在“新基建”浪潮下 , 人工智能正成为经济增长的新引擎 , 各行各业开启智能化升级转型 。 算力在其中扮演了重要角色 , 是国家未来竞争力的集中体现 。 但事实是 , 在发展的过程中 , 高速增长的海量数据与更加复杂的模型 , 正在为算力带来更大的挑战 , 主要体现为算力不足 , 效率不高 。

文章图片
算力诚可贵:数据、算法需要更多算力支撑
众所周知 , 在人工智能发展的三要素中 , 无论是数据还是算法 , 都离不开算力的支撑 , 算力已成为人工智能发展的关键要素 。
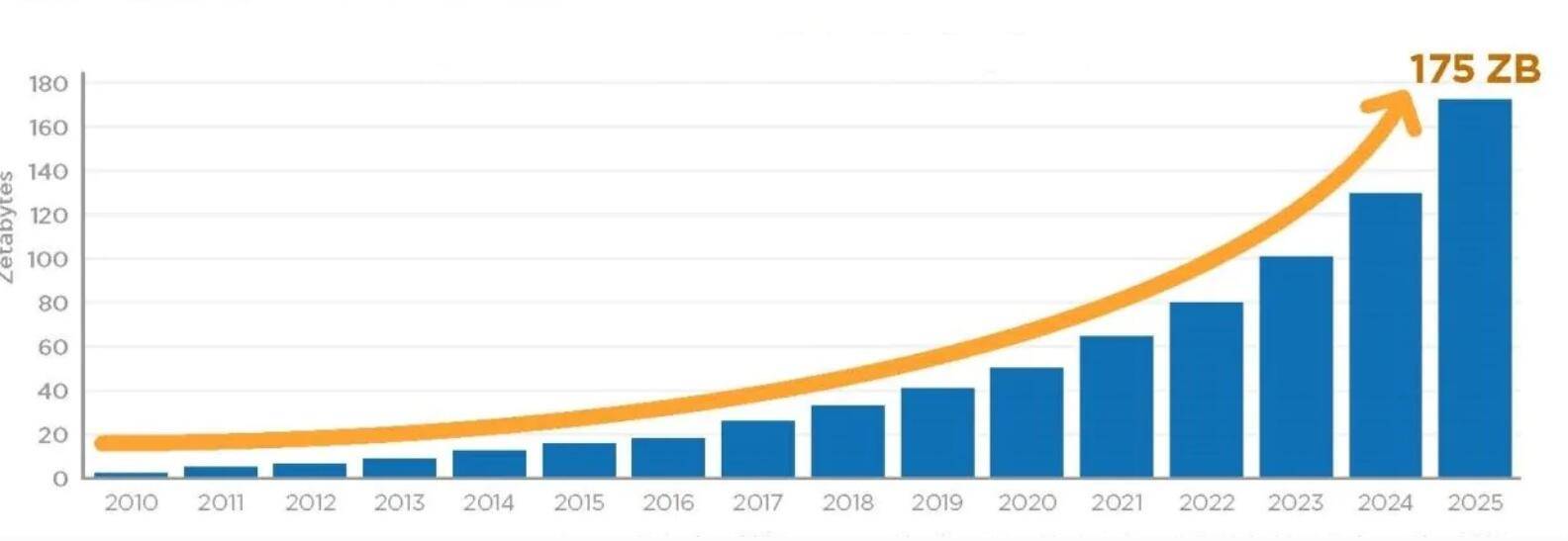
IDC发布的《数据时代2025》报告显示 , 2018年全球产生的数据量为33ZB (1ZB=1万亿GB) , 到2025年将增长到175ZB , 其中 , 中国将在2025年以48.6ZB的数据量及27.8%的占比成为全球最大的数据汇集地 。
文章图片
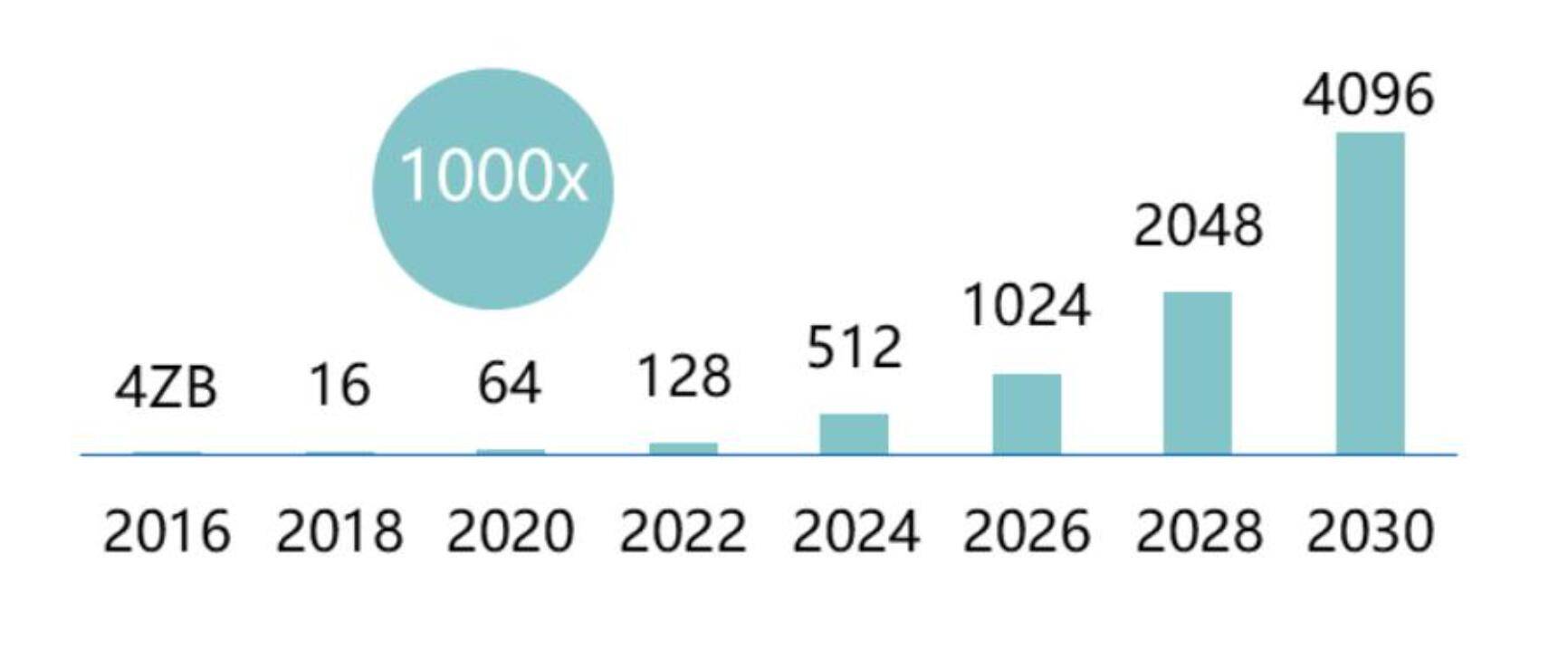
另据赛迪顾问数据显示 , 到2030年数据原生产业规模量占整体经济总量的15% , 中国数据总量将超过4YB , 占全球数据量30% 。 数据资源已成为关键生产要素 , 更多的产业通过利用物联网、工业互联网、电商等结构或非结构化数据资源来提取有价值信息 , 而海量数据的处理与分析对于算力的需求将十分庞大 。
文章图片
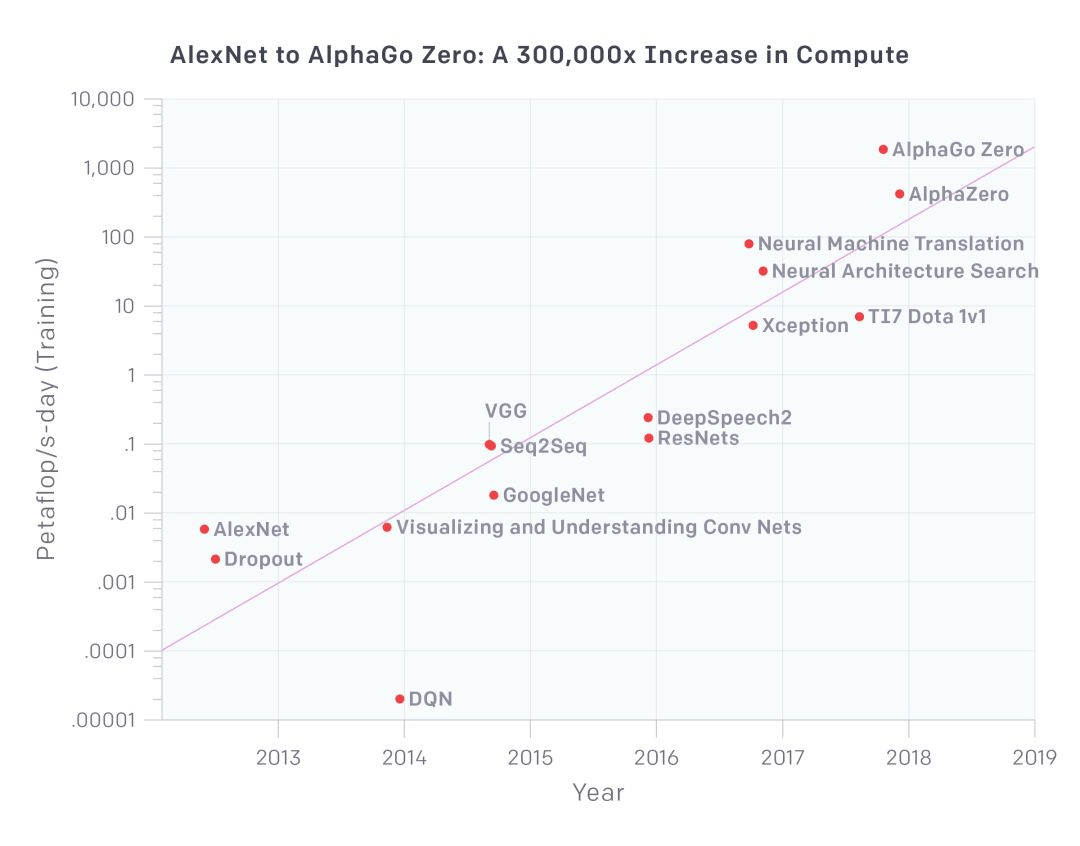
算法上 , 先进模型的参数量和复杂程度正呈现指数级的增长趋势 。 此前 Open AI 发表的一项研究就显示 , 每三到四个月 , 训练这些大型模型所需的计算资源就会翻一番(相比之下 , 摩尔定律有 18 个月的倍增周期) 。 2012 至 2018 年间 , 深度学习前沿研究所需的计算资源更是增加了 30 万倍 。
文章图片
到2020年 , 深度学习模型对算力的需求达到了每天百亿亿次的计算需求 。 2020年2月 , 微软发布了最新的智能感知计算模型Turing-NLG , 参数量高达到175亿 , 使用125POPS AI计算力完成单次训练就需要一天以上 。 随后 , OpenAI又提出了GPT-3模型 , 参数量更达到1750亿 , 对算力的消耗达到3640 PetaFLOPS/s-day 。 而距离GPT-3问世不到一年 , 更大更复杂的语言模型 , 即超过一万亿参数的语言模型SwitchTransformer即已问世 。
由此可见 , 高速增长的海量数据与更加复杂的模型 , 正在给算力带来更大的挑战 。 如果算力不能快速增长 , 我们将不得不面临一个糟糕的局面:当规模庞大的数据用于人工智能的训练学习时 , 数据量将超出内存和处理器的承载上限 , 整个深度学习训练过程将变得无比漫长 , 甚至完全无法实现最基本的人工智能 。
效率价更高:环境与实际成本高企 , 提升效率迫在眉睫
在计算工业行业 , 有个假设是“数字处理会变得越来越便宜” 。 但斯坦福人工智能研究所副所长克里斯托弗?曼宁表示 , 对于现有的AI应用来说却不是这样 , 特别是因为不断增加的研究复杂性和竞争性 , 使得最前沿模型的训练成本还在不断上升 。
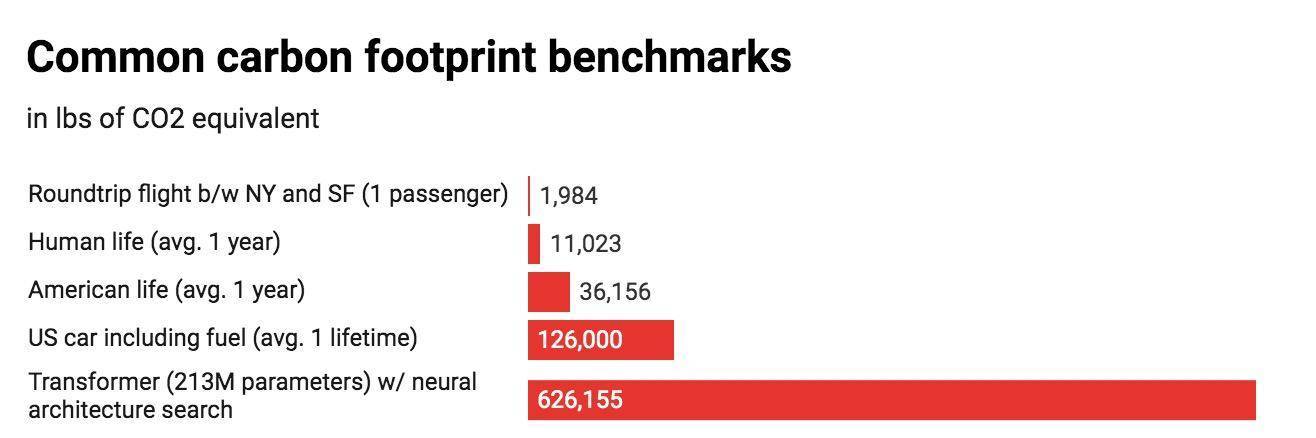
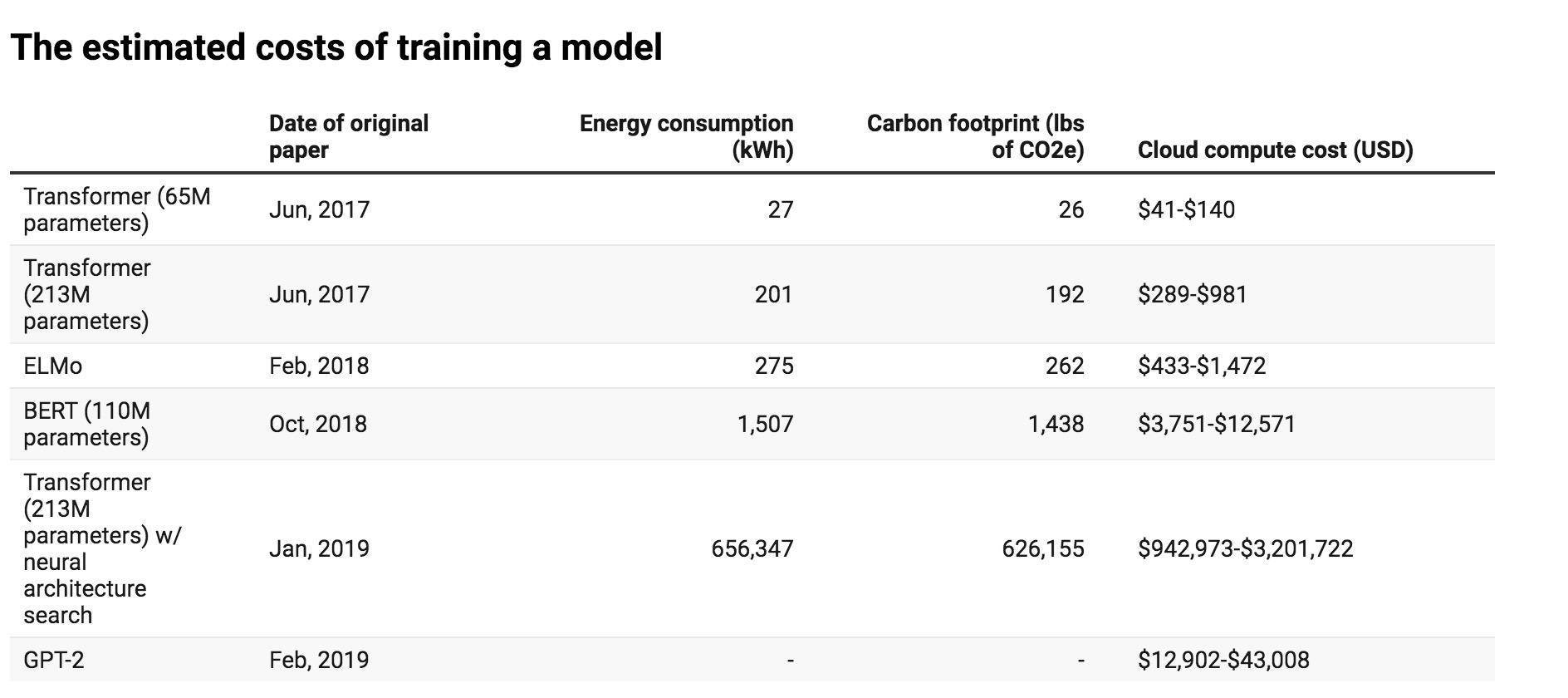
根据马萨诸塞大学阿默斯特校区研究人员公布的研究论文显示 , 以常见的几种大型 AI 模型的训练周期为例 , 发现该过程可排放超过 626000 磅二氧化碳 , 几乎是普通汽车寿命周期排放量的五倍(其中包括汽车本身的制造过程) 。
文章图片
例如自然语言处理中 , 研究人员研究了该领域中性能取得最大进步的四种模型:Transformer、ELMo、BERT和 GPT-2 。 研究人员在单个 GPU 上训练了至少一天 , 以测量其功耗 。 然后 , 使用模型原始论文中列出的几项指标来计算整个过程消耗的总能量 。
结果显示 , 训练的计算环境成本与模型大小成正比 , 然后在使用附加的调整步骤以提高模型的最终精度时呈爆炸式增长 , 尤其是调整神经网络体系结构以尽可能完成详尽的试验 , 并优化模型的过程 , 相关成本非常高 , 几乎没有性能收益 。 BERT 模型的碳足迹约为1400 磅二氧化碳 , 这与一个人来回坐飞机穿越美洲的排放量相当 。
文章图片
此外 , 研究人员指出 , 这些数字仅仅是基础 , 因为培训单一模型所需要的工作还是比较少的 , 大部分研究人员实践中会从头开发新模型或者为现有模型更改数据集 , 这都需要更多时间培训和调整 , 换言之 , 这会产生更高的能耗 。 根据测算 , 构建和测试最终具有价值的模型至少需要在六个月的时间内训练 4789 个模型 , 换算成碳排放量 , 超过 78000 磅 。 而随着 AI 算力的提升 , 这一问题会更加严重 。
另据 Synced 最近的一份报告 , 华盛顿大学的 Grover 专门用于生成和检测虚假新闻 , 训练较大的Grover Mega模型的总费用为2.5万美元;OpenAI 花费了1200万美元来训练它的 GPT-3语言模型;谷歌花费了大约6912美元来训练 BERT , 而Facebook针对当前最大的模型进行一轮训练光是电费可能就耗费数百万美元 。
对此 , Facebook人工智能副总裁杰罗姆?佩森蒂在接受《连线》杂志采访时认为 , AI科研成本的持续上涨 , 或导致我们在该领域的研究碰壁 , 现在已经到了一个需要从成本效益等方面考虑的地步 , 我们需要清楚如何从现有的计算力中获得最大的收益 。
在我们看来 , AI计算系统正在面临计算平台优化设计、复杂异构环境下计算效率、计算框架的高度并行与扩展、AI应用计算性能等挑战 。 算力的发展对整个计算需求所造成的挑战会变得更大 , 提高整个AI计算系统的效率迫在眉睫 。
最优解:智算中心大势所趋 , 应从国家公共设施属性做起
正是基于上述算力需求不断增加及所面临的效率提升的需要 , 作为建设承载巨大AI计算需求的算力中心(数据中心)成为重中之重 。
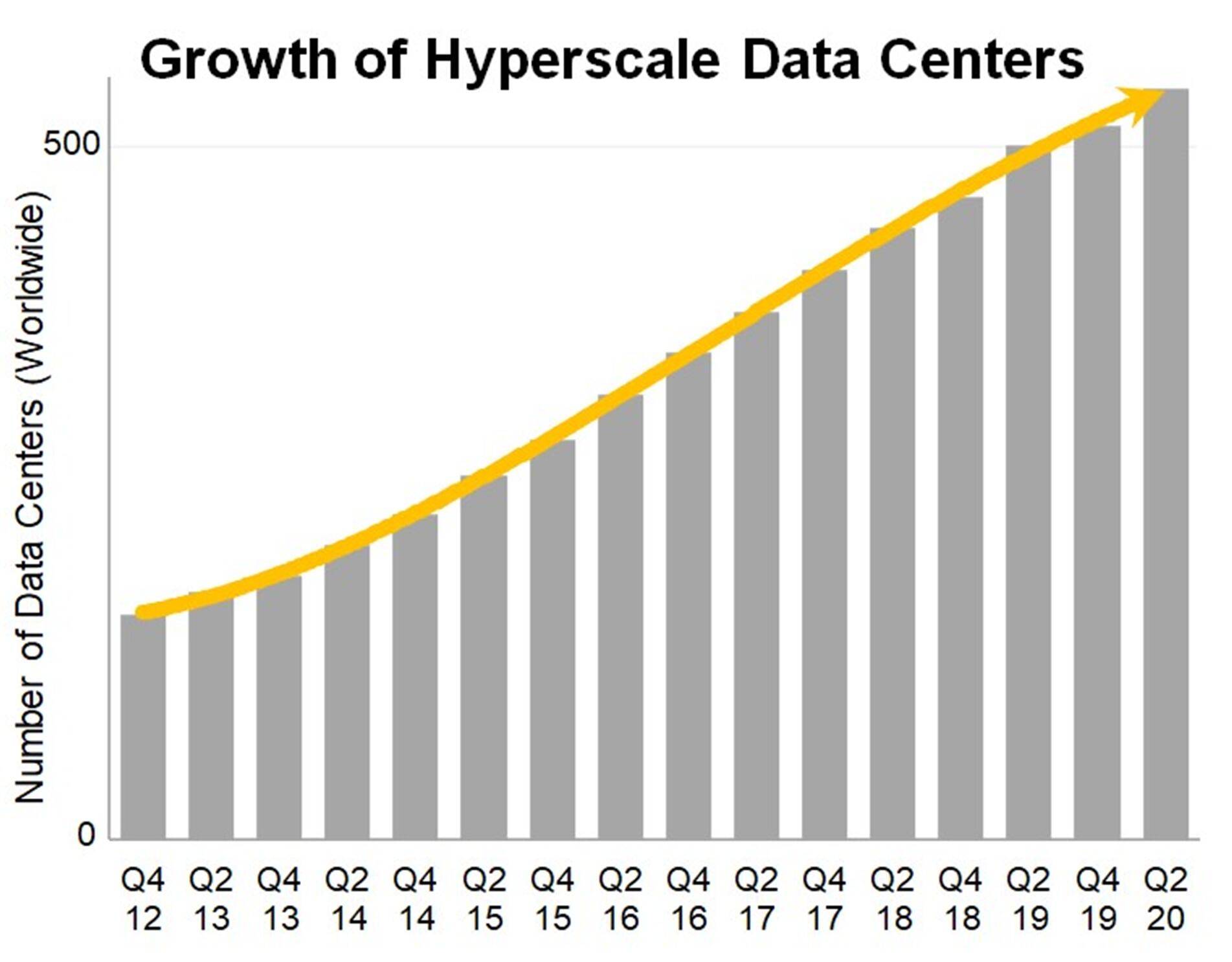
据市场调研机构Synergy Research Group的数据显示 , 截至到2020年第二季度末 , 全球超大规模数据中心的数量增长至541个 , 相比2015年同期增长一倍有余 。 另外 , 还有176个数据中心处于计划或建设阶段 , 但作为传统的数据中心 , 随之而来的就是能耗和成本的大幅增加 。
文章图片
【模型|算力可贵,效率价高:智算中心凭啥是筑基新基建的最优解?】这里我们仅以国内的数据中心建设为例 , 现在的数据中心已经有了惊人的耗电量 。 据《中国数据中心能耗现状白皮书》显示 , 在中国有 40 万个数据中心 , 每个数据中心平均耗电 25 万度 , 总体超过 1000 亿度 , 这相当于三峡和葛洲坝水电站 1 年发电量的总和 。 如果折算成碳排放则大概是 9600 万吨 , 这个数字接近目前中国民航年碳排放量的 3 倍 。
但根据国家的标准 , 到2022年 , 数据中心平均能耗基本达到国际先进水平 , 新建大型、超大型数据中心的 PUE(电能使用效率值 , 越低代表越节能)达到 1.4 以下 。 而且北上广深等发达地区对于能耗指标控制还非常严格 , 这与一二线城市集中的数据中心需求形成矛盾 , 除了降低 PUE , 同等计算能力提升服务器 , 尤其是数据中心的的计算效率应是正解 。
但众所周知的事实是 , 面对前述庞大的AI计算需求和提升效率的挑战 , 传统数据中心已经越来越难以承载这样的需求 , 为此 , AI服务器和智算中心应运而生 。
与传统的服务器采用单一的CPU不同 , AI服务器通常搭载GPU、FPGA、ASIC等加速芯片 , 利用CPU与加速芯片的组合可以满足高吞吐量互联的需求 , 为自然语言处理、计算机视觉、语音交互等人工智能应用场景提供强大的算力支持 , 已经成为人工智能发展的重要支撑力量 。
值得一提的是 , 目前在AI服务器领域 , 我们已经处于领先的地位 。
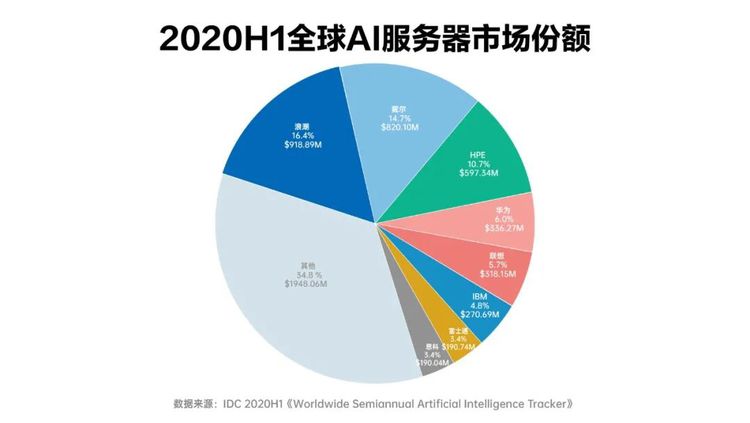
近日 , IDC发布了2020HI《全球人工智能市场半年度追踪报告》 , 对2020年上半年全球人工智能服务器市场进行数据洞察显示 , 目前全球半年度人工智能服务器市场规模达55.9亿美元(约326.6亿人民币) , 其中浪潮以16.4%的市占率位居全球第一 , 成为全球AI服务器头号玩家 , 华为、联想也杀入前5(分别排在第四和第五) 。
这里业内也许会好奇 , 缘何中国会在AI服务器方面领跑全球?
文章图片
以浪潮为例 , 自1993年 , 浪潮成功研制出中国首台小型机服务器以来 , 经过30年的积累 , 浪潮已经攻克了高速互联芯片 , 关键应用主机、核心数据库、云数据中心操作系统等一系列核心技术 , 在全球服务器高端俱乐部里占有了重要一席 。 在AI服务器领域 , 从全球最高密度AGX-2到最高性能的AGX-5 , 浪潮不断刷新业界最强的人工智能超级服务器的纪录 , 这是为了满足行业用户对人工智能计算的高性能要求而创造的 。 浪潮一直认为 , 行业客户希望获得人工智能的能力 , 但需要掌握了人工智能落地能力的和技术的公司进行赋能 , 浪潮就可以很好地扮演这一角色 。 加快人工智能落地速度 , 帮助企业用户打开了人工智能应用的大门 。
由此看 , 长期的技术创新积淀、核心技术的掌握以及对于产业和技术的准确判断、研发是领跑的根本 。
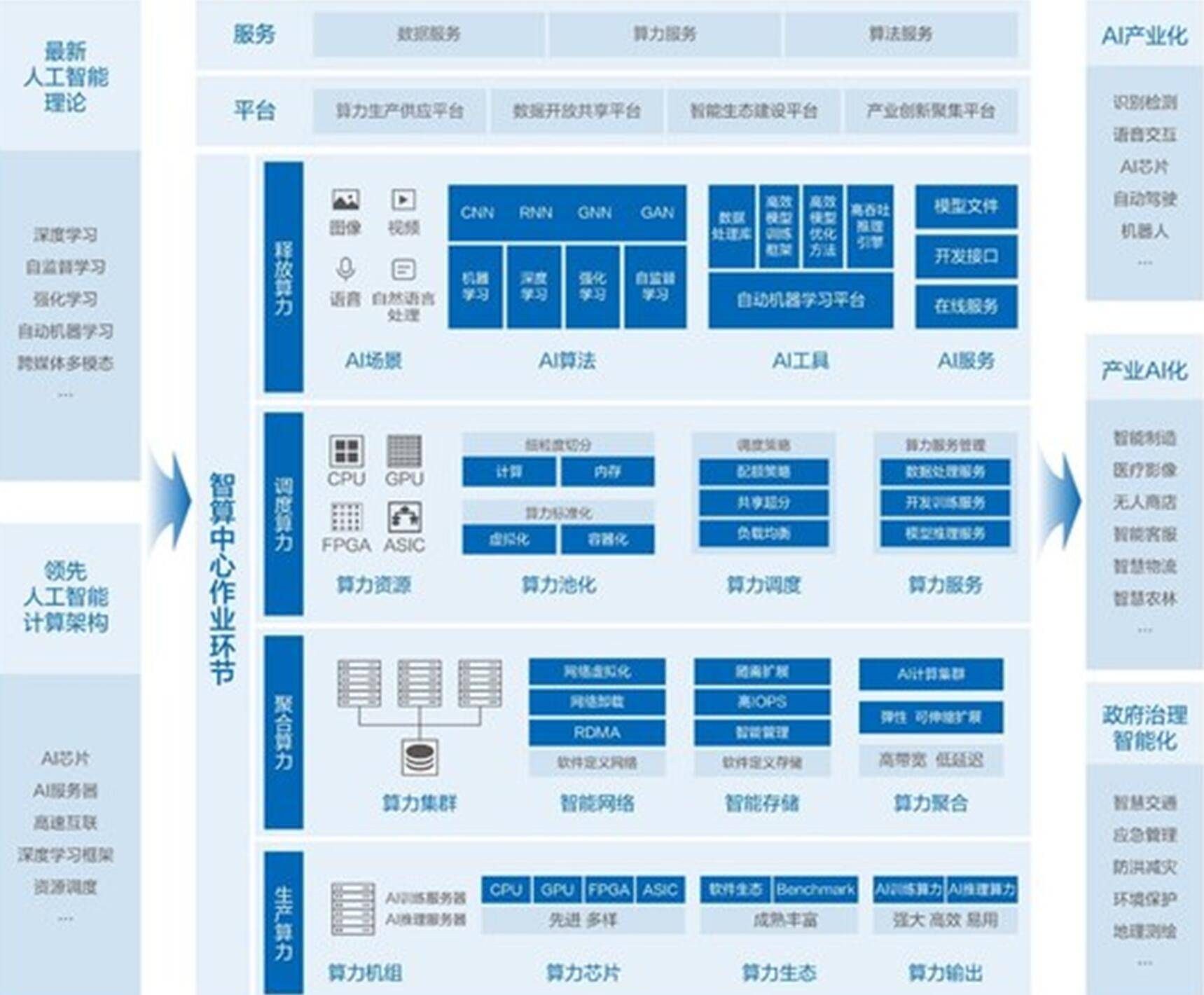
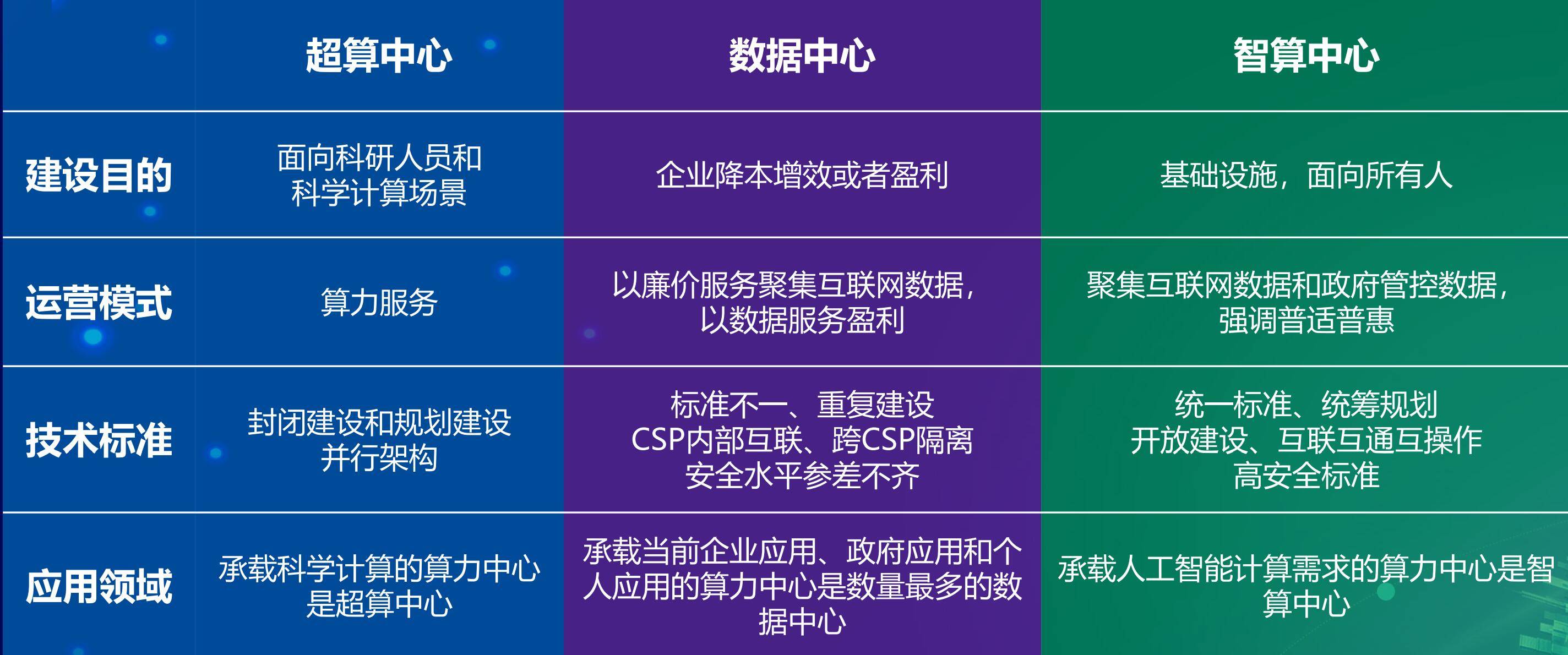
至于智算中心 , 去年发布的《智能计算中心规划建设指南》公布了智能计算中心技术架构 , 基于最新人工智能理论 , 采用领先的人工智能计算架构 , 通过算力的生产、聚合、调度和释放四大作业环节 , 支撑和引领数字经济、智能产业、智慧城市和智慧社会应用与生态健康发展 。
文章图片
通俗地讲 , 智慧时代的智算中心就像工业时代的电厂一样 , 电厂是对外生产电力、配置电力、输送电力、使用电力;同理智算中心是在承载AI算力的生产、聚合、调度和释放过程 , 让数据进去让智慧出来 , 这就是智能计算中心的理想目标 。
需要说明的是 , 与传统数据中心不同 , “智算中心”不仅把算力高密度地集中在一起 , 而且要解决调度和有效利用计算资源、数据、算法等问题 , 更像是从计算器进化到了大脑 。 此外 , 其所具有的开放标准 , 集约高效、普适普惠的特征 , 不仅能够涵盖融合更多的软硬件技术和产品 , 而且也极大降低了产业AI化的进入和应用门槛 , 直至普惠所有人 。
文章图片
其实我们只要仔细观察就会发现 , 智算中心包含的算力的生产、聚合、调度和释放 , 可谓集AI能力之大成 , 具备全栈AI能力 。
这里我们不妨再次以浪潮为例 , 看看何谓全栈AI能力?
比如在算力生产层面 , 浪潮打造了业内最强最全的AI计算产品阵列 。 其中 , 浪潮自研的新一代人工智能服务器NF5488A5在2020年一举打破MLPerf AI推理&训练基准测试19项世界纪录(保证充足的算力 , 解决了算力提升的需求);在算力调度层面 , 浪潮AIStation人工智能开发平台能够为AI模型开发训练与推理部署提供从底层资源到上层业务的全平台全流程管理支持 , 帮助企业提升资源使用率与开发效率90%以上 , 加快AI开发应用创新(解决了算力的效率问题);在聚合算力方面 , 浪潮持续打造更高效率更低延迟硬件加速设备与优化软件栈;在算力释放上 , 浪潮AutoML Suite为人工智能客户与开发者提供快速高效开发AI模型的能力 , 开启AI全自动建模新方式 , 加速产业化应用 。
那么接下来的是 , 智算中心该遵循怎样的发展路径才能充分发挥它的作用 , 物尽其用?
IDC调研发现 , 超过九成的企业正在使用或计划在三年内使用人工智能 , 其中74.5%的企业期望在未来可以采用具备公用设施意义的人工智能专用基础设施平台 , 以降低创新成本 , 提升算力资源的可获得性 。
由此看 , 智能计算中心建设的公共属性原则在当下和未来就显得尤为重要 , 即智能计算中心并非是盈利性的基础设施 , 而是应该是类似于水利系统、水务系统、电力系统的公共性、公益性的基础设施 , 其将承载智能化的居民生活服务、政务服务智能化 。 因此 , 在智能计算中心规划和建设过程中 , 要做好布局 , 它不应该通过市场竞争手段来实现 , 而要体现政府在推进整个社会智能化进程的规划、节奏、布局 。
总结:当下 , 算力成为推动数字经济的根基和我国“新基建“的底座已经成为共识 , 而如何理性看待其发展中遇到的挑战 , 在不断高升算力的前提下 , 提升效率 , 并采取最佳的发展策略和形式 , 找到最优解 , 将成为政府相关部门以及相关企业的重中之重 。
推荐阅读







- 模型|2022前展望大模型的未来,周志华、唐杰、杨红霞这些大咖怎么看?
- 模型|经逆向工程,Transformer「翻译」成数学框架 | 25位学者撰文
- 化纤|JXK STUDIO 虎年肥猫 1/6仿真动物模型手办可爱摆件
- 模型|达摩院2022十大科技趋势发布:人工智能将催生科研新范式
- 模型|李彦宏:中国迎来AI黄金十年,集度汽车机器人明年亮相,智能交通10年内解决拥堵
- 模型|神经辐射场去掉「神经」,训练速度提升100多倍,3D效果质量不减
- 模型|英伟达:美团机器学习平台使用NVIDIA T4 GPU
- 建设|运营商集体发力“算力网络”,联通四步迈向 “算网一体”
- 错误|有了这个工具,不执行代码就可以找PyTorch模型错误
- 能源|当IDC遇上元宇宙,先解决能源、算力、数字化这三个问题