本文根据赵飞祥老师在〖deeplus直播第262期〗线上分享演讲内容整理而成 , 由dbaplus社群原创首发 。

文章图片
赵飞祥
Airwallex 资深DBA
- 有多年一线传统行业和互联网数据库架构设计与运维经验 , Oracle 11g OCM , 对MySQL、Oracle、PostgreSQL、Greenplum、MongoDB等多种数据库有丰富的架构、维护经验 , 目前主要关注 PostgreSQL 数据库的架构设计和运维优化方向 。

文章图片
第一个是高可用的原理 , 我们平时都会有一些具体的高可用需求 , 也会进行一些高可用方面的建设 。 但今天我的分享 , 想要换一种思路 , 分享我们知道的很多数据库的高可用架构 , 在技术操作层面背后 , 可抽象出的一种架构 , 一种模型 , 一种原理 。 用这种原理再反过来看具体的架构 , 看现有的架构 , 乃至后续的架构演进 。
所以 , 第一部分高可用原理 , 是今天分享中比较重要的 , 后文MySQL的高可用和PostgreSQL的高可用 , 实际上都是在这种高可用原理和架构模型基础之上 , 针对每种数据库具体的、实际的、比较主流的高可用架构方式来进行阐述和说明 。
最后一个方面 , 除了自建的数据库 , 现在数据库很大一个方向是使用云 , 云上Cloud在高可用也有一些独特之处 , 我也会介绍我们公司现有的架构和后续一些发展和展望 。
一、高可用原理
文章图片
1、高可用定义
第一部分高可用的原理 。 首先 , 简单介绍什么是高可用 。 从定义上 , 高可用指服务的可用性比较高 , 它主要是指为让一个系统能够无中断的执行其功能的能力 , 是可用性的衡量指标 。
如何达到高可用?简单来讲 , 通过一个“冗余”的机制来实现 。 即使有一个或者一部分发生故障 , 还有其它冗余的服务或者组件能够继续对外提供服务 , 从而达到整个服务的高可用 。
高可用 , 是为了保证这种服务可用 , 所以 , 它主要的目标就是没有中断 。 如何实现无中断?最主要的一个本质就是通过冗余来实现 。

文章图片
如果一个服务只有一个 , 没有冗余 , 这是单点 , 它就不具备高可用 。 高可用 , 通过冗余 , 至少有两个或者是两个以上的不同节点和组件来提供一个服务 。 这实际上是实现高可用的一个本质和一个主要的特征 。
对于冗余 , 或者说高可用 , 它主要的、常见的有哪些呢?
按照一般业务架构类型来分 , 可以有业务的高可用 , 计算的高可用 , 也有存储的高可用 。
相对来说 , 业务的高可用和计算的高可用会容易一些 , 因为它们很多是无状态的 , 比如我们的业务服务可以有多个 , 且都提供相同的逻辑 , 或者我们的计算高可用有多个前端的节点 , 可以提供相同的功能 。 这时候基本上只要增加冗余 , 部署同样的业务服务或者增加可以实现同样功能的业务组件 , 就可以实现业务的高可用或者计算的高可用 。
但是对于底层数据所存在的地方 , 即存储高可用或者数据库高可用 , 相对会复杂一点 。 复杂的重要原因是数据库有状态 , 它的数据在不同的节点 , 不同的时刻 , 会有不同的事务 , 会有各种不同状态 , 它并不是有完全的两份就可以了的 。 所以 , 相对业务高可用和计算高可用 , 存储高可用会更加复杂一些 。
从业务架构来看 , 高可用最下面是存储高可用 , 存储上面有计算高可用 , 往上有业务逻辑的高可用 。 我们今天主要讨论存储高可用这个相对复杂的部分 。
2、数据库高可用三大模块
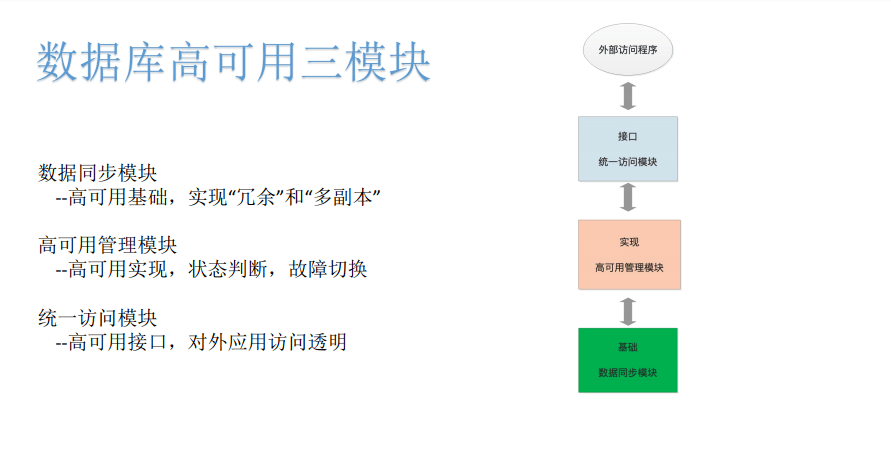
对于高可用 , 我们从原理可以抽象这种高可用模型 。 本质上存储的高可用 , 是有存储的状态的 。 从存储的状态来说 , 如果想实现整个数据库高可用或者存储高可用 , 至少需有三个模块方面的功能 。
文章图片
因为数据库有状态 , 而这种状态的同步 , 在实现冗余的时候 , 需要有数据的一个数据同步机制——同步模块 , 它不仅仅是像业务系统或者计算系统一样 , 部署两套完全相同的逻辑、相同的配置就可以 。 它内在数据在不断流转 , 不断的变化 。 所以在产生冗余或者形成数据多区域、多可用性的时候 , 我们需有数据同步模块来实现两个数据库实例 , 甚至多个数据库实例具有一致性数据状态的这样一种基础功能 。 在这个基础上 , 我们实现了主库实例在两个节点或者多个节点 , 有相同的有状态的服务功能 。 这是数据同步模块 。
在高可用模型的最上边 , 因为整个数据库的高可用 , 数据库要对业务提供连接 , 那么在数据库底层发生一些变化的时候 , 外边的业务程序 , 它最好是无感知的 , 所以需要有一个统一的访问结果或者访问模块 。
在数据同步模块和统一访问模块之间 , 对高可用的架构和高可用之间本身进行管理的话 , 需要有一个高可用管理模块 。
所以 , 从下往上 , 数据库的高可用 , 抽象来讲 , 它必须具备不同的模块来实现不同的高可用功能:
- 最底层的数据同步模块 , 是实现高可用的基础 , 实现在数据库层面 , 是有冗余和多部分的;
- 然后在高可用管理的层面 , 主要确认实现高可用的功能 , 即就是高可用本身的功能 , 包括状态判断 , 包括在正常与异常情况下的一些故障切换;
- 最上层 , 对于业务访问 , 需要有一个高可用的接口 , 统一访问模块 , 对外应用进行透明 。

文章图片
a.数据库功能
数据库同步模块 , 一般有基于数据库本身的一些功能 。 每个数据库 , 尤其关系型数据库 , 它主要是有事务 , 需要满足ACID的条件来保证数据的一致性、数据的原则性等等 。 在数据保证事务和变化的过程当中 , 很重要的一个方面是有日志系统 , 将数据库所有的变化记录到日志当中 , 日志能进行归档 。 当日志文件传输到其它的实例上面 , 可以对这些日志进行重做 , 这个是每个关系数据库基本都会提供的一些功能 , 而这个功能就是实现数据库的这种有状态的应用程序能进行同步和冗余的一个基础 。
b.同步建立
有了数据库本身的事务日志功能 , 还有日志系统和记录的日志文件 , 要如何实现这种同步或者如何建立同步呢?
第一 , 需要有全量的静态的数据 , 来做一个全量的备份兼保证有数据 。 更重要的同步是通过日志 , 即在一个节点 , 我们如果把这一个节点称为主节点 , 然后主节点提供各种各样的变化 , 变化会选择到对应的日志当中 , 然后日志进行归档 , 归档之后 , 需要把这日志传到其它的子节点上 。 这个传 , 需要有对应的主节点上面的同步用户具有获取日志的权限的 , 需要在主节点上先建立同步用户 , 然后在从节点上指定同步开始的起点 , 建立同步通道来持续获取日志 , 并在从节点持续应用日志 , 建立日志的系统关系 。 通过日志归档和同步用户建立起不同实例间的数据关系 , 可以保证增量数据的同步 。 然后在增量动态数据的同步功能的基础上 , 再和全量同步——一开始静态数据的同步结合 , 这样就可以实现数据库的高可用的搭建 。
因为数据库是有状态的 , 存在着一个节点有主节点和其它的备份节点或者从节点 , 所以会有同步数据是否一致的问题 。 同样 , 对于数据库 , 如果有多个节点 , 它一方面有一致性 , 另外一方面还有是否具可用性的问题 。
c.数据一致性与可用性权衡
对于数据一致性和主库的数据可用性 , 都需要进行权衡 , 看自身更偏重和看重哪些方面 。
例如在生产系统中 , 比较常用的方式是异步复制 , 即主库发生的所有事务变化 , 只用主库记录 。 它也可以把记录传给从库 , 但从库是否收到或者是否进行变化 , 主库并不关心 , 或者并不严格确认 , 从库对主库的日志拉取应用 , 乃至保障数据一致的这个过程对主库本身没有任何影响 , 这样可以保证主库具有最好的性能 。 而且从库本身是否出现故障或者网络是否出现故障 , 不会影响到主库 , 这也应该是大部分业务场景可以需求和满足的地方 , 所以一般异步复制会较频繁使用 。
但在一些极限情况下 , 如果主库受比较多、频繁 , 到时候发生变化了 , 但日志却还没完全传输到从库 , 这时如果发生故障 , 那么这些没有传输的日志 , 在从库中就会没来得及应用和使用 , 有可能造成一部分的数据丢失 。 所以可用性异步复制虽保障了主库数据的可用性 , 但一致性在一些极限情况下会有所牺牲 。
有些系统 , 比如说交易系统 , 它与钱相关 , 其数据一致性是非常重要的 。 比如说我在银行存了1000块钱 , 这个消息如果丢失了 , 系统查询则会显示没有存进1000块钱 , 这肯定是不可接受的 。
对于数据一致性要求高的 , 可以进行同步复制 , 即如果主库发生了所有的变化 , 我们要在从库当中来进行 , 这样在极限的情况下 , 如果主库挂掉了 , 我们可以启动从库 , 继续为主库对外提供服务 。 对于从库来讲 , 它必须保证所有的数据是一致的 。
数据同步复制也有对应的代价和选择的考量 。 在严格同步复制的场景中 , 主库进行一个操作 , 每次操作除了主库本身所需要的资源之外 , 它还需要从库来验证 , 来得到应用日志保证数据一致 。 它需要返回 , 本身才能提交 , 如果没有返回 , 它本身也会提交不了 , 这样的话 , 在网络中断或者在从库没有及时反馈时 , 主库的事务 , 就会一直等待 , 那么可用性就有所下降 。
异步复制 , 它主要保证了可用性 , 但是牺牲了极限情况下的一些数据一致性 。 而同步复制 , 它保证了完全严格的数据一致性 , 但对可用性有所牺牲 。 所以一些数据库会对两者进行权衡 。
正常情况下 , 比如说主库的日志量、事务交易量等各方面数据不太多 , 然后它所进行的变化、网络、从库都正常 , 也可以到从库去 , 我们会尽可能保证它们数据是同步的 , 严格意义上的同步 。 这样的话 , 如果发生中断 , 或者发生了延迟的情况 , 虽然一致性得不到保证 , 但我们希望主库的服务能不至于完全宕掉 。 如果我们还希望它能够用异步复制来继续保证事务的可用性 , 可以在同步和异步复制之间进行一种权衡 , 这就是半同步复制 。
所以对数据一致性和可用性是需要有一个平衡 , 需要看不同的业务场景 , 对哪一个方面更加看中 , 然后来选择对应的同步方式 。
2)数据高可用管理模块
在数据同步模块之后 , 还有高可用管理模块 , 比如我们有了主库 , 有了从库 , 然后通过数据库本身的日志事务等进行了全量备份 , 进行了日志的应用和恢复 , 通过日志事务等等数据库本身的机制 , 使两个甚至多个有数据库状态的节点 , 它们的数据保持了一致 。 那么它们进行状态变化的时候 , 需要高可用来进行管理和切换 。 实际上 , 高可用管理模块 , 就相当于在数据库之外 , 一定要有一个组件 , 或者要有一个功能来知道这些数据库每个实例的状态 , 以及它们在异常情况下有定义好的对应的逻辑来迁移变化和改变这种状态 。
我们可以从部署架构、状态判断、异常的处理过程 , 这三个方面抽象出整个高可用模块的类型 。

文章图片
a.节点关系
高可用管理模块 , 从抽象来讲 , 无外乎几种情况 。
一种情况是集中式的高可用管理模块 。 实际上就是一个集中的组件 , 它可以管理两个甚至多个集群 , 而所有的集群、主从数据库 , 它们的同步以及状态、切换等等都会把这个状态收集和上报的这种集中的数据库管理组件 , 然后这个高可用管理模块作为一个集中的地方来进行高可用状态和动作统一的管理和协调 , 这是一种管理方式 。
另外一种方式 , 如果是两个或者三个组件本身直接是在两个数据库节点之间的 , 它不需集中 , 两个就可进行比较和判断 。 比如一个主库有多个从库 , 主库来选从的时候 , 根据每个从库对应的日志的号或者数据丢失的数量 , 从最少的数据、最新的实例来协商判断它应选取哪个数据为主 。 这事实上是在一个数据库集群内部的一种方式 , 通过各个节点本身具有的日志和数据状态进行高可用切换的状态判断 , 然后在异常情况下进行这种状态的对应高可用逻辑处理 。
第三种实际上是分布式的方式 , 就是说集中高可用的组件和模型不是统一集中在一个地方 , 也不是在数据库本身中由它们自身来协商的 , 而是通过多个节点 , 然后形成一种分布式的这种状态 , 通过分布式算法来进行高可用的判断和使用 。
从部署的架构来看 , 高可用管理模块有集中式、协商式、分布式这种三种类型 。
b.状态判断
【PostgreSQL|MySQL和PostgreSQL通用高可用的设计与实践】从状态判断来讲 , 高可用组件和模块需要实现的功能 , 第一就是能够获取哪个节点的状态 。 比如主库或者从库它们是否存活 , 是否有延迟等等 。 高可用 , 最主要、最根本的内容就是解决是否存活的问题 。 如果存活了 , 那状态判断中就知道 , 如果不存活 , 判断主库挂掉 , 之后有高可用会进行相应的高可用切换逻辑 , 然后从库拉起来继续提供服务 , 保证业务的连续性 , 实际上这是从高可用的本质和原理来推断出来的 。
高可用组件一定要对数据库本身进行状态的变化 , 一方面 , 它能检测状态 , 另一方面 , 能把状态进行存储 , 对状态进行管理 。
c.异常处理
第三个方面 , 高可用模块可用来做什么?实际上就是在异常情况下进行异常的处理 。
实际上高可用组件最常用、最根本的一种实现方式 , 就是异常处理的方式 。 如果高可用组件对不同的数据库实例它们的状态实时进行监测 , 并且被存储 , 然后在某个主库发生宕机或其他故障时 , 高可用组件可以根据它定义的逻辑来确认它们的状态 , 来获取日志 , 应用日志 , 保障数据 。 再深入说 , 在故障的时候 , 高可用组件通过状态判断可以知道对应的状态情况 , 如果触发了故障切换过程 , 可以进行切换 , 主库在恢复正常的时候 , 能不用重办 , 就是把失败之后已经恢复正常的节点 , 再添加到集群当中 , 让前端的统一接口来重置 , 如果它没有主从的关系 , 就让这些主从的关系重新建立 , 这些实际上就是高可用模块所实现的功能 。
3)统一访问模块
底层的数据库通过数据库本身的机制 , 我们也进行可用性和一致性的权衡抉择 , 来实现底层数据库实例有多个地方 , 然后我们有高可用组件 , 对不同的实例进行状态的监控 , 然后在发生异常的时候 , 高可用组件会有对应的逻辑来改变对应的实例的状态 。

文章图片
高可用架构的接口或者对外提供的服务和访问 , 最好是同一个系统 , 这样的话 , 无论是中间层 , 或者业务程序直接连接 , 它们都可以不用修改配置和变化 。 当数据库在存储层面发生了故障 , 故障会有对应的逻辑来处理之后 , 它就可以继续正常对外提供服务而没有任何的影响 。
应用和数据库访问的方式 , 可以通过直接连接数据库 , 或者通过中间层来访问数据库 。 直接连接数据库 , 业务程序和数据库的耦合性会非常高 , 发生故障切换 , 业务需调整 , 修改需手工操作 , 这对于连续性、业务的保障和一致性、持续对外提供服务不是特别友好 。
一般高可用组件都会提供统一的访问模块做统一接收的入口 , 这样可以应用透明 。 即使底层的数据库 , 底层进行状态的检测、状态存储以及不同逻辑的处理 , 整个高可用组件对外启动的访问结果 , endpoint不会发生变化 。
对于中间层的访问一般来讲有这几种方式的:
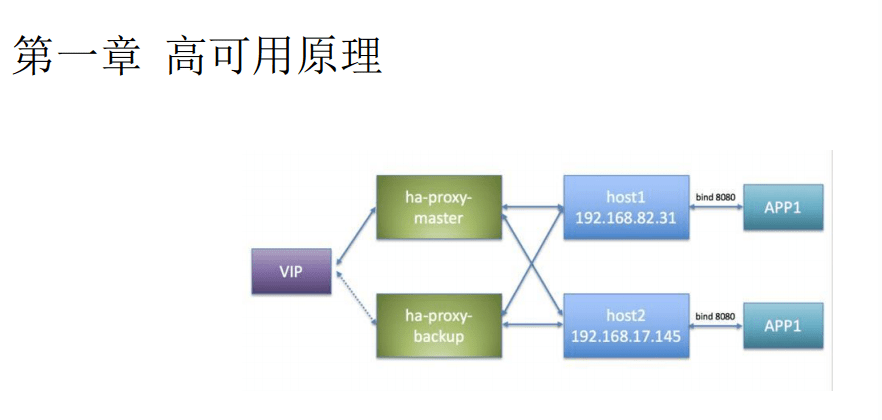
- 第一种是通过VIP , 通过IP地址的方式 , IP地址可以进行漂移 , 在不同的服务器上 , 通过对应的逻辑可以让IP地址进行添加和删除 , 然后业务程序通过访问 VIP可以漂移到IP , 访问不同的组件 , 实现高可用的功能;
- 另外一个是DNS , 和VIP类似 , 但是他们在网络层面划分不同 , 切换的方式和机理不同 , 例如VIP是针对于服务器 , 如果跨网段、跨机房会不太容易实现 。 DNS则可以通过DNS服务器 , 尤其是跨网段或者说跨网络的时候 , 只要能够解析到 , 这时候它可以进行更广泛的应用 , 统一接口的访问;
- 另外是通过proxy 。 proxy是一种对VIP和DNS等方式的一种进一步封装 。 如果业务通过proxy访问数据库 , proxy地址本身具有高可用 , 通过访问proxy , proxy在底层实现对应的漂移、变化、不同情况的转换 , 不同接口来访问不同的后端数据库实例 。
3、典型通用高可用方案
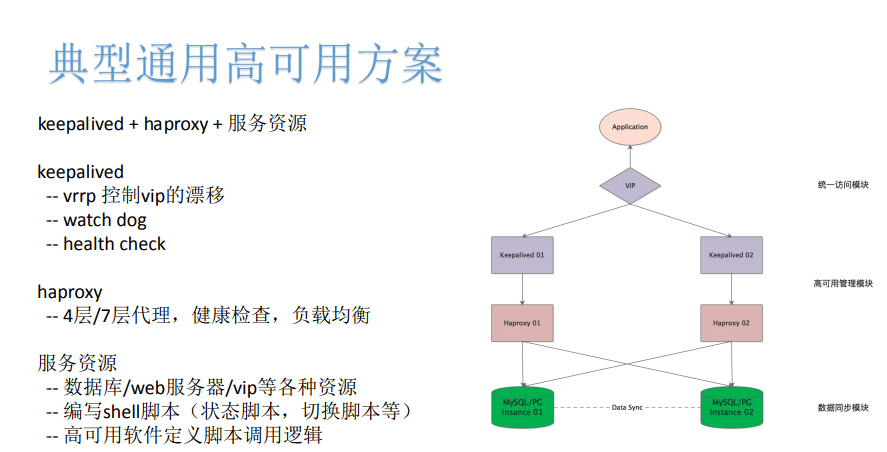
有一种典型通用的应用方案 , 不论是之前在 Linux服务器里面 , 或者说现在比较流行的网络VPS虚拟服务器 , 都存在并应用非常广泛 , 就是keepalived + haproxy + 对应的服务资源 。 keepalived通过vrrp控制VIP的漂移 , 同时它也具有watch dog和health check这样的功能 , 可以统一的对外来提供访问模块 。 然后haproxy可以进行底层的健康检查、负载均衡 , 这也是一种高可用的状态检测和处理逻辑的一种方式 。
文章图片
底层的资源 , 一般数据库服务器 , 或者是外部服务器等 。 实际只要是任何可以管理的资源 , 他们都可以作为这种高可用架构的底层资源 。 它们调动的逻辑也可以通过shell脚本或者状态检测脚本来进行状态检测 。 底层资源类似于我们高可用解析的数据同步模块来解决底层实际资源本身的同步或者底层资源的冗余 。
keepalived本身的一些功能 , 比如健康检查 , 或在不同的情况下调用不同的shell脚本功能等等 , 这些实际上就是状态检测和处理逻辑的高可用管理模块 。
最后的VIP是统一的对外的统一访问模块 , 这样应用程序通过VIP可以来实现统一 , 就是不用修改访问地址的这种访问和方式 , 然后底层在多个节点通过keepalived和haproxy可以来实现这种状态的检测和异常的处理 , 之后底层再来实现 。 这是一种最典型、通用、架构也非常清晰的一种高可用解决方案 。
当然 , 这两种方案 , 事实上对于数据库也是适用的 。 不论哪种数据库 , 底层通过数据库各种不同的数据库全量备份和增长同步来建立数据同步的机制 , 通过haproxy和keepalived来分别实现健康检查、负载均衡和其它的一些代理的功能 , 最后VIP段提供服务 , 这也是一种通用的数据库高可用方案 。 这种实际的方案和我们理论抽象中的高可用的模型和每个高可用组件 , 它实现的功能可以进行一一对应 , 这样就比较容易知道高可用组件它为什么要有这些组件 , 以及每个组件有什么样的功能 。 反过来 , 如果结合了实际的案例 , 或者结合到了实际的技术当中 , 每一种组件 , 它为什么存在以及它对应高可用用的哪个部分就会非常清晰 。
我们知道了数据库本身的高可用的模型 , 也知道了为什么要有这种模型 , 因为底层的同步模块它是为了实现数据库的冗余 。 高可用管理模块它是为了实现不同事务实例的状态检测 , 及异常情况的数据去处理和结合 。 然后最上面的统一访问模块 , 它是为了应用透明 , 保证我们整个体系架构对外提供访问的时候 , 是有一个不变的访问接口 。
这三个组件有不同的功能 , haproxy和keepalived再加上资源 , 这是一种常用的、通用的处理方式 。
但是具体到某一种数据库 , 除了keepalived等这种典型的方式 , 每种数据库本身也会有一些高可用处理方式 。 比如像Oracle数据库 , 它直接用Oracle RAC技术 , 除了Oracle数据库 , 其它的通过Oracle Clusterware的这样一个统一的集群件 , 一下子来实现整个数据库集群的状态、管理、检测 , 对外提供统一的访问接口 , 这样的话 , 这个集群件就相当于把高可用管理模块和对外统一访问模块的功能一下子全部实现了 , 底层通过数据库的数据同步或者共享磁盘来完成 , 这是一种处理方式 。 因为它是商业软件 , 它实际上就通过它本身的一个专门的高可用集群线来实现这些功能 。
MySQL、PostgreSQL数据库 , 是开源的数据库 , 产品本身解决数据库本身的各种问题 , 比如事务问题、日志问题、备份恢复问题等等 , 因为开源产品都并不一定提供 , 或者并不一定提供的那么完善 , 它就会有很多第三方的开源组件 , 然后通过这些开源组件和数据库本身来结合 , 最后实现整体的高可用 。
二、MySQL高可用实践
1、MySQL数据同步
对于基础的数据同步模块 , 不同的数据库类型 , 它们的实现原理其实都还是一样的 。 比如MySQL数据库同步除了全量复制之外 , 有状态的数据能一直持续的同步最主要就是因为有日志 , 然后它可以设置主从同步当中的这种主库对应的日志 , 通过Master写入binlog , 然后binlog通过数据传输的进程 , 同步到从库上面 , 然后在从库上面应用日志 , 保证实时的数据的变化同步 。

文章图片
当然 , MySQL数据库底层的同步 , 它实际上就是复制方式本身 , 在数据库产品或者数据库本身功能的完善 , 它也会有刚才我们所说的全量同步和不断增量同步的过程 。 比如说最初提供的这种异步复制 , 实际上就是只需要主库开通用户权限 , 从库上面来指定对应的主库 , 然后一一对应的日志起始点从哪点来开始 , 就可以代建出同步复制 。
搭建异步复制 , 可以保证最高的高可用和主库最高的性能 。 但是在一些极端情况下 , 比如说主库的量比较大 , 还没来得及传输到从库 , 然后从库又断了 , 这样主库还未传到从库存的日志及变化 , 就可能有一定的数据丢失的风险 。
MySQL还提供了半同步复制 , 就是说主库从库都可以增加安装半同步复制的组件 , 开启半同步参数 。 如果一个主库有多从库的话 , 这时候主库发生数据变化 , 要提交事务时候 , 它会至少等待一个slave , 就是一个从库来接收到它的数据变化 , 至少有一个从库与它保持一致 , 它才会完整提交 , 这样就不必等所有的从库都完全一致才能提交 。 这样既有一定的数据一致性 , 对数据同步也比异步复制有更高的一个状态和实践 。
再之后 , 有了GTID的复制 , 可以开启GPS参数 , 简化 CHANGER MASTER 。
MySQL 5.7及8.0新推出的MGR复制 , 依赖Paxos这种分布式的协议 , 然后复制当中 , 在一个复制集或者一个组一个集群当中 , 有一半以上的节点通过后事务才能提交 。 通过这种分布式的协议可以保障数据至少会在一个集群当中的一半以上的节点来存在 , 这样来实现同步 。
对于MySQL数据库 , 它实际上有几种不同的原理 , 通过不同的版本不断来完善同步的类型以及机制和方式 , 尽可能的使数据库的可用性和数据同步、数据一致性有一个更好的平衡 , 从高可用组件来讲 , 对数据同步层建成的组件来进行完善 。
2、MySQL高可用方案之MHA
除了数据同步层之外 , 还有两层 , 一个是高可用层 , 一个是统一对外接口 。 数据库之前的版本 , 比如5.5及5.5之间的版本 , 最常用的数据库MySQL高可用方案是MHA 。 MHA这种组建 , 从数据同步模块来说 , 都是通过MySQL本身提供的数据同步服务 , 它可以搭建MySQL的异步复制 , 也可以搭建MySQL的半同步复制 。 这样 , 通过MySQL组件本身的功能来实现 , 来实现数据库复制的功能 。
对于集群管理模块 , MHA就是我们上文所说的第一种情况 , 就是集中式的高可用管理组件 。 它分MHA Manager和MHA Node等 , 它相当于一个MHA的管理节点 , 它可以管理多个 MySQL的集群 , 然后每个群的状态 , 它可以通过Node的节点来进行采集 , 最后都存到MHA Manager , 通过集中化的状态检测和发现 。 然后当状态触发了这种故障 , 为了保证高可用 , 来调用对应的一个脚本实现应用切换 。
这种切换可以是异常情况下的切换 , 也可以是我们正常情况下要进行主从不同角色的主动切换 , 来进行特殊的升级滚动操作等等 , 也可以用来online_change脚本的这种交互方式 。
对外提供统一访问的模块 , 是通过VIP的方式 。 应用程序通过 VIP来实现统一访问接口 , 然后通过MHA Manager加MHA Node , 这两个集中式的统一管理和每个节点信息采集这种状态结合 , 来形成了我们的第二个模块层面高可用管理层面 , 然后数据库本身来实现数据库本身统一采集的模板 。 这样的话 , 我们在了解和知道高可用整体架构模型的基础上 , 再看这样一个具体的方案 , 就会非常清晰 。
1)MHA搭建

文章图片
具体实施上 , 大概有上图这样8个步骤来搭建出MHA的 。 重点的是高可用管理的时候它有故障处理的流程 , 实际上就是通过Node节点来知道每个节点的状态 , 然后与 MHA的Manger节点进行沟通 , 来监测主库和从库 。 如果主库发生异常 , 把主库关闭 , 然后来应用日志 , 恢复的一个新主 , 把新的主库激活 , 然后再恢复从库 , 让从库重新指定 , 这是一种比较典型的这种高可用组建 。
3、MySQL高可用方案之MySQL Innodb Cluster
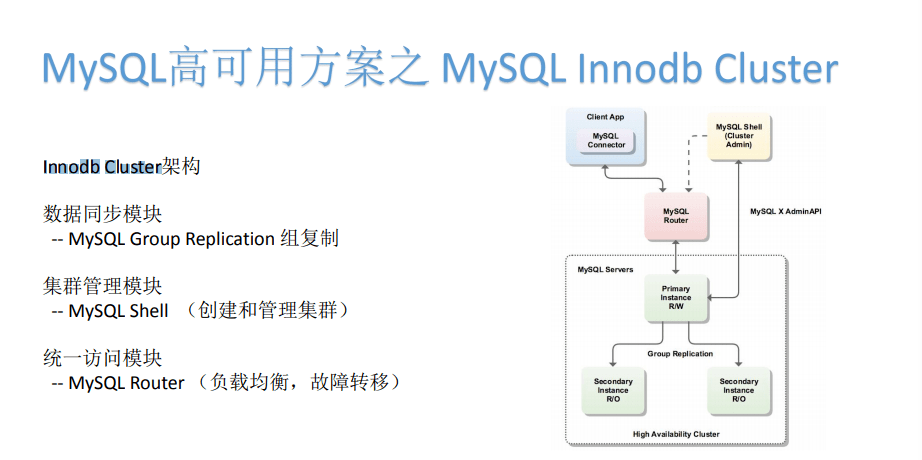
在5.5之后 , 由于MySQL本身的复制方式 , 数据同步模块可以做得更好 , 有一些更加完备的高可用的方式出现 , 比如Innodb Cluster这种架构 。
文章图片
这种架构的话与之前的版本有所区别 , 因为这种数据同步模块 , 它通过MySQL Group Replication 组复制这种方式 , 它有一个主的实例 , 然后有两个或者多个从库的实例 , 它们统一来形成MySQL数据底层、数据同步层的功能 。
数据集群的管理 , 主要通过MySQL Shell组件 , 这种组件可以进行底层数据同步的管理 , 包括一些其它的管理 。
对外访问 , 则通过一个MySQL Router 。 MySQL Router可以进行负载均衡或者故障转移 。
1)Innodb Cluster搭建
MySQL官方通过三个不同的组件 , 来分别与高可用本身必须要实现的三个模块来分别对应 。 主库主要来对应数据库同步管理模块要实现的功能 , 它的实现方式比原来的异步复制或者半同步复制要更加健壮一些 。

文章图片
另外 , 对外提供访问的接口 , 也不用我们自己来配VIP或者DNS的话 , 它就通过MySQL Router这个组件来实现对外统一的访问接口 。 对于管理来讲 , 它提供MySQL Shell , 当然MySQL Shell这种管理组件本身需要再加上主库的一些功能 , 共同来实现高可用管理模块 。
换句话 , 在MySQL提供了组复制新的功能 , 对于高可用的管理方式就和原来MHA不一样了 , MHA的话 , 底层的同步、异步复制或者半步复制是由我们MySQL数据库本身来进行管理的 。 但是高可用组件 , MHA Manager、Node的这两个节点是第三方 , 然后VIP或者DNS也需要单独来实现 , 就是出了数据同步是用MySQL本身的功能 , 另外两个模块都是单独的实现 。
Innodb Cluster , 它实际上就相当于这三个组件或者三个功能都是用MySQL官方来实现 , 只不过还是要分三个不同的组件来实现不同的功能 , 这样的话才能保证和实现一个相对来说完整组件的功能 。
大家在生产环境当中来使用Innodb Cluster , 需要注意的一点 , 就是现在产品 , 虽然8.0后又发布很多新版本 , 但因为它采用分布式的协议 , 会有一些特殊情况的出现 。 目前功能性和稳定性还存在一些问题 , 所以建议还是采用主库当中的Single-Primary , 就是我们的数据系都还是在这种分布式体系当中的单个主节点来 。 然后这时候的话 , 其它节点都是主要来提供读 , 如果是小的 , 我们就固定在一个节点 , 这样的话它的稳定性和高可用性就会更好一些 。
2)MySQL高可用方案文档与测试

文章图片
对于刚才我们方案的这些具体的实践 , 上图里面有一些文档 , 大家要进行测试 , 或者进行生产环境的部署来使用验证的话 , 可以参考文档 。
三、PostgreSQL高可用实践
对于PostgreSQL数据库的高可用实践 , 从原理来讲 , 我们高可用必定要实现数据同步层、高可用管理层以及对外统一访问接口这三个层面 。 那么PostgreSQL数据库和MySQL数据库的常用高可用组件版本和各方面也会有稍微有区别 。
1、PostgreSQL数据同步

文章图片
a.日志格式
首先在数据同步上 , PostgreSQL的数据库 , 它与MySQL数据库的日志格式有所区别 。 PostgreSQL数据库 , 如果既想支持物理复制 , 又想支持逻辑复制 , 需要注意 , PostgreSQL , 因为它的日志叫wal日志 , 这种WAL日志基本参数要这样设置:wal_level=logical 。 对于PostgreSQL数据库 , 它是记录日志最全的一种方式 , 既可以进行物理日志这种全部记录 , 又可以进行逻辑这种文件的解析 , 所以PostgreSQL日志格式建议采用logical模式 。 只有先记录这种全量的 , 有所有信息的日志格式 , 我们后面才更好进行PostgreSQL的搭建 。
b.主从搭建
比如对PostgreSQL数据库的 primary和standby主从库的搭建 , 我们一般也要有先有主库对应的账号 , 先进行全量的同步 , 然后建立主从实例复制关系 , 指定对复制信息 。 当然 , 对PostgreSQL数据库来说 , 一样在同步复制 , 就数据复制的模块来讲 , 也需要考虑数据一致性、可用性的权衡 。
首先 , 直接用物理复制方式 , 它可以保证主库性能最好 , 主库的可用性最高 。 但是在及其严格的情况下 , 主库到从库的日志可能有少许丢失的 。 异步流复制 , 即主库发生了数据变化 , 就是数据变化的记录 , 然后按照现在流程最终把这些变化记录到日志当中 , 它并不会管从库是否收发并且应用了这些日志 。
当然 , PostgreSQL也有同步流复制 。 同步流复制 , 主库要进行一个数据变化 , 变化了之后 , 它在数据提交完成之前 , 在主库上进行持久化数据之前 , 它需要从从库里面收到反馈信息 , 根据同步参数设置的级别方式不同 , 看从库是只需要接受到文件 , 还是运用文件 , 还是运用之后要写到数据库里面 , 保证数据严格一致 , 这样就是同步流复制 , 可以保证数据的不丢失 。
主库每次发生变化 , 除了主库本身在各个组件和功能会有影响之外 , 从库功能和各方面也会有影响 , 这些都会造成本身性能降低 。 同时在可用性上 , 如果网络或者从库等 , 发生异常量之后它接收不到 , 那么主库的功能和业务连续性就会受到影响 。 所以说同流复制和异步流复制也是需要有一个权衡 , 根据对数据可用性和数据的一致性 , 哪个要求更高来进行选择 。
除了这种同步的流复制以及物理复制之外 , 还可以进行逻辑复制 , 来进行部分表或者部分库的同步 。
c.同步类型
对同步的实现 , 可通过数据库的流复制 , 对PostgreSQL , 还有很多第三方的组件 , 比如说可以通过共享存储的这种同步来达到实例的同步 , 或者通过WAL日志/流复制的方式来进行 , 或者基于中间件的同步的方式 , 但从实际经验的角度 , PostgreSQL虽然支持很多复制方式 , 一般建议的方式还是PostgreSQL本身所提供的物理流复制这种方式 。
当然 , 如果数据库业务对性能要求很高的话 , 一般采用WAL异步物理日志流复制 , 最大限度的保证主库是一个非常好的性能以及它的可用性 。 如果对于一致性要求更高一些 , 可以采用同步或半同步流复制 。
2、PostgreSQL高可用方案之pgpool-II
我们通过数据库本身的功能知道了流复制后 , 结合上面对于数据高可用组件的三个模块 , 就是高可用组件以及统一访问模块这两个模块的不同 , 可以有不同的方案 。
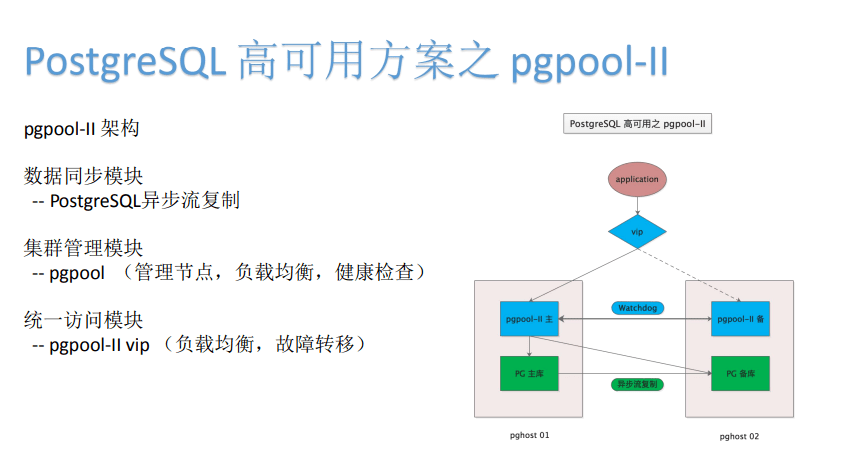
比如PostgreSQL高可用方案pgpool-II 。 pgpool-II底层的同步模块采用PostgreSQL异步流复制 。
文章图片
流复制有个好处 , 它与逻辑相比 , 会少了一些数据、日志文件的一个解析的过程 , 主库写了文件量之后 , 到了从库里面它是针对数据块进行的复制 , 直接进行应用 , 严格意义上的保证数据的一致 , 并且少了解析 。 这样主从库之间的数据延迟会少很多 , 所以流复制的稳定性一般都会比较好 。
pgpool-II集群管理模块采用pgpool-II中间件的方式.这种中间件,一方面pgpool里面来配置一个PostgreSQL集群的主库、从库 , 如果多实例进行读的话 , 可以进行读业务的负载均衡 。 如果发生故障的话 , pgpool-II它会健康检查 , 出现故障后 , 它就不会把服务和应用往对应实例上来进行发 , 这样就可以实现底层的这种高可用逻辑的判断、使用 。
如果是主库发生了故障和问题 , 可以事先定义好 , 主库如果发生故障了之后 , 会替换和切换某个从库成为主库 , 然后加上其它从库 , 重新建立主动同步关系 , 然后将写应用等也转发到新的主库上面这样一种逻辑 。
高可用的逻辑 , 通过 pgpool本身的健康检查、负载均衡来实现 , 然后对于写逻辑 , 就可以通过切换脚本 , 实现主库在异常情况下从库的这种迁移 。
对于数据库统一的访问模块 , 可以通过VIP地址统一访问前端 。 pgpool-II一开始的版本 , VIP是需要我们单独的配配置 , 但近几年的新版本 , pgpool-II本身相当于把高可用管理层和统一对外接口层这两层结合在一起了 , 它本身提供了VIP的配置和管理的功能 。 这样启动了pgpool-II之后 , 配置了它的watchdog功能 , 可以在多个pgpool-II之间进行健康检查 , 然后可以提供统一对外的VIP机制 , 这样整个高可用组建就只需要两个组件 , 一个组件是PG , 数据库本身异步流复制或者同步流复制来实现数据同步的功能 。 再往上 , 就是pgpool-II这种组件 , 它既实现了这个数据库的节点管理、监管检查等等 , 也实现了VIP , 也实现了统一个对外接口 。 通过pgpool-II这样的一个功能 , 同时实现了高可用组件对外访问层和高可用管理层两个功能 。 从软件和组件来讲 , 这两个组件实现了我们高可用模型当中的三个模块功能 。
1)PostgreSQL pgpool-II 搭建
上图是我们具体实施一个pgpool-II的方案 , 一个整体的搭建思路 。 pgpool-II继承的功能很多 , 它可以当连续池 , 也可以只读请求负载均衡 , 也可以有高可用 。 它有4种运行模式 , 进行数据同步 , 我们跟官方一样建议同步用数据库来做 , 用数据库本身的物理流复制会比较稳定和高效 。

文章图片
需要注意 , 如果切换脚本时主库与备库的数据差异 。 因为加了一个中间件 , 所以业务访问都需要过程中间件 , 对性能会有一定的损失 。 如果进行主备切换之后 , 主库发生了故障和变化 , 这时候它需要手工再恢复到继续原来的集群状态 。
3、PostgreSQL高可用方案之patroni
近年还有一种比较流行和经典的高可用就是patroni 。
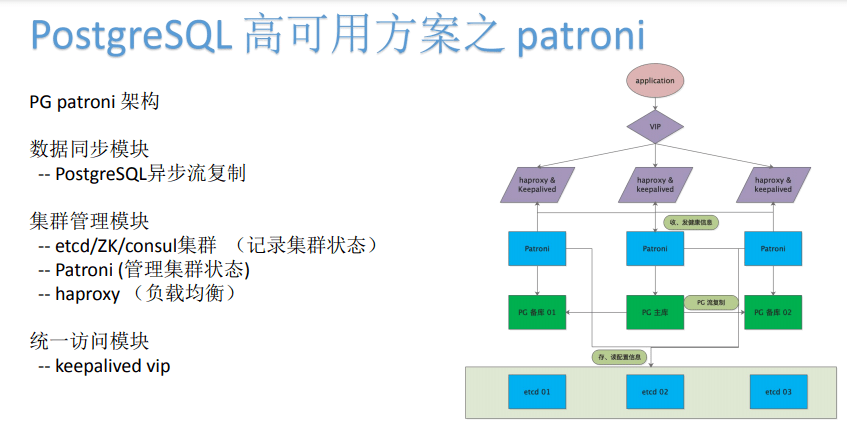
首先数据同步上 , 它使用PostgreSQL异步流复制 , 这也说明PostgreSQL异步流复制 , 在复制的这种准确性、一致性及性能方面已经做得比较完备 , 不需要其它第三方组件再来实现相似功能 。
作为高可用组件 , 它的特点 , 是对于集群管理模块它还进行了细化 , 并且有多个组件来实现 。 即每个高可用组件本身 , 它会与PG数据库的主库和从库来进行访问和读写 , 来进行状态的变化 , 它获取PG节点状态的变化之后 , 会记录和存储PG节点的状态 。
文章图片
记录和存储 , 它可以存储在etcd/ZK/consul分布式集群中 , 然后进行集群状态的记录 , 如果发生主从库的实例宕掉 , 或者物理服务器宕掉等等情况 , 它本身的处理逻辑是在集群本身定义的不同逻辑的处理情况 , 然后最上面有haproxy来进行负载均衡 。
这样的话 , 实际上就相当于集群管理模块 , 状态检测、状态存储 , 不同的业务逻辑及负载均衡 , 乃至最上面的高可用等等 , 这几个不同的组件在这个高可用方案中都用了不同的软件来实现 , 最终组成一个Patroni的高可用方案 。 它是由Patroni管理组建的几个分开检测、负载均衡和集群管理 , 使用不同的组件和软件来实现 , 会显得复杂 。
但它是有利于高可用组建的各个功能的 , 比如说数据库整个底层集群的搭 , 因为它有统一的这种分布式的状态处理和管理 , 再加上多种情况的完善的业务处理逻辑 。 这种集群组件 , 虽然复杂 , 但是它可以记录和获取不同的实例状态 , 并且可以存储在一个分布式的集群当中来进行状态判断 , 之后还可以有不同的集群的处理逻辑来实现不同状态下的记录处理 , 这样就可以达到高可用组件不论发生了什么情况 , 它都可以自动恢复 , 让整体恢复正常 , 达到很好的自动化实现 。
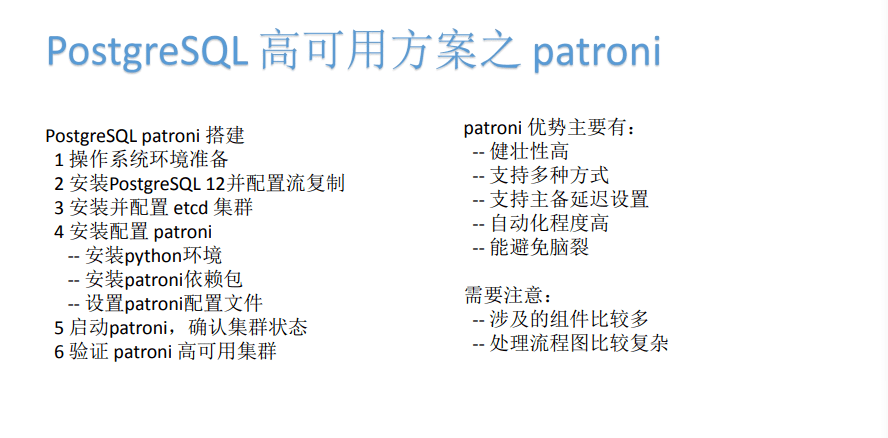
1)PostgreSQL patroni 搭建
文章图片
上图是搭建 , 主要是提供一个思路和借鉴 。
这种patroni的方式 , 它就是把集群这个部分的多个功能 , 如状态检测、负载均衡、不同情况下的脚本处理等 , 通过不同的组件来实现 。 它虽然有一定的复杂性 , 但它的健壮性非常高 , 不论什么地方 , 它都具有比较完善的高可用 , 支持多种方式 , 支持主备延迟设置 , 自动化程度高 , 能避免脑裂 。 所以patroni , 对于集群件的另外一种处理思路 , 就是它可以对于集群件本身来进行细化 , 不同的组件实现不同的功能 , 最后全部统一组合成一个统一的集群管理模块 。 这样一来 , 虽然耗费了比较多时间 , 但是带来的好处可以使我们高可用资源更加的完备 。
2)PostgreSQL高可用方案文档和测试

文章图片
上图这是PostgreSQL高可用方案pgpool和patroni的文档 , 大家如果要进行测试 , 或生产环境使用 , 大家可以参考 。
四、Cloud高可用与高可用发展
最后稍微谈一下Cloud高可用与高可用发展 。
1、Cloud高可用
不论云上的高可用还是RDS的高可用 , 它主要有一些区别 , 就是我们的原理 , 就是我们高可用的模型 , 不论是哪种数据库 , 不论是数据库的类型 , 不论是已有的还是将来发展的 , 都肯定会抽象 , 出这种抽象的模型 。

文章图片
对云上和我们自建 , 需要知道一些区别的 , 比如说云上RDS的服务 , 需要wal_level=logical 。
有些云平台 , 对于数据同步模块 , 会采用基于流复制的高可用 。 有些云平台会采用共享存储的高可用 。 不同的云平台高可用切换的时间 , 以及它们对读业务和写业务的时间是不一样的 , 所以如果是要在云平台上用高可用选型 , 要注意这一点 , 由不同的业务来不同的处理 。
一般在云上的服务来进行高可用切换或者发生故障的时候 , 保证所有的数据写、数据读是正常的是可以的 , 但保证数据写完全一致 , 目前是很难做到的 。 一般能做到10秒左右或者10秒以下的损失 , 可能已是目前做的比较好的了 。
我们自己搭建云服务 , 云服务它还有些限制 , 比如VIP 和 keepalived 平台是不支持的 , RDS服务只有内置slb和proxy , ESC自建用proxy + slb 。 这是云平台上一些简单的不同的限制 。
2、高可用发展趋势
高可用发展的趋势 , 上文我们通过原理剖析了通用的方案 , 又分析了MySQL和PostgreSQL的一些特殊的方案 , 我们可以知道 , 高可用根本目标基本的三方面原理是不变的 。

文章图片
具体不同的模块的发展实际上是在不同的功能上的 , 就像MySQL数据库一样 , MySQL数据库本身可以在数据同步的机制、同步的方式上 , 有异步到半同步、同步等等 。
高可用组件也可以有各种不同的思路 , 可以集中处理 , 可以分布式 , 可以集中式的统一在一个点 , 也可以是进程的一个组件来实现高可用其它模块的功能以及统一对外接口访问的功能 , 也可以是使用多个组件共同来实现不同的细化的 , 这样虽然增加了复杂性 , 但是带来的是自动化 , 是整个集群的健壮性 。
无论是一个组件来实现所有的功能 , 或者每一个功能 , 我们再细化不同的地方 , 通过多个组件来实现 , 它都必定还是要实现高可用模型当中的数据同步的功能 , 实现高可用管理功能以及统一对外接口访问的功能 。
3、数据库高可用与业务结合
高可用方案 , 我们从技术角度分析了这么多 , 最终是要与业务进行结合的 。 单一的某种架构想百分百、绝对意义上的高可用是很难的 , 甚至很多业务场景是不太可能的 。

文章图片
实际上我们在高可用发展的时候 , 我们的初衷 , 乃至一些功能的实现 , 都需要考虑业务的实际情况 , 比如我们反复强调的数据同步机制当中的数据一致性和数据的业务连续性和可用性进行权衡 , 需要结合业务或者是应用本身更看重数据的哪些点来判断 。
另外不论是什么高可用切换 , 尤其是人工的切换 , 尽可能在业务低峰期 。
我们从技术角度可以对高可能性进行很多抽象的描述 , 但最终要实现一个完整的高可用和业务的健壮性 , 实际上都需要业务的技术架构与业务场景进行结合 , 进行不同的匹配 , 来实现和完成对于这个业务最合适、最好的高可用的架构和方案 , 实践对应的高可用 。
好 , 我今天晚上的分享就到这个地方 。
>>>>
Q&A
Q1:高可用主要监测哪些故障 , 或者可以监测哪些故障 , 在日常维护中有哪些注意事项?
A1:我们从定义来分析 , 它主要是用于监测可用性 , 即如果没有主库有从库 , 那么可用性是一个非常重要的指标 。 实例是否存活 , 业务是否可用 , 是否连得通 , 即存活性以及连通性是最根本的 。
绝大多数高可用检测的故障一是存活状态 , 二是网络状态 。 网络状态与存货状态有一定的关联性 。
假设我们网络是稳定的 , 在网络正常的情况 , 实际上这就是实例的存活状态 。 存活状态如果想细化 , 需要看情况判断是否需要细化 。 比如要查询一套数据 , 能查询到 , 我们就认为正常 , 这实际上就是高可用组件对于业务状态的健康定义 。
或者我们选一个固定的用于监测的表 , 来进行update , 我们就一条记录来update , 对应看每次查询update , 我们一方面要保证数据库的端口在 , 另一方面保证有数据 , 第三个能修改、能读取 。
这时候 , 我们对于数据库的一个检测 , 最主要就是能检测业务存活状态 , 业务存活状态的标准 , 实际上指是否服务存活 , 是否能够读 , 是否能读写这三个层面 。
Q2:PG的两个高可用方案分别使用场景是什么呢?
A2:使用场景是这样 , PG有两个高可用 , 一个是Pgpool-II的方式 , 它是能够实现负载均衡、故障转换 , 然后包括它们配置VIP、统一对外访问的接口 。 如果我们想比较简单的业务场景 , 想实现连接池 , 实现对高可用 , 这些有要求 , 但是不高 , 或者对于自动化 , 如果发生高可用切换了之后 , 对自动化的要求不高 , 同时想实现负载均衡、VIP简单配置的时候 , 用Pgpool-II的方式 。
如果对于高可用、自动化的要求会非常高的话 , 可以考虑利用Patroni , 利用Patroni , 一般我们建一个节点至少是一组两层 , 至少是三个节点 , 然后它需要配置etcd , 需要配置haproxy本身 , 然后甚至还有一些proxy和keepalive , 它需要配置的东西比较多 , 但是它自动化和连续化会比较好 。
两个方案 , 一个是比较简单的 , 可以实现基础功能 , 用一个组件可以完成很多的这种功能 , 比较适合于对可用性有要求 , 但是要求不高 , 或者想要自动化、易维护、易使用的高可用方案 , 可以用Pgpool-II来解决 。
如果使用Patroni的话 , 即对于一些复杂的高可用的场景 , 或者比较重要的高可用场景 , 维护有一定要求的 , 可以用Patroni的 。
Q3:MySQL如何自动kill慢查询 , 什么方式好?
A3:如果想自动慢查询的话 , 一个比较好的方式 , 实际上的就用pt-query-digest工具 , 用pt-query-digest这个工具 , 可以一下子能够找到你所匹配的 , 直接来应用 , 它的效率和状态会非常快 。
Q4:能否举例说明哪些场景使用同步复制 , 哪些使用异步复制 , 哪些使用半同步复制?
A4:实际上不同的同步的场景 , 不同同步的类型 , 我们刚才说了主要是业务连续性和数据一致性的一种平衡或者一种追求、一种偏向 。
一般来讲 , 我们偏向判断这三种方式 , 主要看我们的业务 。 从我们业务哪些特点来看:
- 第一是业务的性能 , 看性能要求的高低;
- 第二是业务对于数据连续性要求的高低;
- 第三对于数据业务数据是否可丢失的角度来看 。
同步复制 , 性能肯定会比较低 , 因为它要等同步 。 对于业务的数量 , 就是数据交易量并不是太大 , 但对数据一致性要求非常高 , 并且可接受异常情况下 , 宁可业务挂掉 , 也要保证数据不流失和数据准确的业务场景需要用同步复制 。
异步复制 , 对于性能要求很高 , 数据允许丢失 , 但更加追求服务的存活性 , 而不是数据的准确性的这些业务 , 使用异步复制 。
半同步复制 , 实际上就是在两者进行权衡 , 对数据一致性和可用性都有要求 。 简单来讲 , 追求性能 , 追求可用性 , 极限情况下数据可丢失、可不一致 , 可用半同步复制 。
如果数据更加追求的是一致性 , 对于性能、对于连续性相对来说没有太要求 , 或者说两者进行2选1的时候 , 必须要选择一致性 , 极限情况下宁可都不选 , 那么就同步复制 。
Q5:MHA方案是只适用于小集群吗?为什么呢?
A5:MHA也不一定是小集群 。 因为MHA方案是日本的一个数据库方面的专家所写的一个软件 , 很多年没有更新了 , 所以MHA主要是因为版本和更新的限制 , 只有国内一些厂家自己在原来MHA的逻辑上自己去写了或者更完善 , 但目前好像并没有开源出来 , 它不一定是小集群 。 MHA的检测逻辑非常简单 , 它直接来看数据库是否存活 , 然后进行切一下 , 没有太复杂的逻辑 。
Q6:PG 9.6能用patroni吗?
A6: PG 9.6也可以 , 但目前最新的PG版本已经是PG 13了 , 建议升到PG 12左右会比较好 , 功能还有性能的优化 , 相比PG9要好得多 。
对于PostgreSQL的高可用方案 , 它实际上都可以支持 , 因为PostgreSQL方案的原理来讲 , 它实际上也是三层 , 即不论是PG9还是PG12 , 它主要解决的是底层数据同步逻辑层的问题 , 只要版本能够支持异步的物理流复制 , 那么你搭建好数据同步就行 , 其它的实际上就是只要是集群里面能够适用吃的版本 , 能够调用这个逻辑就可以 。
Q7:部署文档?
A7:部署的文档的话 , 不同文档 , 我本身在PPT里面已经有了一些参考文档 , 可以大家可以参考 。
Q8:两台服务器 , VIP同时漂移PG和Redis,怎么实现Redis和PG同生共死 , 使用patroni , 从节点挂了不用管;主节点挂了 , 备节点Redis、PG都切为主?偶尔出现VIP漂移后 , 从节点PG、Redis一个主一个备脑裂 , 一个不能写?
A8:这个业务场景 , 我觉得是这样的 。 最好还是把PG和Redis分开 , 分开在不同的场景上面 , 尤其是你用patroni高可用组件 , 因为patroni高可用组件的话 , 实际上是一个Python , 它首先要安装Python , 它相当于一个Python的包 , 然后用这种Python的包来进行PostgreSQL数据库的管理 , 它就是专门针对PG数据库的 , 也很难定义和使用Redis , 让Redis和patroni同生共死 , 因为这个集群件它本身定义好的内容 , 及各种Python的脚本 , Python的逻辑 , 是来管PG的 。
如果用Redis的话 , 如果使用这个集群件的话 , 很难做到它们同时同生共死 。
相对来讲最好的方式肯定是PG , 因为它是关系数据库 。 如果Redis的话 , 它是缓存数据库 , 最好分开 , 因为两个不同的场景 , 不同的需求 , 比起Redis的话 , 主要是涉及内存的大小 。 PG , 它要使用内存 , 而且有时候占的内存还比较大 , 放在一块 , 特别是对内存 , 如果异常情况下内存一宕掉 , 实际上对两者都有很大的影响 。
最好的方式的还是建议PG和Redis分别在不同的集群当中 , 如果确实想放在一块 , 让两者共存 , 建议可以考虑用Pgpool-II 。 不是不用Patroni 。 因为Pgpool-II这种高可用 , 实现的方式就是两个方面:VIP的漂移及状态的变化 。 VIP的漂移 , 能让两者同时切换 , 对节点的变化的话 , 通过shell脚本控制PG也能实现 , Redis也能实现 。 PG和Redis有相同的需求 , 这种方案实现起来也比较简单 。
另外一个好处的话 ,PG和Redis它们脚本在Pgpool-II这种方案里 , 你装了这一个高可用组件 , 它们都需要通过脚本来使用 , Pgpool-II也是要调用脚本 。 你如果真的想让 PG和Redis它们组成、切换都同生共死 , 可以写一个脚本 , 把Pgpool-II和Redis的状态检测和它们的切换放在一个脚本里面来实现 , 这样 , 整个Pgpool-II进行了高可用切换 , 两者都切了 。
如果你Pgpool-II和Redis一起使用 , 可能用Pgpool的方式会更加好一点 , 因为它可以让你自定义脚本 , 你在自定义的脚本当中可以将两者都同时写出来 。
Q9:感觉PG比MySQL同步方式丰富很多 , 为什么会有这种情况?为什么MySQL中基本看不到存储和触发器等同步方式?
A9:主要原因是PG数据库一开始开发的功能比较多 , 号称是开源数据库当中功能最强大的数据库 , 所以它的触发器、中间件等等 , 一开始都可以支持 。
为什么会有那么多方式?因为一开始官方并不提供很完善的同步功能 , 或者官方的物理流复制等一些复制做的还不够好的时候 , 国内外很多人对于高可用有需求就非常迫切 。 只要有数据库就要有高可用 , 有高可用必须要同步模块 , 有数据同步模块 , 就要解决数据同步的问题 , 所以PG因为它一开始组件做的比较完备 , 另一方面 , 同步有很多人尝试 , 通过不同的途径和思路来解决了 , 实现了不同的这种数据库的实现方式 , 所以说类型比较多 。
当然的话 , 现在PG本身尤其比较新的版本 , 11、12甚至13 , 它本身这种高可用版本的集群的稳定性、性能 , 尤其物理复制 , 相比逻辑复制有很大的优势 。 这个官方本身同步做的比较好 , 其它的组件现在虽然有 , 但是实际上使用的不是特别多 。
MySQL , 因为它原本和LAMP、LNMP流通架构中的一部分 , 通过这种方式与Linux、Apache、PHP等组件来结合 , 它实现了一些高并发、同时SQL比较简单的这种业务场景 。 有很多比较复杂一些的功能 , 在开始版本不是那么的完善 , 或者说存在很多问题 , 基本用不了 , 所以就没法有那么多第三方同步放哪 。 另外就是MySQL从一开始 , 它原生的主从复制就做的比较好 , 官方本身提供了这样比较完善的数据同步功能 , 社区或者第三方也不用考虑 , 再用第三方组件来实现 , 这也是MySQL数据同步方案没有PostgreSQL那么多的原因 。
所以说MySQL和PG , 因为不同的功能 , 不同的定位以及官方产品对于数据库同步提升的方式不一样 , 所以说会有这种不同的情况 。
Q10:MySQL 8 高可用首选innodb cluster么?还有其他选择么?
A10:是的 , 如果你要用MySQL 8的话 , 尤其现在已经研发了20多个版本 , 建议就是使用innodb cluster , 因为这是MySQL官方推出的模式 。
这种模式的话 , 因为innodb cluster采用分布式的高可用组件架构 , 将组复制、router、shell等工具集成在一个官方提供的方案中了 , 实际上有点类似于商业版本Oracle数据库 , 用Oracle cluster一个集群件来实现很多功能的这样一种思路和功能 。
官方它提出的这种功能 , 即使现在可能个别情况有一些问题 , 但是后续逐步完善了之后 , 肯定会成为MySQL数据库一个主流的集群建设方式 。 所以建议首选innodb cluster 。
MySQL 8.0 , 建议用innodb cluster 。 一是能够了解官方这个思路 , 另外一方面它是以后的一个发展的趋势 , 其他开源的或集群的组件 , 稳定性还有趋势不是那么的稳定和完善 。 另外 , 如果官方没有做 , 开源软件肯定会很多 , 如果官方做了并且主库稳定了 , 实际上开源的方案就不太用 , 甚至可以不用 。
其他还有一些mysql高可用开源方案 , 比如 mysql replication manager / github orcheastrator 有兴趣也可以了解一下 。
Q11:金融架构一般常用哪个MySQL高可用架构?
A11:金融行业的高可用架构 , 主要自己搭建或者说用第三方 , 实际上和一般的数据库架构一样 , 只是数据同步一般采用同步复制 , 不能丢失数据 。
也有一些专门针对金融行业的脚骨 , 比如现在的cloud云平台 , 比如 , 阿里云上对于MySQL提供的话 , 一般它有三种方式:
- 一种方式的话单实例 , 只有一个主实例 , 它是用开发模式;
- 另外一方面最常用的方式就是主从模式 , 比如高可用模式 , 它实际上是一主一层 , 然后底层来控制 。
- 第三种架构就是金融版RDS , 实际上它是三节点 , 然后通过多节点和高可用处理实现更高的数据可靠性 。 所以说金融行业来讲 , 如果用云平台实践的话 , 可以考虑使用第三方的三个节点分布式高可用这种架构 , 这样的话能有多副本 , 高可用性会更高一些、更强一点 。
A12:这实际上是MySQL和PG它们最初的定位和发展的一个问题 。 我觉得克服主要两方面 , 一方面 , 从MySQL和PG不同的定位来讲 , 它实现的功能确实有强弱 , 随着官方的版本 , 比如说MySQL大的版本 ,5.5到8.0 , 每个大的版本在架构、功能上它都有很大的变化 , 直观体现就是它的软件安装包会大很多 。 不同的新版本的支持就会比原有的版本会强 。
另外一个问题的话就是根据你的业务 , 虽然MySQL可能一些功能对于PG现在来说会弱一些 , 但是功能结合业务来未必会使用得上 , 或者从业务方面能够解决 , 这样的话就可以使支持会更好一点 , 能满足业务需求就可以 。
作者丨赵飞祥
来源丨公众号:dbaplus社群(ID:dbaplus)
关注公众号dbaplus社群 , 获取更多原创技术文章和精选工具下载 。
Gdevops广州站:解答2021运维、数据库、金融科技亟待抉择的三大问题
推荐阅读







- 星链|石豪:在太空,马斯克和美国当局是如何作恶的
- 下架|APK Installer 和 WSATools 同时躺枪:冒牌应用登陆微软应用商店
- 软件和应用|AcrylicMenus:让Windows 10右键菜单获得半透明效果
- 技术|使用云原生应用和开源技术的创新攻略
- 软件和应用|iOS/iPadOS端Telegram更新:引入隐藏文本、翻译等新功能
- 实力比|小米12对标苹果遭嘲讽?雷军:国产手机的实力比想象中强,有和苹果比较的勇气
- Apple|法官称苹果零售店搜包和解协议虽不完美,但可继续进行
- 部落|excel固定显示行列视频:应用冻结窗格同时固定标题行和列
- 最新消息|宝马LG和其他公司正考虑使用量子计算机解决具体问题
- 通信运营商|英国沃达丰、EE和Three将在2022年一同恢复欧盟漫游费用