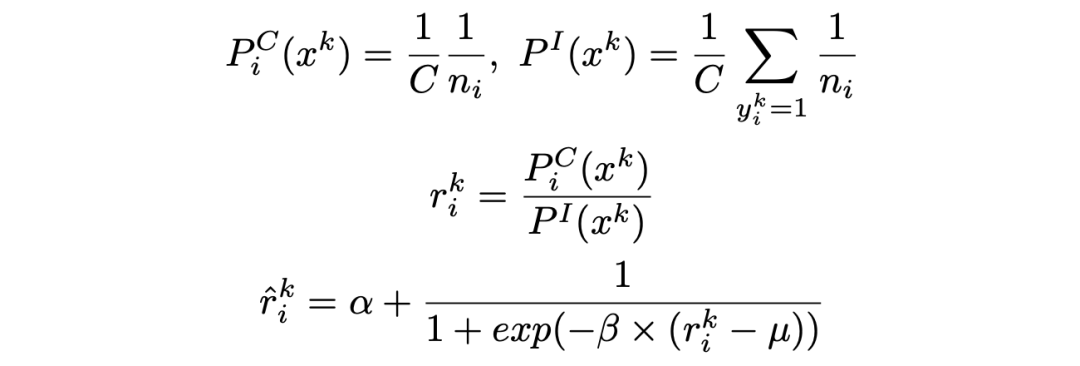
文章图片
2. 过度惩罚不可取 , 点到为止
第二个问题我们在文中称为负样本的过度抑制(over-suppression of negative labels) , 一个简单粗暴的解决思路便是 , 不要对负样本持续施加过重的惩罚 , 而是点到为止 。
我们只需要对分类器的负类输出进行一个简单的线性变换就能够实现上述功能 , 不要忘记加上正则化系数约束梯度值的范围 。 变换后函数请见后文的整体公式 , 它对负类输出的梯度与 CE 和 BCE 一同对比如下图所示 。
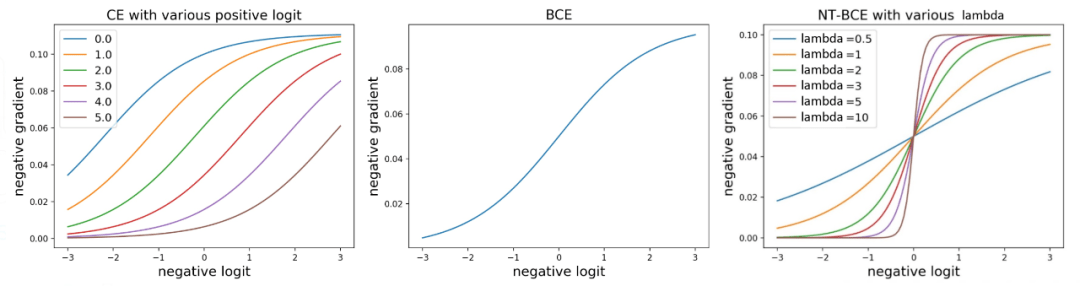
文章图片
图3 三种损失函数对负类输出的梯度函数对比
3. 权值正则两相宜 , 统一框架
最后 , 上面两个方法可以自然地融合为一个损失函数 , 并进行端到端的训练 , 下图可视化了它的构造过程 。
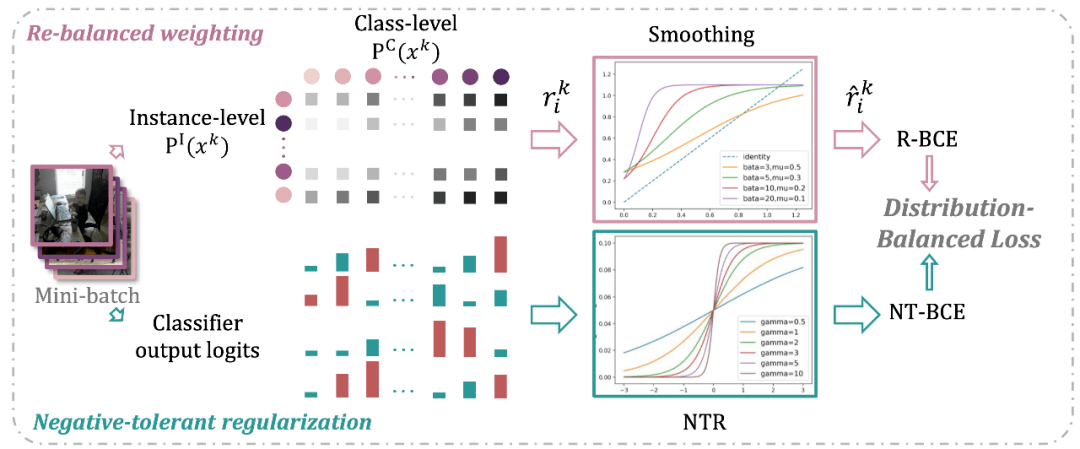
文章图片
图 4 分布平衡损失函数构造过程
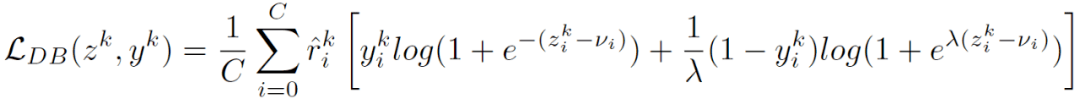
文章图片
我们来回顾一下整体计算框架:(1) 首先应用重采样法促进尾部类别分类器的学习 , 同时也对头部类别引入了一定的类内采样不均衡性;(2) 接着 , 利用重加权的方法对无法解耦的采样在权重上予以平衡;(3)最后 , 正则化方法缓解了对负类别输出的过度抑制 。
如下图所示 , 特征向量(feature vector)空间各类别预测值的分布得到了递进式的平衡 , 这也是分布平衡损失函数(Distribution-Balanced Loss)命名时的想法 。
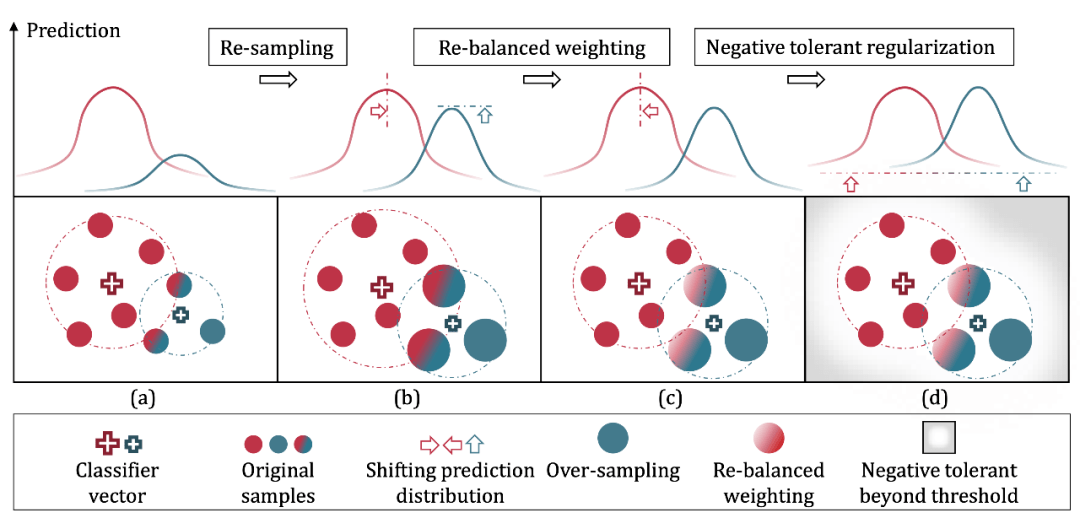
文章图片
图5 整体流程示意图
四、实验结果
我们基于 Pascal VOC 和 MS COCO 以抽取的方式人工构造了两个长尾分布的多标签数据集用以训练 , 称为 VOC-MLT 和 COCO-MLT , 并以 mAP 为主要评价指标在原始测试集上进行验证 。
我们根据每个类别含有的训练样本数量$n$将其划分为头部(head, n>100) , 中部(medium,100≥n>20)和尾部(tail, n≤20)三个子集 , 并在整体和各子集上都进行了结果对比 , 结果如下表所示 。
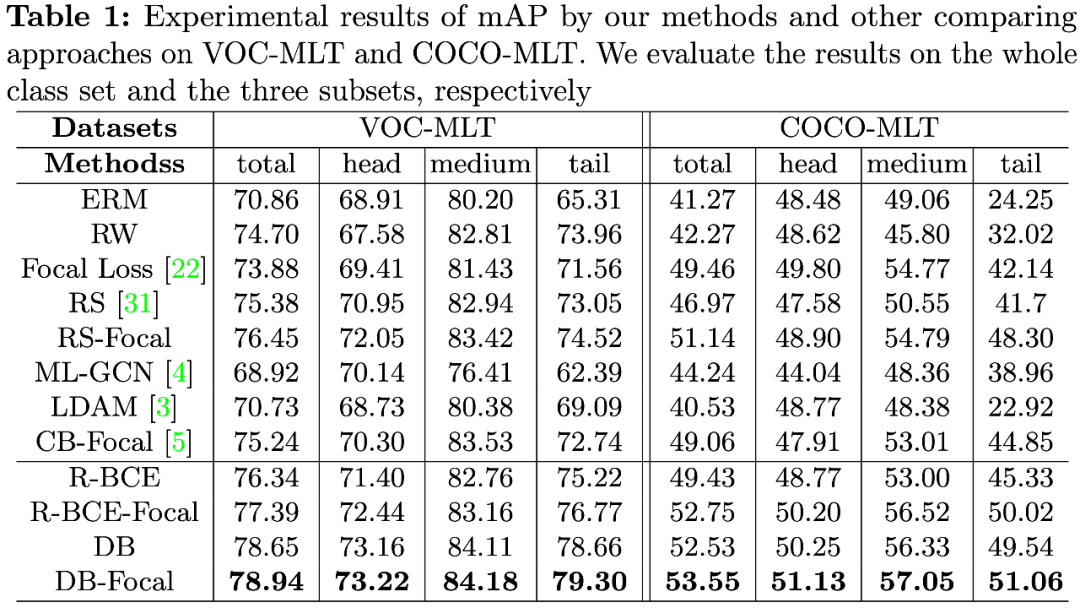
文章图片
特别的 , 我们还测试了递进实施每一步骤后 , 每一类别的指标增量(mAP increment) , 来分析每个技术对长尾分布的不同位置处类别的影响 , 具体结果以及更多的 Ablation study 可以参考原文 。
五、展望
这篇文章关注的是长尾分布下的多标签分类问题 , 并从已经较为成熟的单标签不平衡分类方法中得到启发 , 从二者的差别入手 , 提出了一个简单而有效的方法 。 深度学习发展到今天 , 学术界默认采用的单一域平衡数据集已无法反映 AI 算法的真正泛化能力 。
我们邀请大家一起来攻关这个新兴且更符合现实数据的领域 , 开放世界学习(Open World Learning) , 既包含类别分布上的复杂性 [1] , 也包含数据域分布上的复杂性 [5] 。
最后 , 欢迎大家关注我们的工作 , 提出宝贵的建议!
【采样|ECCV 2020 Spotlight | 清华&港中文提出多标签长尾识别前沿进展】//
作者介绍:
吴桐 , 香港中文大学多媒体实验室(MMLab)一年级博士生在读 , 师从林达华教授 。 她于2020年从清华大学电子系取得学士学位 。 研究兴趣包括长尾识别、对抗样本、组合学习等 , 曾在ECCV上发表两篇文章 。
参考资料
[1] Liu et al., Large-Scale Long-Tailed Recognition in an Open World, in CVPR 2019 (Oral), liuziwei7.github.io/pro
[2] Cui et al., Class-Balanced Loss Based on Effective Number of Samples, in CVPR 2019
[3] Kang et al., Decoupling Representation and Classifier for Long-Tailed Recognition, in ICLR 2020
[4] Zhou et al., BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition, in CVPR 2020 (Oral)
[5] Liu et al., Open Compound Domain Adaptation, in CVPR 2020 (Oral), liuziwei7.github.io/pro
推荐阅读




- 平板|小新 Pad Pro 2020 平板开启 OTA7 ZUI 13 灰度推送
- 国际|2020年我国产出卓越科技论文46万余篇
- 排名|2020年我国国际顶尖期刊论文数量排名世界第二 上升2位
- 最新消息|印度创企2021年获360亿美元投资 比2020年增长2倍
- 未来|汾酒荣获2020年度中国食品工业协会科学技术奖两项殊荣
- the|美国疾控中心公布2020年十大死因:心脏病排名第一 癌症第二
- the|CDC:美国人均预期寿命在2020年缩短近2年
- 疫情|中科院报告:2020年中国共出版科普图书近亿册
- 期刊|中国首部科学传播报告:2020年出版科普图书9853.6万册
- 传播|2020年中国新建科普网站2732个