选自arXiv
作者:Hieu Pham、Quoc Le等
机器之心编译
机器之心编辑部
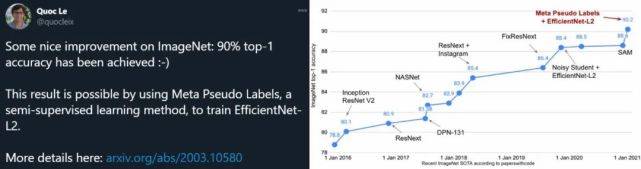
Quoc Le:我原本以为 ImageNet 的 top-1 准确率 85% 就到头了 , 现在看来 , 这个上限难以预测 。近日 , 谷歌大脑研究科学家、AutoML 鼻祖 Quoc Le 发文表示 , 他们提出了一种新的半监督学习方法 , 可以将模型在 ImageNet 上的 top-1 准确率提升到 90.2% , 与之前的 SOTA 相比实现了 1.6% 的性能提升 。
文章图片
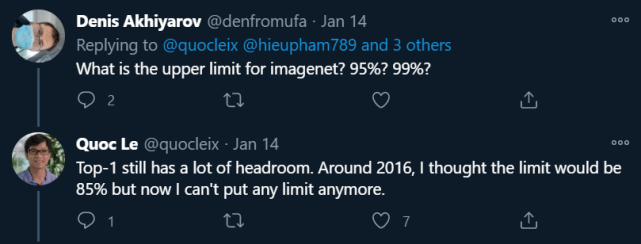
这一成果刷新了 Quoc Le 对于 ImageNet 的看法 。 2016 年左右 , 他认为深度学习模型在 ImageNet 上的 top-1 准确率上限是 85% , 但随着这一数字被多个模型不断刷新 , Quoc Le 也开始对该领域的最新研究抱有更多期待 。 而此次 90.2% 的新纪录更是让他相信:ImageNet 的 top-1 还有很大空间 。
文章图片
Quoc Le 介绍称 , 为了实现这一结果 , 他们使用了一种名为「元伪标签(Meta Pseudo Label)」的半监督学习方法来训练 EfficientNet-L2 。
和伪标签(Pseudo Label)方法类似 , 元伪标签方法有一个用来在未标注数据上生成伪标签并教授学生网络的教师网络 。 然而 , 与教师网络固定的伪标签方法相比 , 元伪标签方法有一个从学生网络到教师网络的反馈循环 , 其教师网络可以根据学生网络在标记数据集上的表现进行调整 , 即教师和学生同时接受训练 , 并在这一过程中互相教授 。

文章图片
这篇有关元伪标签的论文最早提交于 2020 年 3 月 , 最近又放出了最新版本 。
【Quoc|ImageNet的top-1上了90%,用额外数据集还不公开,让人怎么信服?】

文章图片
论文链接:https://arxiv.org/pdf/2003.10580.pdf
代码链接:https://github.com/google-research/google-research/tree/master/meta_pseudo_labels
在新版本中 , 研究者针对元伪标签方法进行了实验 , 用 ImageNet 数据集作为标记数据 , JFT-300M 作为未标记数据 。 他们利用元伪标签方法训练了一对 EfficientNet-L2 网络 , 其中一个作为教师网络 , 另一个作为学生网络 。 最终 , 他们得到的学生模型在 ImageNet ILSVRC 2012 验证集上实现了 90.2% 的 top-1 准确率 , 比之前的 SOTA 方法提升了 1.6 个百分点(此前 ImageNet 上 top-1 的 SOTA 是由谷歌提出的 EfficientNet-L2-NoisyStudent + SAM(88.6%)和 ViT(88.55%)) 。 这个学生模型还可以泛化至 ImageNet-ReaL 测试集 , 如下表 1 所示 。

文章图片
在 CIFAR10-4K、SVHN-1K 和 ImageNet-10% 上使用标准 ResNet 模型进行的小规模半监督学习实验也表明 , 元伪标签方法的性能优于最近提出的一系列其他方法 , 如 FixMatch 和无监督数据增强 。
论文作者还表示 , 他们之所以在方法的命名中采用「meta」这个词 , 是因为他们让教师网络根据学生网络反馈进行更新的方法是基于双层优化问题(bi-level optimization problem) , 而该问题经常出现在元学习的相关文献中 。
不过 , 这篇论文也受到了一些质疑 , 比如使用的数据集 JFT-300M 是未开源的数据集(不知道该数据集中有没有和 ImageNet 测试集相似的图片) , 导致外部人士很难判断其真正的含金量 。
为什么要改进「伪标签」方法?
伪标签或自训练方法已经成功地应用于许多计算机视觉任务 , 如图像分类、目标检测、语义分割等 。 伪标签方法有一对网络:一个教师网络 , 一个学生网络 。 教师网络基于无标签图像生成伪标签 , 这些被「伪标注」的图像与标注图像结合 , 用来训练学生网络 。 由于使用了大量的伪标签数据和数据增强等正则化方法 , 学生网络通过学习可以超越教师网络 。
尽管伪标签方法性能优越 , 但它也有一个很大的缺陷:如果伪标签不准确 , 学生网络就要从不准确的数据中学习 。 因此 , 最后训练出的学生网络未必比教师网络强多少 。 这一缺陷也被称为伪标记的确认偏差(confirmation bias)问题 。
为了解决这一问题 , Quoc Le 等人设计了系统的机制 , 让教师网络通过观察其伪标签对学生网络的影响来纠正上述偏差 。 确切地说 , 他们提出了元伪标签方法 , 利用来自学生网络的反馈为教师网络提供信息 , 促使其生成更好的伪标签 。 反馈信号是学生网络在标记数据上的表现 。 在学生网络的学习过程中 , 该反馈信号被用作训练教师网络的一种奖励 。
怎么改进「伪标签」方法
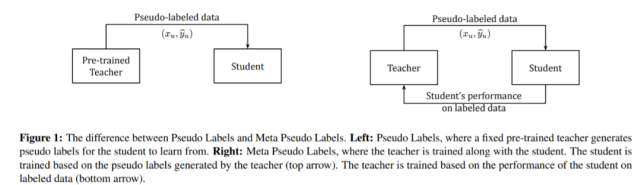
伪标签方法和元伪标签方法的区别如下图 1 所示 。 可以看出 , 元伪标签方法多了一个关于学生网络表现的反馈 。
文章图片
符号解释
在论文中 , T 和 S 分别表示教师网络和学生网络 , 它们的参数分别记为θ_T 和 θ_S 。 用 (x_l , y_l) 表示一批图像和图像对应的标签 , x_u 表示一批未标记数据 。 此外 , T(x_u; θ_T )表示教师网络对于 x_u 的软预测(soft predictions) , 学生网络同理 。 CE(q, p)表示 q 和 p 两个分布之间的交叉熵损失 。 如果 q 是一个标签 , 它会被理解为一个 one-hot 分布;如果 q 和 p 有多个实例 , 那么 CE(q, p)就是 batch 中所有实例的平均 。
把伪标签看成一个优化问题
在介绍元伪标签之前 , 先来回顾一下伪标签 。 具体来说 , 伪标签(PL)方法会训练学生模型来最小化其在未标记数据上的交叉熵损失:
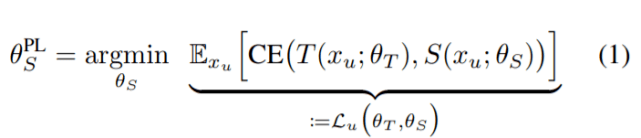
文章图片
在上面的公式中 , 伪目标 T(x_u; θ_T )由一个训练良好、参数θ_T 固定的教师模型生成 。 给定一个优秀的教师模型 , 伪标签方法的愿景是让最终得到的

文章图片
在未标记数据上损失很低 , 即
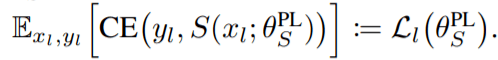
文章图片
在伪标签的框架下 , 最优学生参数

文章图片
总是通过伪目标
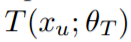
文章图片
依赖于教师参数θ_T 。 为了便于讨论元伪标签 , 我们可以将该依赖表示为
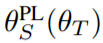
文章图片
。
作为一个即时的观察 , 学生网络在标记数据上的最终损失
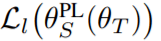
文章图片
也是θ_T 的「函数」 。 因此 , 我们可以进一步优化与θ_T 相关的 L_1
文章图片
直观上来看 , 根据学生网络在标记数据上的表现优化教师网络参数之后 , 我们就能对伪标签作出相应调整 , 从而提高学生网络的性能 。 但需要注意的是 ,
文章图片
在θ_T 上的依赖非常复杂 , 因此计算梯度

文章图片
需要展开整个学生网络训练过程(即
文章图片
) 。
实际近似
为了让元伪标签方法变得可行 , 研究者借用了前人在元学习方面的一些工作 , 利用θ_S 的一步梯度更新近似多步
文章图片
,
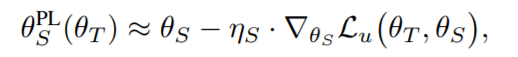
文章图片
其中 , η_S 是学习率 。 将这个近似代入式(2)的优化问题中 , 就得到了元伪标签中的实际教师网络目标:
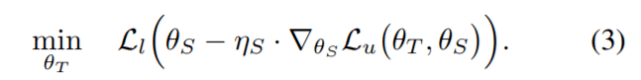
文章图片
注意 , 如果软伪标签得到了应用 , 即 T(x_u; θ_T )是教师网络预测出的完整分布(full distribution) , 上述目标就是关于θ_T 完全可微的(fully differentiable) , 我们就能通过标准反向传播得到梯度 。 然而 , 在这篇论文中 , 研究者从教师网络分布中采样硬伪标签 。 因此 , 他们用了一个略作修改的 REINFORCE 版本来得到式(3)中 L_1 关于θ_T 的梯度 。
另一方面 , 学生网络的训练还依赖于式(1)中的目标 , 只是教师网络的参数不再是固定的 。 相反 , 由于教师网络的优化 , θ_T 一直在发生变化 。 更加有趣的是 , 学生网络参数的更新可以在教师网络目标的一步近似中重用 , 这自然会在学生网络更新和教师网络更新之间产生一个交替的优化过程 。
学生网络:吸收一批未标记数据 x_u , 然后从教师网络的预测中采样 T(x_u; θ_T ) , 接下来用 SGD 优化目标 1
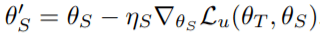
文章图片
教师网络:吸收一批标记数据(x_l , y_l) , 「重用」学生网络的更新 , 从而用 SGD 优化目标 3:
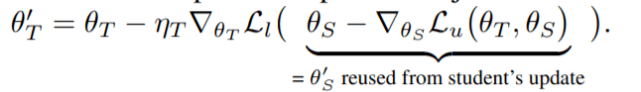
文章图片
教师网络的辅助损失(auxiliary losses)
通过实验 , 研究者发现 , 元伪标签方法自己就能运行良好 。 当然 , 如果教师网络与其他辅助目标(auxiliary objective)联合训练 , 效果会更好 。 因此 , 在实现过程中 , 研究者用一个监督学习目标和一个半监督学习目标增强了教师网络的训练 。 对于监督学习目标 , 他们在标记数据上训练教师网络 。 对于半监督学习目标 , 他们使用 UDA 在未标记数据上训练教师网络 。
最后 , 由于元伪标签方法中的学生网络只从带有伪标签的未标记数据中学习 , 我们可以在学生网络训练至收敛后借助标记数据对其进行微调 , 以提高其准略率 。
实验结果
小规模实验
这部分展示了小规模实验的结果 。 首先 , 研究者借助简单的 TwoMoon 数据集测了一下「反馈」在元伪标签方法中的重要性 , 结果如下图 2 所示 。 从中可以看出 , 在 TwoMoon 数据集上 , 元伪标签方法(右)比监督学习方法(左)和伪标签方法(中)的表现都要好 。

文章图片
接下来 , 他们又将元伪标签方法与之前的 SOTA 半监督学习方法进行了对比 , 使用的基准包括 CIFAR-10-4K、SVHN-1K、ImageNet-10% 等 , 结果如下表 2 所示:
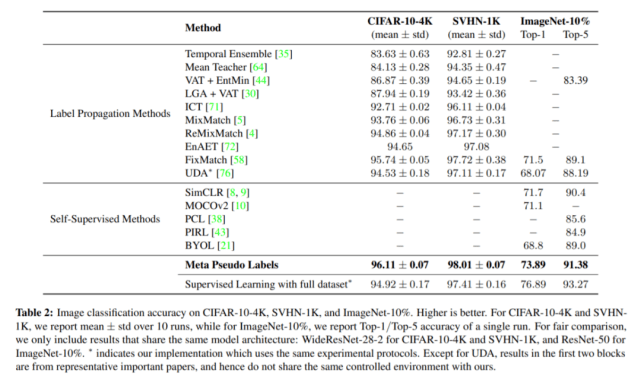
文章图片
最后 , 他们使用完整的 ImageNet 数据集在标准的 ResNet-50 架构上进行了实验 , 结果如下表3所示:
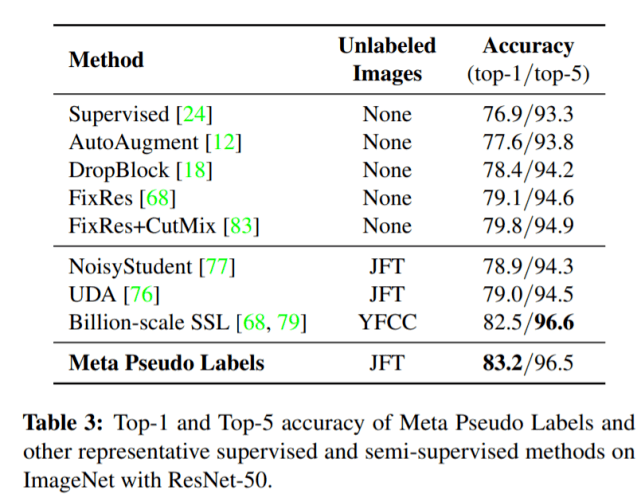
文章图片
大规模实验
这部分展示了大规模实验(大模型、大数据集)的结果 。 研究者使用了 EfficientNet-L2 架构 , 因为该架构的容量比 ResNet 大 。 Noisy Student 也用到了 EfficientNet-L2 , 在 ImageNet 上达到了 88.4% 的 top-1 准确率 。
这部分的实验结果如下表 4 所示 。 从中可以看出 , 元伪标签方法以 90.2% 的准确率成为了 ImageNet top-1 的新 SOTA 。
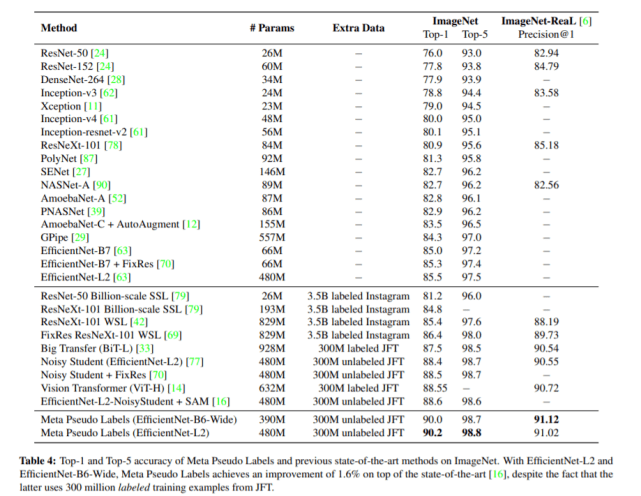
文章图片
推荐阅读







- 星链|石豪:在太空,马斯克和美国当局是如何作恶的
- 快报|“他,是能成就导师的学生”
- 区块|面向2030:影响数据存储产业的十大应用(下):新兴应用
- 年轻人|人生缺少的不是运气,而是少了这些高质量订阅号
- 生活|气笑了,这APP的年度报告是在嘲讽我吧
- bug|这款小工具让你的Win10用上“Win11亚克力半透明菜单”
- 苏宁|小门店里的暖心事,三位创业者的雪域坚守
- 历史|科普:詹姆斯·韦布空间望远镜——探索宇宙历史的“深空巨镜”
- 空间|(科技)科普:詹姆斯·韦布空间望远镜——探索宇宙历史的“深空巨镜”
- 生活|数字文旅的精彩生活