编辑:小舟
「作为数据科学家 , 我还有机会吗?」不 , 你更应该成为数据工程师 。

文章图片
数据无处不在 , 而且只会越来越多 。 在过去的 5-10 年内 , 数据科学已经吸引了越来越多的新人投身于此 。
但如今数据科学的招聘状况如何?亚马逊 Alxea 团队的机器学习科学家 Mihail Eric 收集了多家公司的招聘信息后 , 在个人博客中撰写了一篇分析文章 , 阐述自己的思考 。
数据胜于雄辩 , 他对自 2012 年以来 Y-Combinator 孵化的每家公司发布的数据领域职位进行了分析 , 研究问题包括:
在数据领域 , 公司最常招聘的职位是什么?
人们常讨论的数据科学家的需求究竟有多大?
公司看重的这些技能是引发当今数据革命的技能吗?
以下是博客文章的主要内容:
【职位|抓取1400家公司的招聘信息,发现数据工程师比数据科学家更有市场】方法
我选择对 YC 风投公司进行分析 , 这些公司声称将某种数据作为其价值主张的一部分 。
主要关注 YC 是因为其提供了易于搜索(可抓取)的公司目录 。 此外 , 作为一个特别有远见的孵化器 , 它已经为全球众多领域的公司提供投资长达十年之久 , 我觉得他们为本次分析研究提供了一个具有代表性的市场样本 。 但请注意 , 我没有分析超大型科技公司 。
我抓取了自 2012 年以来每家 YC 公司的首页网址 , 建立起一个包含 1400 家公司的初始池 。
为什么是从 2012 年开始呢?2012 年 , AlexNet 在 ImageNet 竞赛中获奖 , 掀起了如今机器学习和数据建模的热潮 , 最早的一批数据优先(data-first)公司由此诞生 。
我对初始池执行了关键词过滤 , 以减少需要浏览的公司量 。 具体而言 , 我只考虑了其网站至少包含以下术语之一的公司:AI、CV、NLP、自然语言处理、计算机视觉、人工智能、机器、ML、数据 。 同时不考虑那些网站链接故障的公司 。
这样的操作应该会产生大量错误的结果 , 我意识到将对各个网站进行更细粒度的手动检查以了解相关角色 , 因此我尽可能地优先考虑高召回率 。
在这个筛选过的资源池中 , 我遍历了每个网站 , 找到了他们发布招聘信息的位置 , 并记下了标题中包含数据、机器学习、NLP 或 CV 的所有职位 。 这让我建立了一个来自大约 70 个不同公司的招聘职位的资源池 。
也有点小失误:其中我错过了一些公司 , 有些网站虽然招聘信息很少 , 但是其实正在招聘 。 此外 , 有些公司没有正式的招聘页面 , 但而是要求应聘者直接通过电子邮件与他们联系 。 我忽略了这两种类型的公司 , 它们不在本次分析研究中 。
另一件事是 , 这项研究的大部分都是在 2020 年的最后几个星期内完成的 。 随着公司定期更新招聘页面 , 开放的职位可能已经改变 , 但我认为这对得出的结论影响不大 。
数据从业者应该负责什么?
在深入研究结果之前 , 值得花一些时间来搞清楚每种数据领域职位通常负责什么 。 我将花时间介绍以下四个职位:
数据科学家负责在统计和机器学习中使用各种技术来处理和分析数据 , 通常负责构建模型以探究从某些数据源中能够学到的内容 , 但模型通常是原型级别而非生产级别;
数据工程师负责开发一套强大且可扩展的数据处理工具 / 平台 , 必须熟悉 SQL / NoSQL 数据库的整理和构建 / 维护 ETL 流水线;
机器学习(ML)工程师通常既负责训练模型 , 又负责生产模型 , 他们需要熟悉一些高级 ML 框架 , 还必须能够轻松构建模型的可扩展训练 , 推理和部署流水线;
机器学习(ML)科学家致力于前沿研究 , 他们通常负责探索可以在学术会议上发表的新想法 。 在移交给 ML 工程师进行生产之前 , 机器学习科学家通常只需要对新的 SOTA 模型进行原型制作 。
值得一提的是 , 与传统数据科学家相比 , 开放数据工程师的职位增加了不少 , 在这种情况下 , 在公司雇用的原始量上 , 数据工程师比数据科学家多了大约 55% , 而机器学习工程师的数量与数据科学家的数量大致相同 。 但如果查看各个职位的名称 , 就会发现似乎有些重复 。
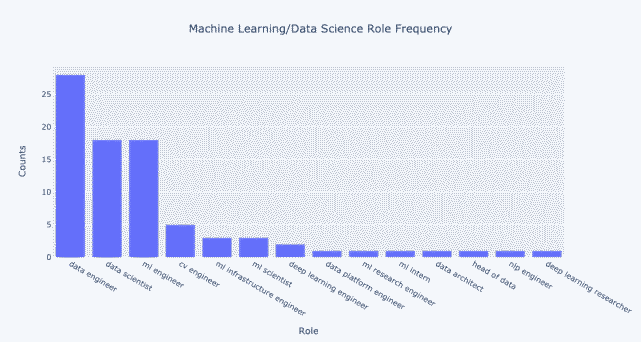
文章图片
我只通过合并职位来提供粗略的分类即在不同职位角色负责的内容大致相同的情况下将其合并为一个名称 。 其中包括以下等价关系集:
NLP 工程师≈CV 工程师≈ML 工程师≈深度学习工程师(尽管领域可能不同 , 但职责大致相同)
ML 科学家≈深度学习≈ML 实习生
数据工程师≈数据架构师≈数据主管≈数据平台工程师
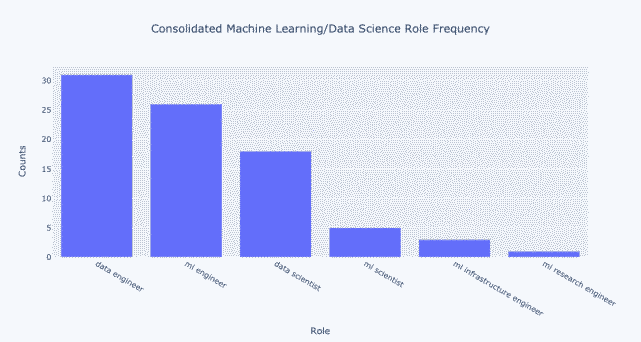
文章图片
按百分比描述的话是:
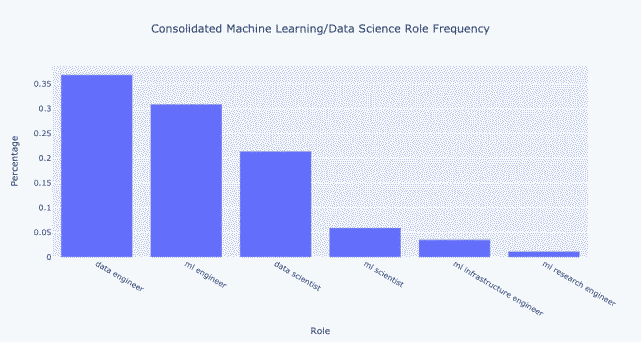
文章图片
总体而言 , 合并会使差异更加明显 。 开放数据工程师比数据科学家多大约 70% 。 此外 , 开放 ML 工程师比数据科学家多大约 40% 。 机器学习科学家的数量也只有数据科学家的大约 30% 。
结论
与其他数据驱动型职位相比 , 数据工程师的需求越来越高 。 从某种意义上说 , 这代表了该方向正朝着更广阔的领域发展 。
5 到 8 年前 , 机器学习变得炙手可热 , 各个公司需要的是能够对数据进行分类的人才 。 但是之后 Tensorflow 和 PyTorch 等框架发展得很好 , 使得着手开始进行深度学习和机器学习的能力大众化 , 随之而来的是数据建模技能商品化 。 如今 , 发展瓶颈在于帮助公司获得有关生产级别数据问题的机器学习和建模的意见 。 比如要考虑以下问题:
如何注释数据?
如何处理和清理数据?
如何将其从 A 移到 B?
如何尽快完成这些任务?

文章图片
所有的这些都意味着 , 职位要求具有良好的工程技能 , 偏向于数据的传统软件工程可能是我们目前真正需要的 。 但是否意味着您不应该学习数据科学?并不是 。 而是意味着竞争将更加艰难 。 对于正准备训练成为数据科学人才的初学者来说 , 可用的职位将会越来越少 。 当然 , 有效地分析数据并从数据中提取可行见解的人一直需要 , 但这些见解必须是优秀的 。
很明显 , 公司经常需要混合型数据从业者 , 即可以构建和部署模型的人 。 或者更简洁地说 , 可以使用 Tensorflow , 但也可以从源代码构建它的人 。
本研究的另一个发现是 ML 研究职位非常少 。 机器学习研究倾向于获得相当大的资源支持 , 因为这是顶尖级的研究 , 例如 AlphaGo 和 GPT-3 。 但是对于许多公司 , 尤其是早期公司而言 , 顶尖的 SOTA 技术可能不再是必需的 。 达到最佳模型性能的 90% , 同时扩展到 1000 个以上的用户 , 通常对他们来说更有价值 。
但你可能会在工业界的研究实验室里找到很多这样的角色 , 他们可以在很长一段时间里承受资本密集型赌注 , 而不是在种子轮就开始做产业 demo 准备接 A 轮融资 。
如果没有其他问题 , 我认为最重要的是让新来者对数据字段的期望合理并经过校准 。 我们必须承认 , 数据科学现在已经今非昔比 , 只有当我们知道自己身处何处时 , 我们才知道要去到哪里 。
推荐阅读








- Intel|Intel宣布职场多元化战略:2030年女性将占技术职位40%
- 月薪|盘点工程人各岗位薪资收入,哪个职位收入最高?
- 社交|Facebook改名为Meta 扎克伯格不放弃最高职位
- C-level|人工智能相关职位数较年初增加50%
- Tesla|特斯拉已开始为弗里蒙特工厂的4680电池试点产线增加招聘职位
- iphone|CNBC:苹果iPhone系统安全漏洞被攻破 有可能用于情报机构抓取信息
- 大族|1400家知名企业秀新技术,广东工博会9月23日佛山开幕
- 通信运营商|美国通信巨头AT&T与工会握手言和:同意保护好29000个技术职位
- Tesla|特斯拉人形机器人项目再进一步 已开启相关职位招聘
- Tesla|马斯克的通用人形机器人招来群嘲 学者:先像人手一样抓取吧