视觉|比MAE更强,FAIR新方法MaskFeat用HOG刷新多个SOTA
选自arXiv
作者:Chen Wei等
机器之心编译
mask-and-predict 的方法可能会成为计算机视觉领域的新流派 。自监督预训练在自然语言处理方面取得了惊人的成功 , 其基本思路中包含着掩码预测任务 。 前段时间 , 何恺明一作的论文《Masked Autoencoders Are Scalable Vision Learners》提出了一种简单实用的自监督学习方案 MAE , 将 NLP 领域的掩码预测(mask-and-predict)方法用在了视觉问题上 。 现在来自 Facebook AI 研究院(FAIR)的研究团队又提出了一种自监督视觉预训练新方法 MaskFeat 。

文章图片
论文地址:https://arxiv.org/pdf/2112.09133.pdf
MaskFeat 首先随机掩码一部分输入序列 , 然后预测被掩码区域的特征 。 通过研究 5 种不同类型的特征 , 研究者发现方向梯度直方图 (HOG) 是一种很好的特征描述方法 , 在性能和效率方面都表现优异 。 并且研究者还观察到 HOG 中的局部对比归一化对于获得良好结果至关重要 , 这与之前使用 HOG 进行视觉识别的工作一致 。
该方法可以学习丰富的视觉知识并驱动基于 Transformer 的大规模模型 。 在不使用额外的模型权重和监督的情况下 , MaskFeat 在未标记的视频上进行预训练 , 使用 MViT-L 在 Kinetics-400 上实现了前所未有的 86.7% top-1 准确率 。 此外 , MaskFeat 还能进一步推广到图像输入 , 并在 ImageNet 上获得了有竞争力的结果 。
方法
掩码视觉预测任务旨在修复被掩码的视觉内容 。 通过建模掩码样本 , 该模型从识别物体的部位和运动的意义上实现了视频理解 。 例如 , 要补全下图中的图像 , 模型必须首先根据可见区域识别对象 , 还要知道对象通常的形态和移动方式 , 以修复缺失区域 。

文章图片
该任务的一个关键组成部分是预测目标 。 在自然语言处理任务中 , 掩码语言建模使用词表 tokenize 语料库作为目标 。 而在视觉领域 , 原始视觉信号是连续的、高维的 , 并且没有可用的自然「词表」 。
因此 , MaskFeat 提出将预测被掩码区域的特征 。 借助从原始完整样本中提取的特征进行监督 。 目标特征的选择在很大程度上影响了预训练模型的属性 , 该研究对特征进行了广泛的解释 , 并主要考虑了 5 种不同类型的目标特征 。
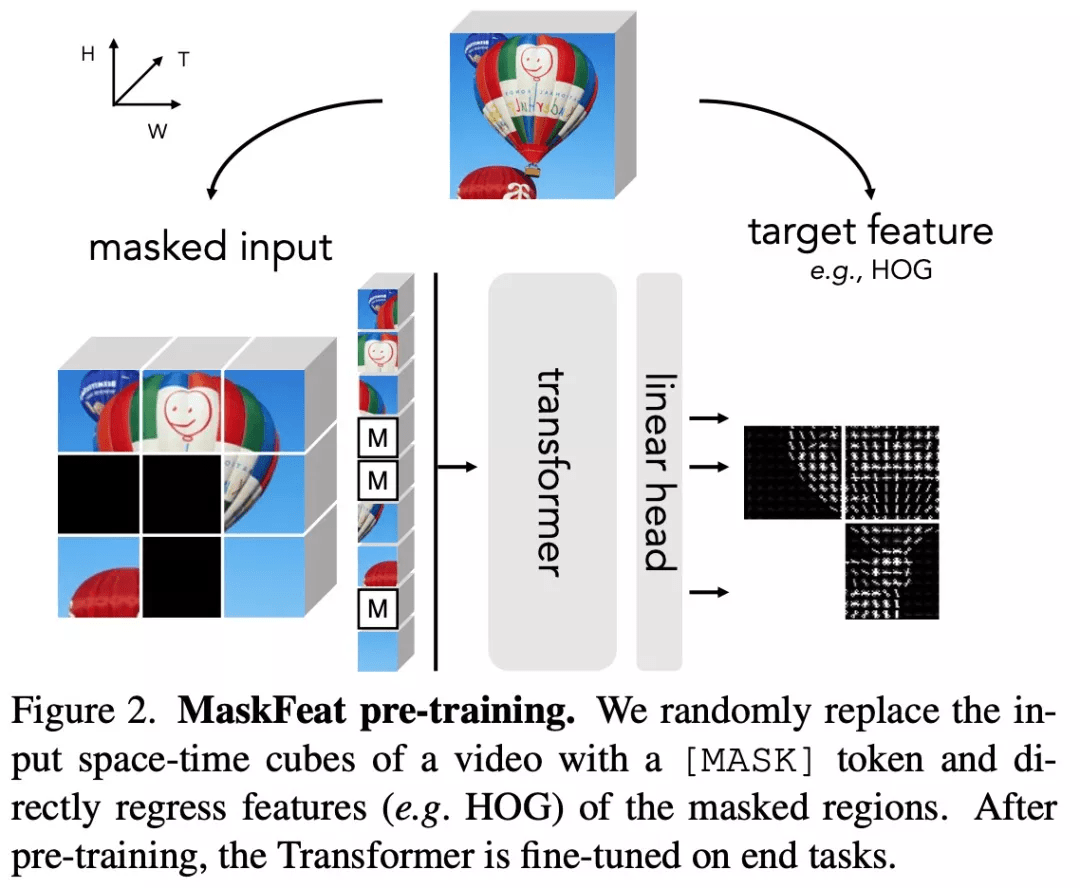
文章图片
首先研究者将目标特征分为两组:1) 可以直接获得的单阶段目标 , 包括像素颜色和 HOG;2) 由经过训练的深度网络提取的两阶段目标 。 由于预测两阶段目标是借助训练有素的深度网络有效学得的(类似于模型蒸馏) , 因此教师模型的预训练和推理的额外计算成本是不可避免的 。 该研究主要探究的 5 种特征类型是:
推荐阅读







- 新京报|工信部:2021年我国汽车整车出口同比增长一倍,创历史新高
- 安全|温州一超市遭“比特币勒索病毒”攻击,储值系统瘫痪
- IT|比雷克萨斯还豪华 丰田坦途顶级车型官图发布
- 财联社|比尔·盖茨谈疫情前景:奥密克戎后不太可能出现传染性更强的变种
- 国家|SA:未来 12 个月打算购买智能手表的消费者比例将达到两位数
- 杜比|联想拯救者 Y9000P 2022 款预热:可选 RTX 3070 Ti 150W 满功耗
- IT|新能源乘用车市“神仙打架”:特斯拉中国月交付破7万辆 比亚迪:我9万
- Check|2021 网络攻击同比增长 50%,Log4j 漏洞“功不可没”
- 硬件|首发176层QLC闪存 美光推出2400系列SSD:寿命比TLC短一半
- 苹果|iPhone 14 Pro与iPhone 13 Pro同框照曝光:新老外形对比强烈